OBLI_QA-generation-workshop
收藏Hugging Face2024-12-20 更新2024-12-21 收录
下载链接:
https://huggingface.co/datasets/ylkhayat/OBLI_QA-generation-workshop
下载链接
链接失效反馈官方服务:
资源简介:
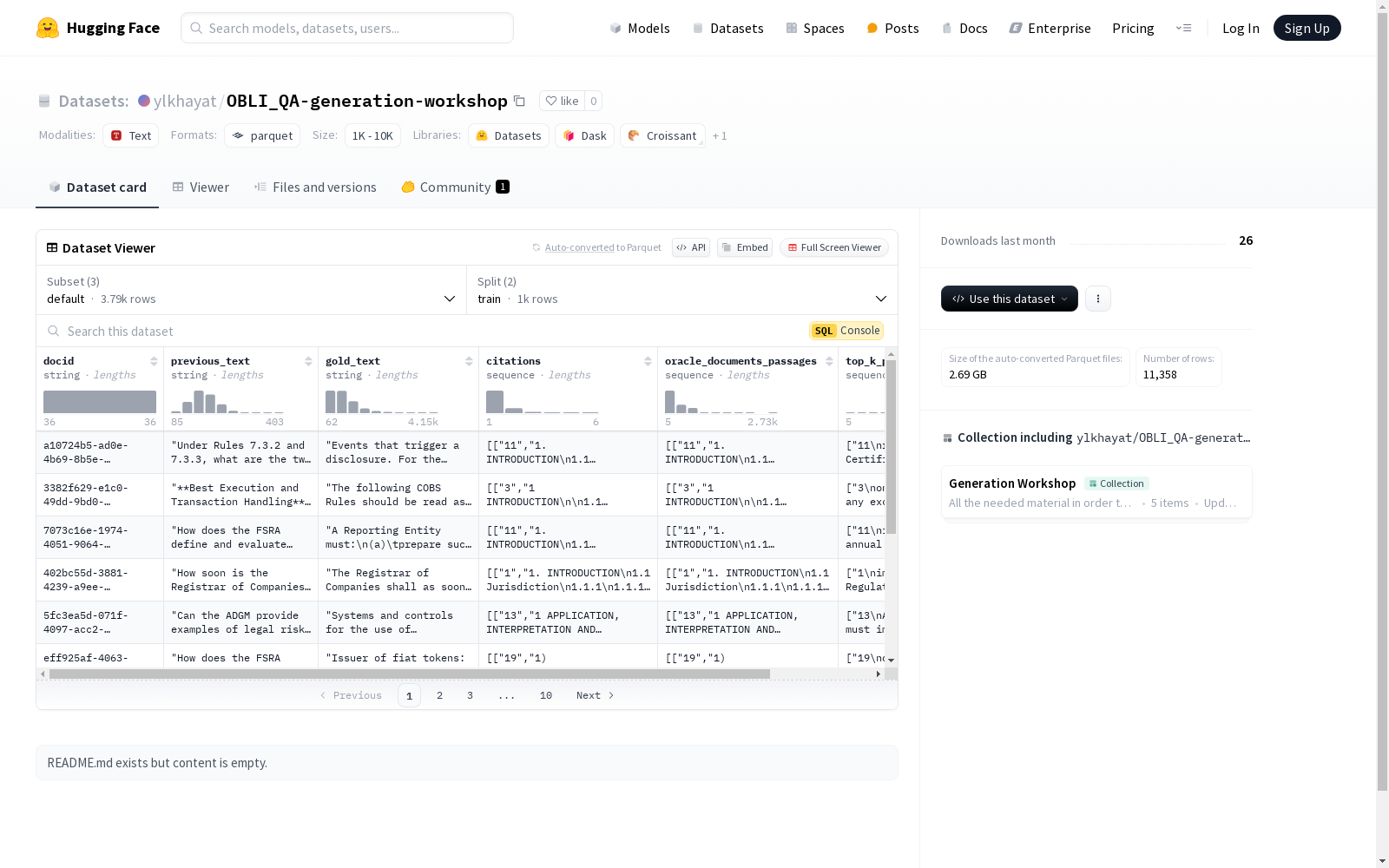
该数据集包含多个特征,如文档ID(docid)、前文(previous_text)、标准文本(gold_text)、引用(citations)、预言文档段落(oracle_documents_passages)和前K个段落(top_k_passages)。数据集分为训练集和测试集,分别包含1000和2786个样本。数据集的下载大小为991739266字节,总大小为4232045986字节。数据集的配置名为'default',包含训练和测试数据文件的路径。
This dataset contains multiple features, such as document ID (docid), previous_text, gold_text, citations, oracle_documents_passages, and top_k_passages. It is split into a training set and a test set, which hold 1000 and 2786 samples respectively. The download size of the dataset is 991739266 bytes, and the total size is 4232045986 bytes. The configuration of the dataset is named 'default', which includes the file paths for the training and test data.
创建时间:
2024-12-18
原始信息汇总
数据集概述
数据集信息
-
特征:
docid: 字符串类型previous_text: 字符串类型gold_text: 字符串类型citations: 字符串序列类型oracle_documents_passages: 字符串序列类型top_k_passages: 字符串序列类型
-
数据集划分:
train: 包含1000个样本,大小为1130260941字节test: 包含2786个样本,大小为3038220249字节
-
数据集大小:
- 下载大小: 968730904字节
- 数据集总大小: 4168481190字节
配置信息
-
BRPOD:
train: bm25_relevant_passages_oracle_documents/train-*test: bm25_relevant_passages_oracle_documents/test-*
-
DRPOD:
train: dense_relevant_passages_oracle_documents/sentence-transformers_all-MiniLM-L6-v2/train-*test: dense_relevant_passages_oracle_documents/sentence-transformers_all-MiniLM-L6-v2/test-*
-
default:
train: dense_relevant_passages_oracle_documents/sentence-transformers_all-MiniLM-L6-v2/train-*test: dense_relevant_passages_oracle_documents/sentence-transformers_all-MiniLM-L6-v2/test-*
搜集汇总
数据集介绍
构建方式
OBLI_QA-generation-workshop数据集的构建基于文档检索和问答生成的结合,通过整合多种检索技术,如BM25和密集检索(Dense Retrieval),从大规模文档库中提取相关段落。数据集中的每个样本包含文档ID、前文文本、黄金标准文本、引用信息、以及通过不同检索方法获取的文档段落。训练和测试数据分别从不同的检索结果中抽取,确保了数据集的多样性和覆盖性。
特点
该数据集的显著特点在于其多样的检索方法和丰富的上下文信息。通过包含BM25和密集检索两种不同的检索策略,数据集能够支持多种问答生成模型的训练和评估。此外,每个样本中的引用信息和黄金标准文本为模型的训练提供了高质量的监督信号,有助于提升问答生成的准确性和相关性。
使用方法
OBLI_QA-generation-workshop数据集适用于问答生成模型的训练和评估。用户可以选择不同的配置(如BRPOD和DRPOD)来加载数据,并根据需要调整检索策略。数据集的结构设计使得用户可以轻松地进行模型训练和测试,同时通过引用信息和黄金标准文本,用户可以进一步优化模型的性能。
背景与挑战
背景概述
OBLI_QA-generation-workshop数据集由相关领域的研究人员创建,旨在推动问答生成技术的发展。该数据集的核心研究问题是如何从给定的文档中自动生成高质量的问答对,这对于提升信息检索和自然语言处理的效率具有重要意义。数据集包含了多个特征,如文档ID、前文文本、标准答案文本、引用信息以及相关文档段落等,这些特征为研究者提供了丰富的资源,以探索和优化问答生成模型。通过提供训练和测试数据,该数据集为研究人员提供了一个标准化的评估平台,有助于推动该领域的技术进步。
当前挑战
OBLI_QA-generation-workshop数据集在构建和应用过程中面临多项挑战。首先,如何从海量文档中高效地提取相关段落并生成准确的问答对是一个技术难点,这涉及到复杂的文本匹配和信息抽取技术。其次,数据集的构建过程中需要确保问答对的准确性和多样性,以避免模型训练中的偏差。此外,如何处理不同类型的文档和文本结构,以及如何在有限的标注数据下实现高效的模型训练,也是该数据集面临的重要挑战。这些挑战不仅影响数据集的质量,也对后续的模型开发和应用提出了更高的要求。
常用场景
经典使用场景
OBLI_QA-generation-workshop数据集主要用于问答生成任务,特别是在自然语言处理领域中,研究者可以利用该数据集训练模型,使其能够根据给定的文档片段生成准确且相关的答案。通过提供上下文信息(previous_text)和标准答案(gold_text),该数据集为模型提供了丰富的训练材料,使其能够在复杂的文本环境中准确提取和生成信息。
解决学术问题
该数据集解决了自然语言处理中问答生成模型的训练数据不足问题,尤其是在多文档环境下如何生成准确答案的挑战。通过提供包含上下文、标准答案和相关文档片段的数据,OBLI_QA-generation-workshop为研究者提供了一个标准化的测试平台,推动了问答生成技术的发展,并有助于提升模型在实际应用中的表现。
衍生相关工作
基于OBLI_QA-generation-workshop数据集,研究者们开发了多种问答生成模型,如基于BERT的问答系统、多文档问答模型等。这些模型在多个基准测试中表现优异,进一步推动了问答生成技术的发展。此外,该数据集还激发了对多文档环境下信息检索和文本生成技术的深入研究,促进了相关领域的技术进步。
以上内容由遇见数据集搜集并总结生成


