keyphrases_updated
收藏Hugging Face2024-11-27 更新2024-12-12 收录
下载链接:
https://huggingface.co/datasets/ClovenDoug/keyphrases_updated
下载链接
链接失效反馈官方服务:
资源简介:
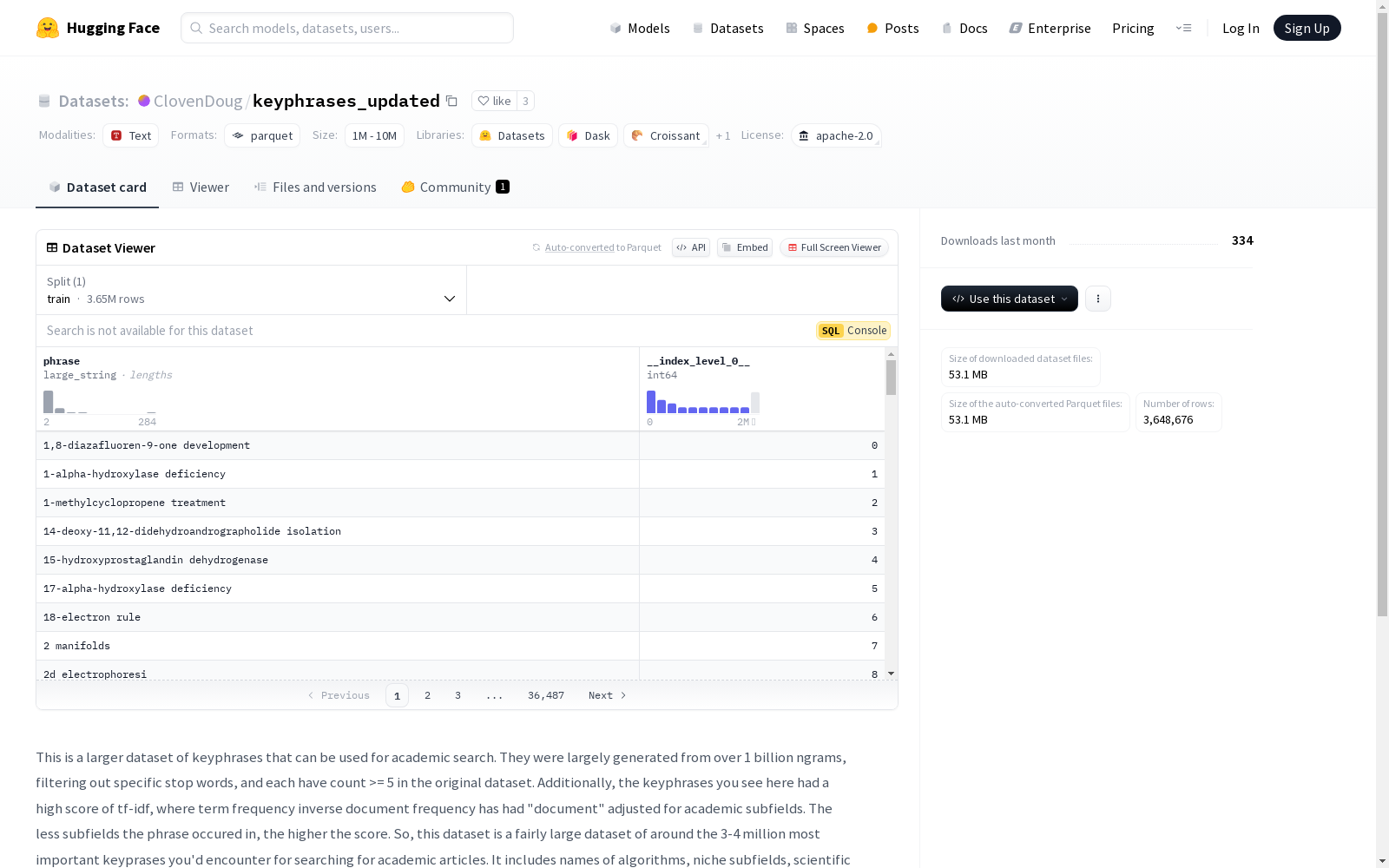
该数据集是一个较大的关键词短语集合,主要用于学术搜索。这些关键词短语主要从超过10亿个ngrams中生成,经过特定停用词的过滤,并且在原始数据集中每个短语的计数至少为5。此外,这些关键词短语具有较高的tf-idf分数,其中术语频率逆文档频率的“文档”已针对学术子领域进行了调整。短语出现的子领域越少,分数越高。因此,该数据集包含了大约3-4百万个最重要的关键词短语,适用于搜索学术文章。数据集包括算法名称、特定子领域、科学概念、疾病等。数据集分为不同长度的短语:单字短语(Unigrams)有142,690个唯一短语,双字短语(Bigrams)有378,041个唯一短语,三字短语(Trigrams)有2,444,002个唯一短语,四字短语(Fourgrams)有711,771个唯一短语。
This dataset is a large collection of keyword phrases primarily utilized for academic search. These keyword phrases are generated from over 1 billion ngrams, filtered with specific stop words, and each phrase has a count of at least 5 in the original dataset. Furthermore, these keyword phrases feature relatively high TF-IDF scores, where the 'document' unit for term frequency-inverse document frequency (TF-IDF) has been adjusted for academic subfields. The fewer academic subfields a phrase appears in, the higher its score. Thus, this dataset contains approximately 3 to 4 million of the most critical keyword phrases suitable for academic article search. The dataset encompasses algorithm names, specific academic subfields, scientific concepts, diseases, and other relevant categories. The dataset is categorized by phrase length: there are 142,690 unique unigrams, 378,041 unique bigrams, 2,444,002 unique trigrams, and 711,771 unique fourgrams.
创建时间:
2024-11-27
原始信息汇总
数据集概述
数据集名称
- keyphrases_updated
数据集描述
- 该数据集包含大量关键短语,适用于学术搜索。
- 数据集中的关键短语主要从超过10亿个ngrams中生成,经过特定停用词过滤,且在原始数据集中出现次数不少于5次。
- 关键短语的tf-idf得分较高,其中“文档”已根据学术子领域进行调整。
- 短语在越少的子领域中出现,得分越高。
- 数据集包含约3-4百万个最重要的关键短语,涵盖算法名称、细分领域、科学概念、疾病等。
数据集规模
- Unigrams: 103,314个唯一短语
- Bigrams: 378,041个唯一短语
- Trigrams: 2,444,002个唯一短语
- Fourgrams: 711,771个唯一短语
许可证
- Apache 2.0
搜集汇总
数据集介绍
构建方式
keyphrases_updated数据集构建于超过10亿个n-gram的基础之上,通过过滤特定停用词并保留原始数据集中出现次数≥5的关键短语。进一步地,这些关键短语基于调整后的tf-idf评分进行筛选,其中‘文档’被调整为学术子领域。短语在越少的子领域中出现,其评分越高。最终,该数据集包含了约300万至400万条在学术文章搜索中最为重要的关键短语。
特点
keyphrases_updated数据集涵盖了算法名称、小众子领域、科学概念、疾病等多种学术关键词,具有广泛的学术代表性。数据集包含103,314个单字短语、378,041个双字短语、2,444,002个三字短语以及711,771个四字短语,总计超过300万条关键短语,为学术搜索提供了丰富的词汇资源。
使用方法
keyphrases_updated数据集适用于学术搜索引擎的构建与优化,用户可通过该数据集提升搜索结果的准确性与相关性。研究人员可利用这些关键短语进行文本挖掘、信息检索等任务,进一步推动学术研究的发展。数据集可直接下载并集成到现有系统中,支持多种编程语言和工具的使用。
背景与挑战
背景概述
keyphrases_updated数据集是一个专为学术搜索设计的大规模关键词短语数据集,其构建基于超过10亿个n-gram的筛选与优化。该数据集由Apache 2.0许可证发布,旨在为学术文献的检索提供高效的关键词支持。通过剔除特定停用词并保留原始数据集中出现次数大于等于5的短语,研究人员进一步利用调整后的TF-IDF(词频-逆文档频率)算法对短语进行评分,确保其在特定学术子领域中的重要性。数据集中包含约300万至400万条关键短语,涵盖算法名称、细分领域、科学概念、疾病等多个类别,为学术搜索提供了丰富的语义资源。
当前挑战
keyphrases_updated数据集在构建与应用过程中面临多重挑战。首先,学术领域的多样性与复杂性使得关键词的筛选与评分需要高度精确,以确保其在特定子领域中的代表性。其次,数据集的规模庞大,如何高效处理超过10亿个n-gram并从中提取高质量短语,对计算资源与算法优化提出了极高要求。此外,TF-IDF算法的调整虽提升了短语的区分度,但也可能导致某些跨领域重要短语的遗漏。最后,数据集的动态更新与维护需要持续投入,以适应学术领域的快速演变与新术语的涌现。
常用场景
经典使用场景
在学术研究领域,keyphrases_updated数据集被广泛应用于文献检索和知识发现。通过其包含的数百万个关键短语,研究人员能够更精确地定位相关学术文章,尤其是在跨学科研究中,该数据集的高质量关键短语显著提升了检索效率和准确性。
解决学术问题
该数据集解决了学术检索中关键词选择不精准的问题。通过基于tf-idf算法优化的关键短语,它能够有效区分不同学术子领域的术语,帮助研究人员快速识别高相关性的文献,从而提升学术研究的效率和质量。
衍生相关工作
基于keyphrases_updated数据集,许多经典的研究工作得以展开。例如,一些研究团队利用该数据集开发了更先进的学术推荐系统,能够根据用户的检索历史和研究兴趣,自动推荐相关文献和关键词,进一步推动了学术信息检索技术的发展。
以上内容由遇见数据集搜集并总结生成


