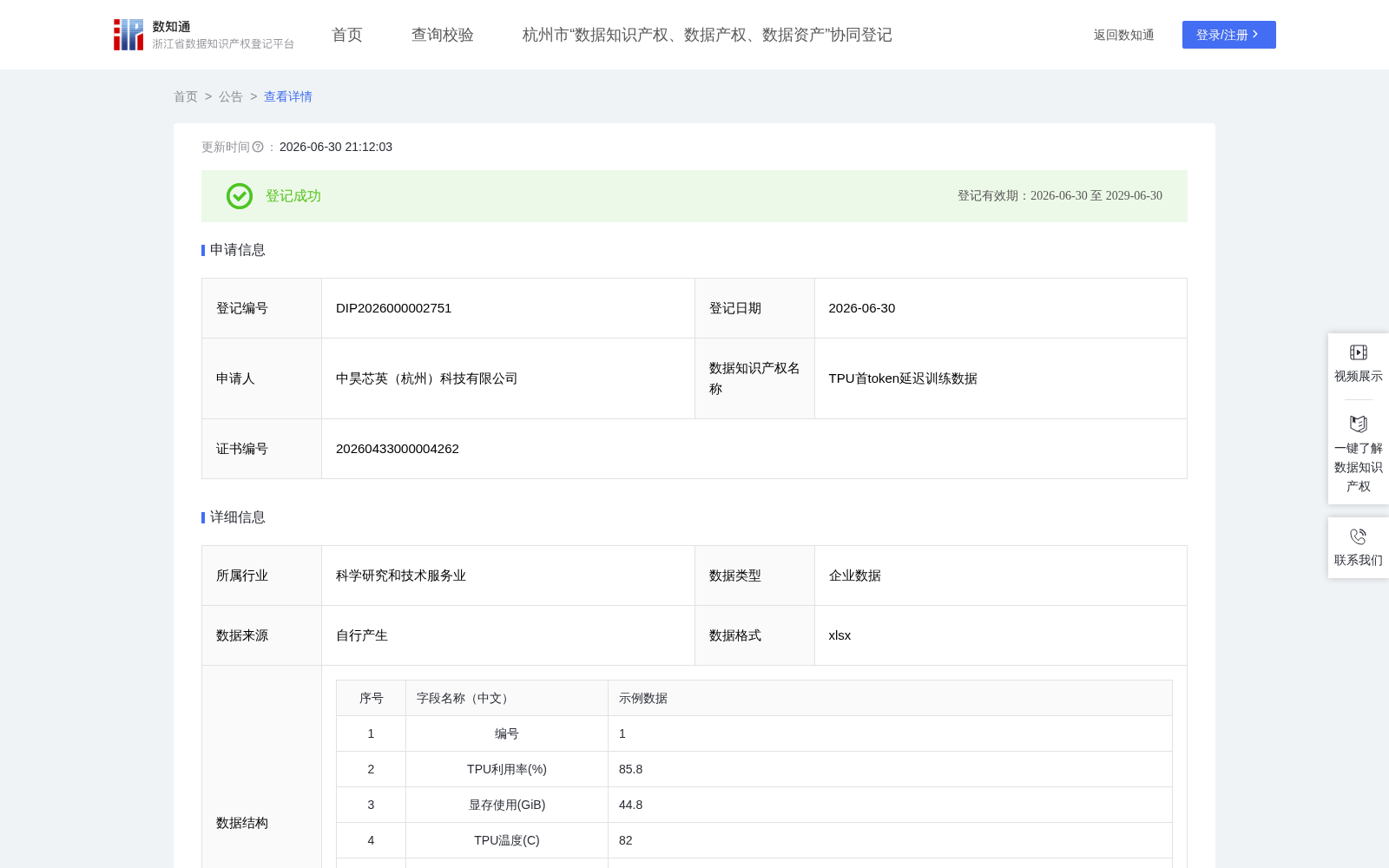
TPU首token延迟训练数据
收藏浙江省数据知识产权登记平台2026-06-30 更新2026-07-01 收录
下载链接:
https://www.zjip.org.cn/home/announce/trends/8455400
下载链接
链接失效反馈官方服务:
资源简介:
本数据用于训练回归模型,根据TPU实时状态(利用率、显存使用、温度、功率、请求排队长度、显存带宽利用率)预测首token延迟。在实际大语言模型(LLM)在线推理服务中,首token延迟直接影响用户等待的第一印象,是服务质量的关键指标。
通过本数据集训练的模型,能够:帮助云服务商:实时监控TPU负载与排队情况,提前预测首token延迟是否即将超过服务等级协议(SLA)阈值(如50ms),并据此触发动态扩容、请求限流或优先级调度,避免因响应过慢导致用户流失。帮助AI芯片厂商:分析不同负载条件下首token延迟与硬件状态(温度、功率、带宽利用率)的关联,定位性能瓶颈是计算、访存还是热节流,为芯片调度策略优化提供数据支撑。帮助模型部署工程师:在离线仿真环境中评估排队策略、并发上限对首token延迟的影响,提前优化系统参数。1. 加工前的原始数据
原始数据为TPU运行大语言模型在线推理服务的状态监控日志,每行对应一个请求时刻。字段包括:编号、TPU利用率(%)、显存使用(GiB)、TPU温度(℃)、TPU功率(W)、请求排队长度、显存带宽利用率(%)、首token延迟(ms)。所有字段均为数值型且无缺失值,数据总量达数千行以上,覆盖不同负载强度、排队长度及热状态。
2. 处理规则
数据清洗:剔除超出物理合理范围的记录(如负值、超过硬件极限的值),删除所有字段完全相同的重复记录。
特征与目标定义:自变量为TPU利用率、显存使用、TPU温度、TPU功率、请求排队长度、显存带宽利用率(共6个);因变量为首token延迟。
特征标准化:对全部自变量进行Z-score标准化,消除量纲影响。标准化参数(均值、标准差)由训练集计算,并应用于验证集和测试集。
数据集划分:将清洗后的完整数据按8:1:1的比例随机划分为训练集、验证集和测试集,保证三部分数据分布一致。
模型验证:基于随机森林回归算法(输入6个自变量,输出首token延迟),通过网格搜索优化超参数(树数量、最大深度等)。特征重要性分析表明,请求排队长度和TPU利用率是影响首token延迟的主要因素。模型在测试集上达到R² > 0.86,训练集与测试集误差差异小于6%,无过拟合迹象,证明数据集的有效性。
3. 数据内容描述
最终产出数据集为表格形式,包含编号、6个自变量、1个因变量,共8个字段。所有记录均来自真实TPU推理环境,覆盖完整工况范围。数据已标准化并按8:1:1划分,可直接用于监督学习回归任务,训练首token延迟预测模型。
提供机构:
中昊芯英(杭州)科技有限公司
创建时间:
2026-04-17
搜集汇总
数据集介绍
背景与挑战
背景概述
该数据集包含5005条来自真实TPU推理环境的监控记录,以TPU利用率、显存使用、温度、功率、请求排队长度及显存带宽利用率为自变量,预测首token延迟这一关键服务质量指标。数据经清洗、Z-score标准化并按8:1:1划分为训练、验证和测试集,可直接用于回归建模。基于随机森林的验证表明,请求排队长度与TPU利用率是影响延迟的主要因素,模型R²超过0.86且无过拟合,能有效支持SLA预警、芯片性能分析及部署参数优化。
以上内容由遇见数据集搜集并总结生成


