BioVITATrain
收藏arXiv2026-03-25 更新2026-03-30 收录
下载链接:
https://dahlian00.github.io/BioVITAPage/
下载链接
链接失效反馈官方服务:
资源简介:
BioVITATrain是由大阪大学等机构构建的多模态生物数据集,涵盖视觉-文本-声学三模态对齐研究。该数据集包含130万音频片段(平均时长24.6秒)和230万图像,覆盖14,133个物种并标注34种生态特征,数据来源于iNaturalist、Xeno-Canto等开放平台。通过三阶段构建流程(音频筛选、细粒度标注、视觉数据整合)确保多模态一致性,并采用GPT-5辅助生态特征标注。该数据集旨在推动跨模态物种识别研究,解决生物多样性监测中多感官信息融合的挑战,适用于计算机视觉、生态声学及跨模态检索等领域。
BioVITATrain is a multimodal biological dataset constructed by Osaka University and other institutions, focusing on visual-text-acoustic tri-modal alignment research. This dataset contains 1.3 million audio clips (with an average duration of 24.6 seconds) and 2.3 million images, covering 14,133 species and annotated with 34 ecological traits. The data is sourced from open platforms such as iNaturalist and Xeno-Canto. It adopts a three-stage construction pipeline including audio screening, fine-grained annotation, and visual data integration to ensure multimodal consistency, and leverages GPT-5 to assist with ecological trait annotation. This dataset aims to advance cross-modal species recognition research, address the challenges of multi-sensory information fusion in biodiversity monitoring, and is applicable to fields such as computer vision, eco-acoustics, and cross-modal retrieval.
提供机构:
大阪大学; 东京大学; 东京科学研究所; OMRON SINIC X
创建时间:
2026-03-25
搜集汇总
数据集介绍
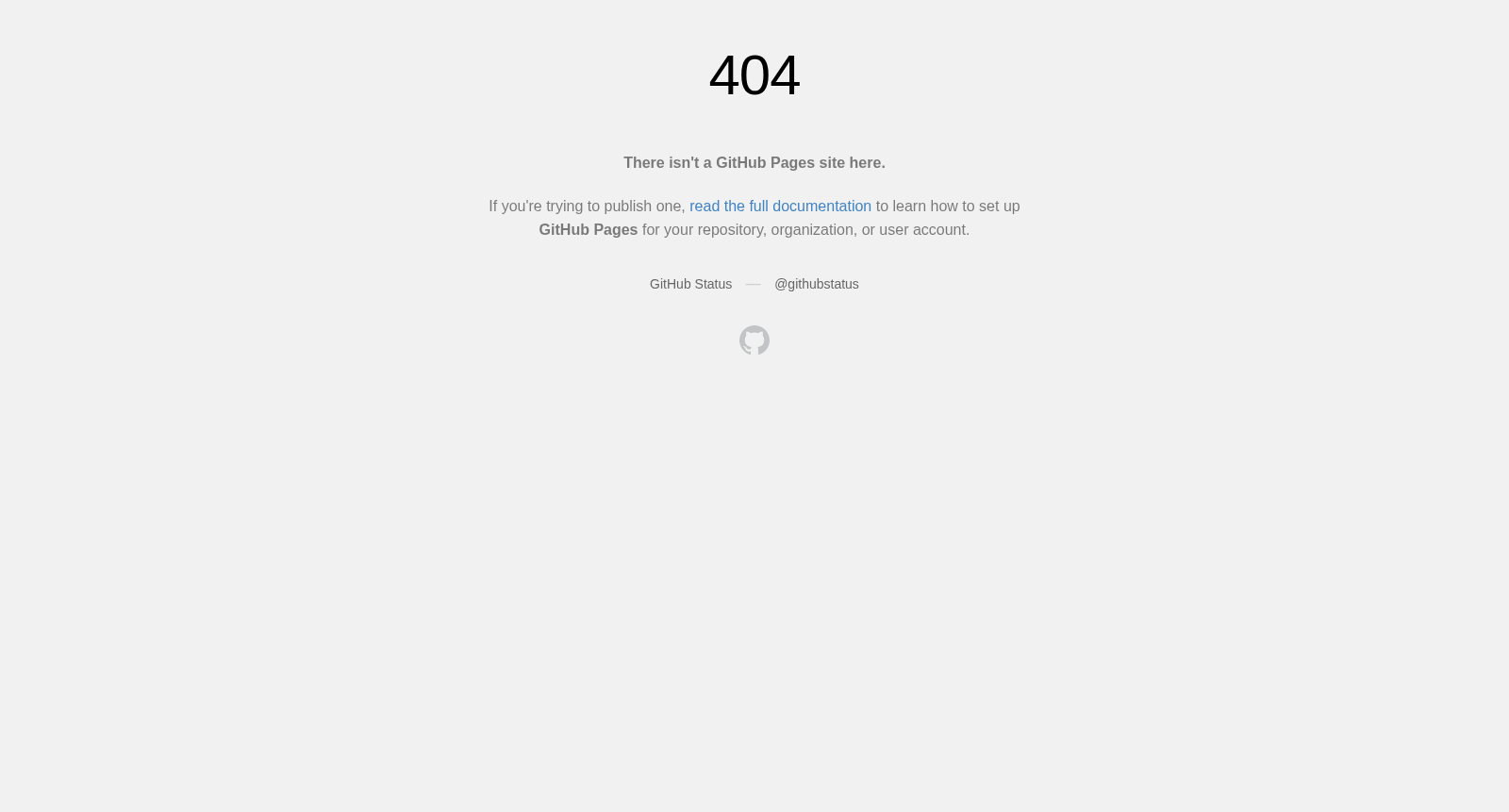
构建方式
在生物多样性研究领域,多模态数据整合已成为生态学与计算机视觉交叉的前沿挑战。BioVITATrain数据集的构建遵循系统化流程,首先从iNaturalist、Xeno-Canto和Animal Sound Archive等权威平台收集130万条音频片段,确保数据质量与许可合规性。随后,基于物种信息为每条音频标注层级分类学标签,并利用大型语言模型辅助标注34种生态性状,涵盖食性、活动模式与栖息地等关键维度。最后,为匹配音频数据中的物种,从ToL-200M数据集中抽取230万张图像,形成视觉-文本-音频三元对齐的大规模训练集。
特点
BioVITATrain的突出特点在于其规模与生态覆盖的广度。数据集涵盖14,133个物种,跨越5个纲、84个目、538个科,在音频与视觉模态上均达到百万级样本量,是目前规模最大的三模态生物数据集。其生态性状标注体系细致全面,包含34个精细标签,为模型学习物种行为与生态关联提供了丰富语义信息。此外,数据在时间与空间维度上具有充分代表性,音频平均时长达24.6秒,图像分辨率多介于119×119至2048×2048像素,保障了信号细节的完整性。
使用方法
该数据集主要服务于视觉-文本-音频对齐模型的训练与评估。研究者可采用两阶段训练框架:第一阶段通过音频-文本对比损失初步对齐声学与分类学表示;第二阶段引入图像模态,联合优化音频-图像与图像-文本对比损失,实现三模态语义空间的统一。训练完成的模型可应用于跨模态检索任务,支持图像到音频、文本到图像等六个方向的物种级检索,并在科、属、种三个分类层级上评估模型性能。数据集的生态性状标签还可用于物种行为预测等下游任务,推动生物多样性理解的深化。
背景与挑战
背景概述
BioVITATrain数据集是BioVITA框架的核心组成部分,由大阪大学、东京大学、东京科学大学及OMRON SINIC X等机构的研究人员于2026年提出,旨在解决生物多样性研究中视觉-文本-听觉多模态对齐的开放性问题。该数据集构建于大规模公开生物数据源之上,涵盖1.3百万音频片段和2.3百万图像,覆盖14,133个物种,并标注了34种生态特征标签。通过整合图像、分类学文本和音频三种模态,BioVITATrain为跨模态物种识别与生态理解提供了统一的数据基础,推动了计算机视觉与生态学交叉领域的前沿探索。
当前挑战
BioVITATrain面临的挑战主要体现在两个方面:在领域问题层面,该数据集致力于解决视觉-文本-听觉三模态对齐的复杂任务,需克服不同模态间语义鸿沟,实现细粒度物种级别的跨模态检索与识别,尤其在音频与视觉特征差异显著的物种中更具难度;在构建过程中,挑战包括多源数据整合的一致性维护,如从iNaturalist、Xeno-Canto等平台收集音频时需统一分类学层次与许可协议,同时通过大语言模型自动标注生态特征后需人工验证以确保准确性,并避免训练与测试集的数据泄漏。
常用场景
经典使用场景
在生物多样性监测与生态信息学领域,BioVITATrain数据集为视觉-文本-声学对齐提供了大规模的训练基础。该数据集最经典的使用场景是支持跨模态物种检索任务,涵盖图像、音频和文本三种模态之间的六种检索方向,例如图像到音频、音频到文本等。通过构建统一的表示空间,研究人员能够利用该数据集训练模型,实现从单一模态查询到其他模态的精准匹配,从而在物种识别和生态特征分析中实现多模态信息的互补与融合。
衍生相关工作
基于BioVITATrain数据集,衍生出了一系列重要的研究工作。例如,BioVITA框架本身提出了两阶段训练方法,有效对齐了音频表示与预训练的视觉-文本表示。后续研究扩展了该框架在更高分类层级(如属、科)的检索任务,并探索了模型对未见物种的泛化能力。此外,该数据集也为生态性状预测、跨模态基础模型(如TaxaBind)的优化提供了基准,推动了多模态学习在生物声学和计算机视觉交叉领域的深入应用。
数据集最近研究
最新研究方向
在生物多样性监测领域,BioVITATrain数据集推动了视觉-文本-声学多模态对齐的前沿研究。该数据集整合了涵盖14,133个物种的百万级音频与图像数据,并标注了34种生态特征,为跨模态物种识别提供了统一框架。当前研究热点集中于开发两阶段训练模型,通过音频-文本对齐与视觉-文本-声学联合优化,实现跨模态检索任务中的高效语义对齐。这一进展不仅提升了物种层级检索的准确性,还支持从科、属到种的多级分类任务,显著增强了模型对未见物种的泛化能力。相关研究进一步探索了生态特征预测与声学行为分析,为生物声学与计算机视觉的交叉应用开辟了新路径,对生态监测与物种保护具有深远意义。
相关研究论文
- 1BioVITA: Biological Dataset, Model, and Benchmark for Visual-Textual-Acoustic Alignment大阪大学; 东京大学; 东京科学研究所; OMRON SINIC X · 2026年
以上内容由遇见数据集搜集并总结生成


