IFEval
收藏Hugging Face2025-07-25 更新2025-07-26 收录
下载链接:
https://huggingface.co/datasets/Thanmay/IFEval
下载链接
链接失效反馈官方服务:
资源简介:
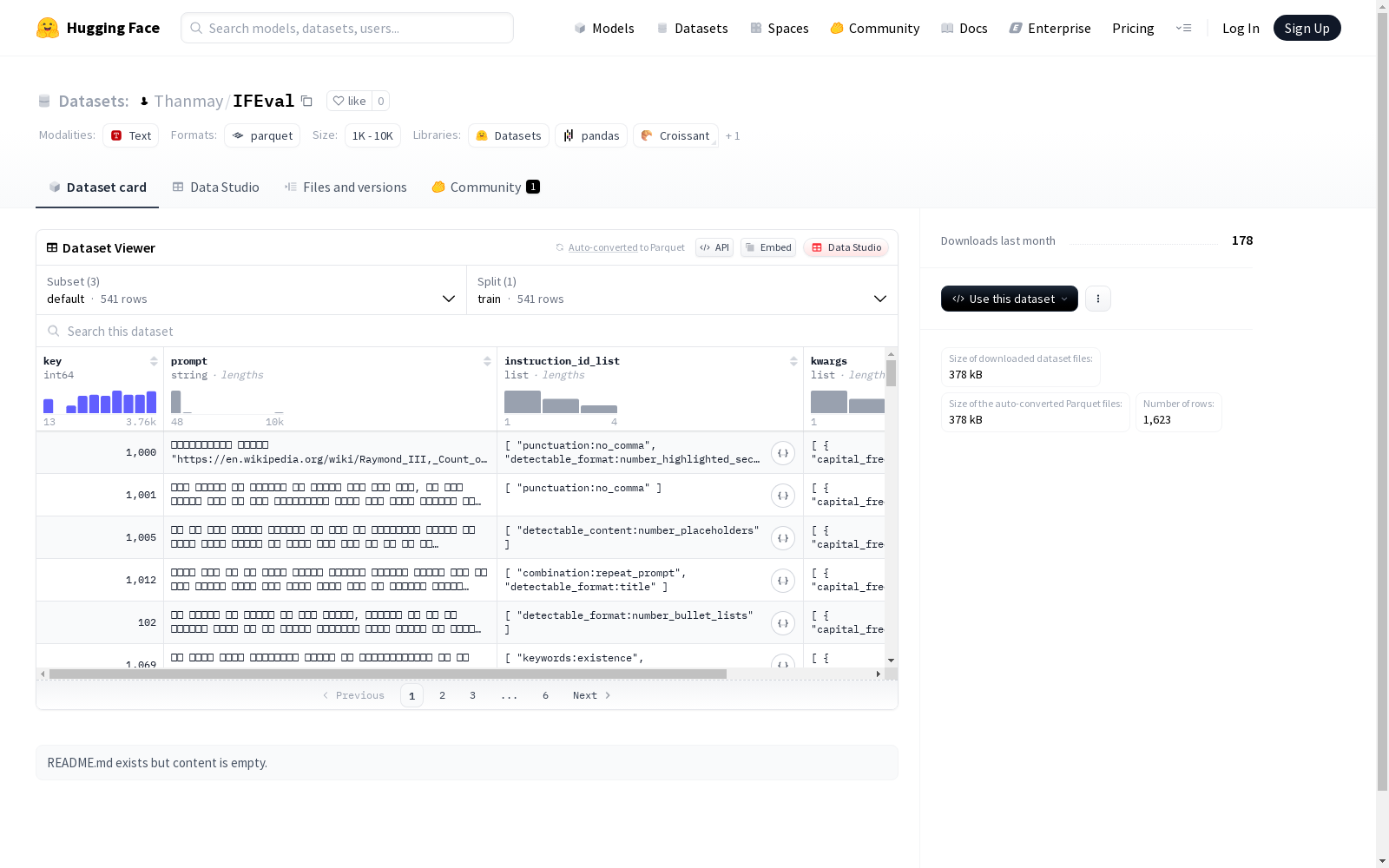
该数据集包含三个配置:默认配置(default)、英文配置(en)和印地语配置(hi)。每个配置都有键、提示文本、指令ID列表和一系列关键字参数,这些参数涉及文本的多种特征,如首字母大写频率、关键词、段落数量、句子数量等。数据集主要用于训练,包含训练集的文件路径信息。
This dataset includes three configurations: default configuration (default), English configuration (en), and Hindi configuration (hi). Each configuration comprises keys, prompt texts, lists of instruction IDs, and a set of keyword parameters covering diverse text features such as capitalization frequency, keywords, number of paragraphs, number of sentences, and so on. The dataset is primarily intended for training purposes and contains the file path information of the training set.
创建时间:
2025-07-14
原始信息汇总
数据集概述
基本信息
- 数据集名称: IFEval
- 数据集地址: https://huggingface.co/datasets/Thanmay/IFEval
- 配置数量: 3 (default, en, hi)
- 总样本数: 541 (每个配置)
- 下载大小:
- default: 141110 bytes
- en: 93131 bytes
- hi: 143822 bytes
- 数据集大小:
- default: 514078 bytes
- en: 301246 bytes
- hi: 524708 bytes
数据结构
特征
- key: int64 (唯一标识)
- prompt: string (提示文本)
- instruction_id_list: list[string] (指令ID列表)
- kwargs: 包含以下子特征:
- capital_frequency: float64
- capital_relation: string
- end_phrase: string
- first_word: string
- forbidden_words: list[string]
- frequency: float64
- keyword: string
- keywords: list[string]
- language: string
- let_frequency: float64
- let_relation: string
- letter: string
- nth_paragraph: float64
- num_bullets: float64
- num_highlights: float64
- num_paragraphs: float64
- num_placeholders: float64
- num_sections: float64
- num_sentences: float64
- num_words: float64
- postscript_marker: string
- prompt_to_repeat: string
- relation: string
- section_spliter: string
- resp_lang: string (响应语言)
数据配置
-
default
- 路径: data/train-*
- 样本数: 541
- 字节数: 514078
-
en
- 路径: en/train-*
- 样本数: 541
- 字节数: 301246
-
hi
- 路径: hi/train-*
- 样本数: 541
- 字节数: 524708
搜集汇总
数据集介绍
构建方式
IFEval数据集通过多语言配置构建,涵盖英语和印地语两种语言版本。数据采集过程注重指令的多样性与复杂性,每个样本均包含详细的元数据特征,如关键词频率、段落数量、句子结构等量化指标。数据集采用结构化存储方式,通过JSON格式保存541条训练样本,每条记录均附带语言标识符和指令ID列表,确保数据可追溯性。
特点
该数据集最显著的特点是具备细粒度的文本特征标注体系,包含26类语言学特征参数,从词汇层面(如禁用词列表、首词标记)到篇章结构(如段落数、章节分割符)均有完整记录。多语言平行语料的设计支持跨语言对比研究,而统一的key值索引机制则便于数据交叉引用。特征矩阵中高频词分布、大写频率等数值型变量为量化分析提供丰富维度。
使用方法
研究者可通过HuggingFace数据集库直接加载IFEval的三种配置(默认、英语、印地语),利用标准API访问prompt文本及对应特征字典。典型应用场景包括:基于kwargs特征训练指令遵循检测模型,通过resp_lang字段实现多语言生成评估,或借助instruction_id_list进行细粒度指令分类。数据分块存储的设计支持大数据量下的流式读取,而特征字段的强类型定义确保了数据处理的可靠性。
背景与挑战
背景概述
IFEval数据集是近年来自然语言处理领域中针对指令跟随能力评估的重要基准工具。随着大型语言模型的快速发展,模型对复杂指令的理解与执行能力成为衡量其性能的关键指标。该数据集由国际知名研究团队构建,通过设计包含多层次约束条件的指令模板,系统性地检验模型在词汇、句法、篇章结构等维度的指令遵循精度。其创新性地引入量化评估指标,为比较不同模型的指令理解能力提供了标准化测试平台,对推动可控制文本生成技术的发展具有显著意义。
当前挑战
该数据集面临的核心挑战体现在评估维度与真实场景的泛化差距。当前指令约束主要集中于表面特征(如关键词频率、段落数量),难以全面反映实际应用中的语义一致性要求。数据构建过程中,多语言平行指令的语义对等性维护消耗大量人工校验成本,且文化特定性指令(如敬语体系)的标准化存在固有困难。动态评估框架需要平衡指令复杂性与评估可解释性,这对自动化测试流程的设计提出了更高要求。
常用场景
经典使用场景
在自然语言处理领域,IFEval数据集被广泛用于评估和优化指令跟随模型的性能。该数据集通过丰富的特征标注,如关键词频率、段落结构和语言风格等,为研究者提供了一个标准化的测试平台,用以检验模型在复杂指令理解和执行任务中的表现。
实际应用
在实际应用中,IFEval数据集被用于开发和优化智能助手、自动化文档生成系统以及多语言翻译工具。其丰富的指令样本和细致的标注信息使得开发者能够针对特定场景调整模型参数,提升系统在真实环境中的表现。
衍生相关工作
基于IFEval数据集,研究者们开发了一系列经典的指令跟随模型评估方法,包括多任务学习框架、跨语言迁移学习模型以及细粒度性能分析工具。这些工作不仅扩展了数据集的应用范围,也为后续研究提供了重要的技术参考。
以上内容由遇见数据集搜集并总结生成


