shamela_books_text_full
收藏Hugging Face2025-08-01 更新2025-08-02 收录
下载链接:
https://huggingface.co/datasets/MoMonir/shamela_books_text_full
下载链接
链接失效反馈官方服务:
资源简介:
Shamela Books Text数据集包含了来自Shamela Library的完整伊斯兰阿拉伯书籍文本,按照类别、书籍、卷和页进行分类,并单独存储脚注。该数据集旨在支持阿拉伯自然语言处理、数字人文研究和书目分析。
The Shamela Books Text Dataset contains full Arabic texts of Islamic books sourced from the Shamela Library. The texts are categorized by category, book, volume and page, with footnotes stored separately. This dataset is designed to support Arabic natural language processing, digital humanities research and bibliographic analysis.
创建时间:
2025-07-30
原始信息汇总
Shamela_Books_Text_Full 数据集概述
📌 数据集简介
- 来源:伊斯兰阿拉伯书籍的全文内容,来自Shamela Library。
- 设计目的:支持阿拉伯自然语言处理(NLP)、数字人文和书目分析。
- 关联数据集:Shamela_Books_info,通过
book_id字段关联。
📊 数据集统计
- 总类别数:40
- 总书籍数:8,538
- 总记录数(页数):7,552,019
- 粒度:每行代表一本书的一页
- 脚注:存储在单独的列中以便于处理
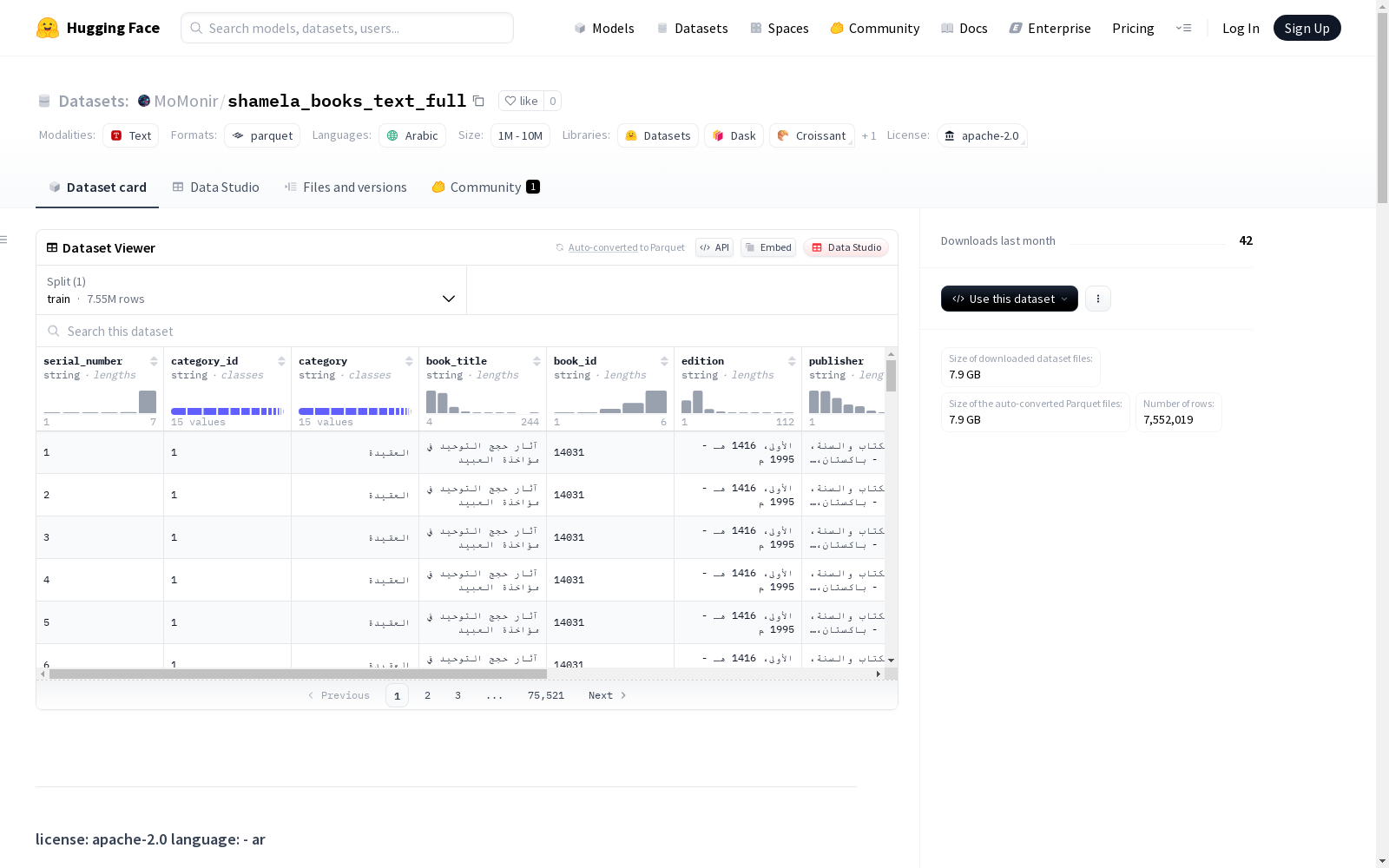
📁 数据集字段
| 字段名 | 描述 |
|---|---|
serial_number |
每页的唯一行ID |
category_id |
书籍类别的数字标识符 |
category |
类别名称(如Fiqh、Tafsir等) |
book_title |
书籍标题 |
book_id |
Shamela.ws使用的唯一ID |
edition |
版本信息(如可用) |
publisher |
出版商名称(如可用) |
page_number |
卷内的页码 |
volume_number |
卷号(支持子部分和前缀) |
text |
页面的主要内容文本 |
foot_note |
同一页的脚注文本 |
🔗 元数据链接
通过book_id字段可以关联到元数据集:Shamela_Books_info,以获取完整的作者信息、出版详情和分类。
📚 卷号参考
| 示例模式 | 描述 | 卷号 |
|---|---|---|
5 أ, 5 ب |
阿拉伯字母多部分(أ = 1) | 5.2, 5.1 |
2- 1 |
连字符部分 | 2.1 |
47 - 48 |
多卷,使用第一个数字 | 47 |
001, 1 |
标准数字卷 | 1 |
🧠 使用建议
- 训练/微调阿拉伯语言模型
- 信息检索/文档分割
- 数字伊斯兰研究/文学分析
- 将文本与作者、死亡年份、类别和编辑关联
📅 免责声明
该数据集基于Shamela Library software在2025年6月同步的导出数据。请注意,Shamela Library可能会随时添加或删除条目,此数据集可能不反映未来的更新。
📖 引用
如果使用此数据集,请引用为:
@dataset{shamela_books_text, title = {Shamela Books Text}, author = {MoMonir}, year = {2025}, url = {https://huggingface.co/datasets/MoMonir/shamela_books_text} }
搜集汇总
数据集介绍
构建方式
该数据集源自伊斯兰阿拉伯语书籍的数字化工程,通过系统化采集Shamela图书馆(http://shamela.ws)的完整文本内容构建而成。数据以页面为基本单元进行结构化存储,每条记录对应书籍的特定页面,并精细标注了类别编号、书籍标题、版本信息等元数据。构建过程中特别设计了脚注分离存储机制,确保正文内容与注释信息的独立性,便于后续分析处理。
使用方法
研究者可通过HuggingFace平台直接加载数据集,利用Python生态工具进行深度挖掘。典型应用包括阿拉伯语NLP模型训练、伊斯兰文献知识图谱构建等。数据集中分离存储的脚注内容特别适合跨页注释放射研究,而标准化的卷册编号体系则支持复杂的文献结构分析。建议结合配套的Shamela_Books_info元数据集,通过book_id字段进行关联查询,可获取作者、出版年代等扩展维度信息。
背景与挑战
背景概述
Shamela_Books_Text_Full数据集是一个专注于伊斯兰阿拉伯语书籍全文内容的大规模文本数据集,源自著名的Shamela图书馆。该数据集由MoMonir团队于2025年构建,旨在为阿拉伯语自然语言处理、数字人文和文献分析提供高质量的研究资源。数据集涵盖了8538本伊斯兰经典著作,包含755万页文本内容,并按类别、书籍、卷册和页码进行系统化组织。其独特的学术价值在于将阿拉伯语古籍的数字化版本与结构化元数据相结合,为伊斯兰文化传承、阿拉伯语语言模型训练以及跨学科研究提供了重要基础。
当前挑战
该数据集面临的核心挑战主要体现在领域问题和构建过程两个维度。在领域问题方面,阿拉伯语古籍文本具有复杂的形态学特征和独特的书写系统,这对文本预处理、分词和语义理解提出了极高要求。同时,伊斯兰文献中大量存在的专业术语和古典表达方式,为自然语言处理模型的适应性带来挑战。在构建过程中,数据集的创建者需要解决原始文本中存在的非标准化卷册编号、页面缺失以及注释与正文混合等数据质量问题。此外,保持与不断更新的Shamela图书馆数据同步,确保数据集版本的时效性,也是持续维护中的技术难点。
常用场景
经典使用场景
在阿拉伯语自然语言处理研究中,shamela_books_text_full数据集为学者们提供了丰富的伊斯兰文献全文内容。其经典使用场景包括训练和微调阿拉伯语语言模型,特别是在处理古典阿拉伯语文本时,该数据集能够提供充足的语料支持。通过细致的页面级标注和分类信息,研究者可以深入探索特定领域的语言特征和文本结构。
解决学术问题
该数据集有效解决了阿拉伯语NLP领域缺乏大规模、高质量古典文本语料的难题。其细粒度的分类体系(如教法学、经注学等)支持领域特定的语言学研究,而独立的脚注列则为文本注释分析提供了便利。在数字人文领域,它使得基于内容的伊斯兰文献计量分析成为可能,填补了该语种学术资源的空白。
实际应用
在实际应用中,该数据集支撑了伊斯兰数字图书馆的检索系统开发,通过对8,538部著作的全文索引,实现了精准的内容检索。教育机构利用其构建阿拉伯语教学资源,而文化保护组织则借助其进行文献数字化保存。出版行业参考其中的版本信息,用于古籍校勘和再版工作。
数据集最近研究
最新研究方向
近年来,随着阿拉伯语自然语言处理技术的迅猛发展,shamela_books_text_full数据集在伊斯兰文献数字化研究领域展现出重要价值。该数据集以其海量的阿拉伯语伊斯兰书籍全文内容,为研究者提供了丰富的语料资源。在阿拉伯语预训练模型优化方面,该数据集被广泛应用于语言模型的微调,显著提升了模型对古典阿拉伯语和伊斯兰术语的理解能力。同时,结合数字人文研究方法,学者们利用该数据集进行文本挖掘和知识图谱构建,深入探索伊斯兰文献中的历史脉络和学术传承。在跨学科研究中,该数据集与元数据信息的关联性为文献计量分析和学术网络研究提供了新的可能性。随着中东地区数字图书馆建设的推进,该数据集在文化遗产保护和知识传播领域的应用前景也备受关注。
以上内容由遇见数据集搜集并总结生成


