mmarco-corpus-queries-mini
收藏Hugging Face2025-04-17 更新2025-04-18 收录
下载链接:
https://huggingface.co/datasets/antonioloison/mmarco-corpus-queries-mini
下载链接
链接失效反馈官方服务:
资源简介:
该数据集包含德语、英语、西班牙语、法语和意大利语五种语言的语料库和查询数据。语料库数据集包含文本id、文本内容和语言类型等信息,而查询数据集则包含查询内容、正负样本id、语言类型、查询的翻译以及翻译所用的语言等信息。每个语言都有对应的训练集,部分语言还包括测试集。
This dataset contains corpus and query data in five languages: German, English, Spanish, French and Italian. The corpus dataset includes information such as text ID, text content and language type, while the query dataset contains query content, positive and negative sample IDs, language type, the translated query, and the language used for the translation. Each language has a corresponding training set, and some languages also include a test set.
创建时间:
2025-04-15
搜集汇总
数据集介绍
构建方式
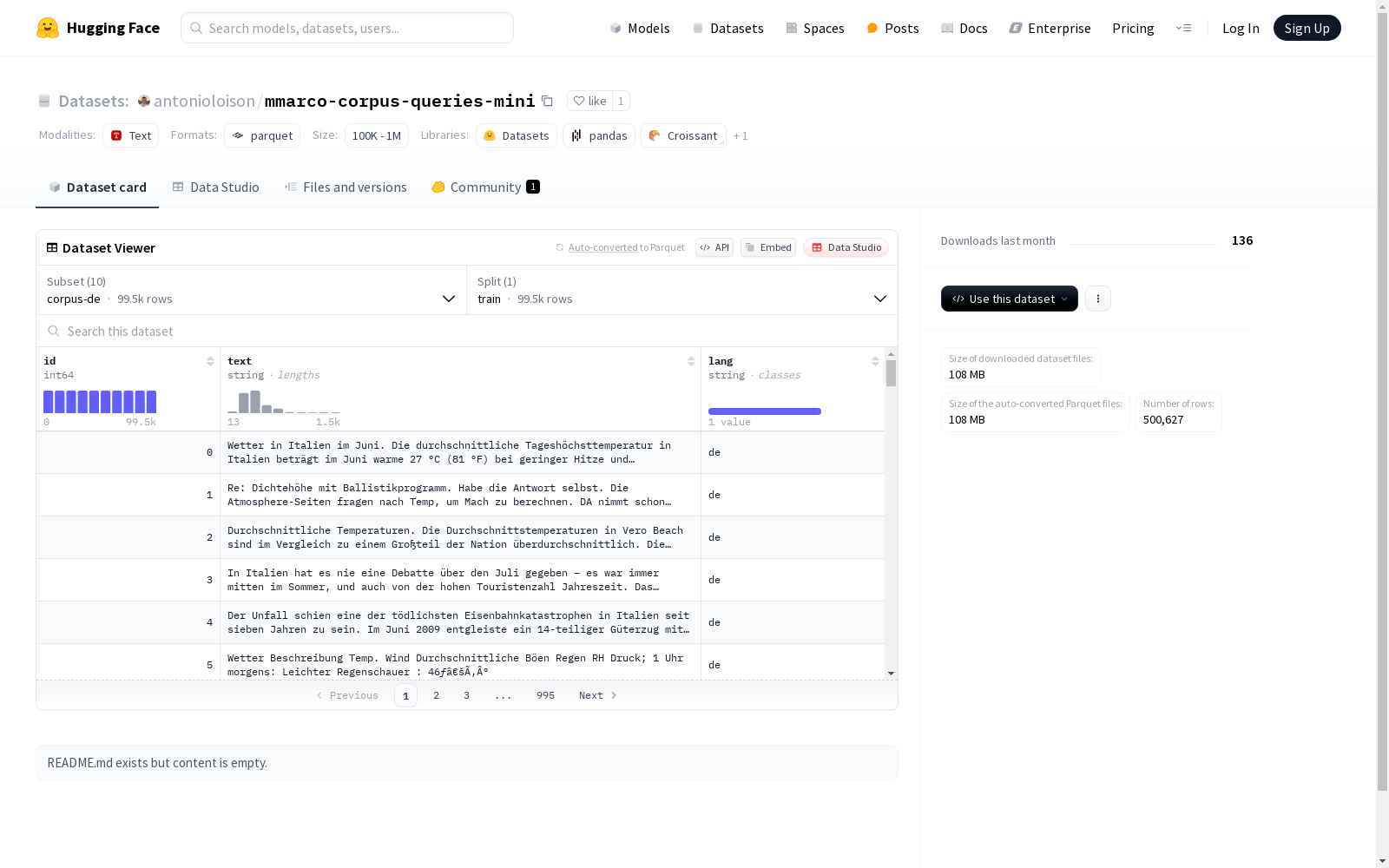
mmarco-corpus-queries-mini数据集构建于多语言信息检索领域,采用结构化数据采集方法,涵盖德语、英语、西班牙语、法语和意大利语五种语言。该数据集通过精心设计的语料库和查询模块组成,其中语料库部分包含近十万条文本数据,每条数据均标注唯一ID和语言标识;查询模块则包含训练集和测试集,每类语言配置1000条训练查询和500条测试查询,并附带正负相关段落索引及多语言翻译版本。数据采集过程注重语言多样性和内容覆盖度,为跨语言检索研究提供标准化基准。
特点
该数据集最显著的特征在于其多语言平行架构,五种语言的语料库规模均衡,德语、英语等各语种文本量均保持在9万至10万条之间。查询模块创新性地整合了翻译对照体系,每条查询配备多语言译文及对应语言标签,支持跨语言检索任务的端到端训练。数据字段设计科学严谨,语料库包含文本内容和语言元数据,查询模块则细化到正负段落关联、翻译文本等维度,这种多层次标注体系极大提升了数据集的科研应用价值。
使用方法
研究者可通过HuggingFace数据集库直接加载特定语言配置,如corpus-de或queries-fr等模块。语料库数据适用于无监督预训练或稠密检索模型构建,而带有标注的查询模块则适合监督式学习。测试集设计为500条标准查询,可用于模型性能评估。数据加载后可通过lang字段实现多语言混合训练,或利用translated_queries字段开展跨语言迁移学习实验。该数据集接口兼容主流机器学习框架,支持流式读取以处理大规模数据。
背景与挑战
背景概述
mmarco-corpus-queries-mini数据集是多语言信息检索领域的重要资源,由微软研究团队于近年来推出,旨在为跨语言检索任务提供标准化评估基准。该数据集涵盖德语、英语、西班牙语、法语和意大利语五种语言,包含大量查询语句及其对应的正负相关文档段落。其核心研究问题聚焦于解决多语言环境下语义匹配的复杂性,为机器阅读理解、跨语言检索等自然语言处理任务提供了关键数据支持。该数据集的构建显著推动了多语言检索模型的性能提升,成为该领域研究的重要参考标准。
当前挑战
该数据集面临的挑战主要体现在两方面:领域问题层面,多语言查询与文档的语义对齐存在显著难度,不同语言间的文化差异和表达习惯增加了模型理解准确性的要求;构建过程层面,高质量的多语言语料收集与标注需要耗费大量人力,确保正负样本的平衡性与代表性亦需严谨设计。此外,翻译查询的语义一致性维护及小语种数据稀缺性,进一步增加了数据集构建的复杂度。
常用场景
经典使用场景
在信息检索领域,mmarco-corpus-queries-mini数据集被广泛用于训练和评估多语言检索模型。该数据集包含英语、德语、西班牙语、法语和意大利语的查询和相关文档,为研究者提供了一个标准化的测试平台。通过使用该数据集,研究者能够验证模型在不同语言环境下的检索性能,从而推动跨语言信息检索技术的发展。
解决学术问题
mmarco-corpus-queries-mini数据集解决了多语言信息检索中的关键问题,如语言障碍和跨语言相关性匹配。该数据集通过提供多种语言的查询和相关文档,帮助研究者开发能够处理多语言内容的检索模型。这不仅提升了模型的语言适应性,还为跨语言信息检索的学术研究提供了可靠的数据支持。
衍生相关工作
基于mmarco-corpus-queries-mini数据集,研究者们开发了多种多语言检索模型和跨语言嵌入方法。例如,一些经典工作利用该数据集训练了基于Transformer的检索模型,显著提升了多语言环境下的检索准确率。此外,该数据集还催生了一系列关于跨语言信息检索的学术论文和技术报告,推动了该领域的快速发展。
以上内容由遇见数据集搜集并总结生成


