bigbio/scitail
收藏Hugging Face2023-03-31 更新2024-03-04 收录
下载链接:
https://hf-mirror.com/datasets/bigbio/scitail
下载链接
链接失效反馈官方服务:
资源简介:
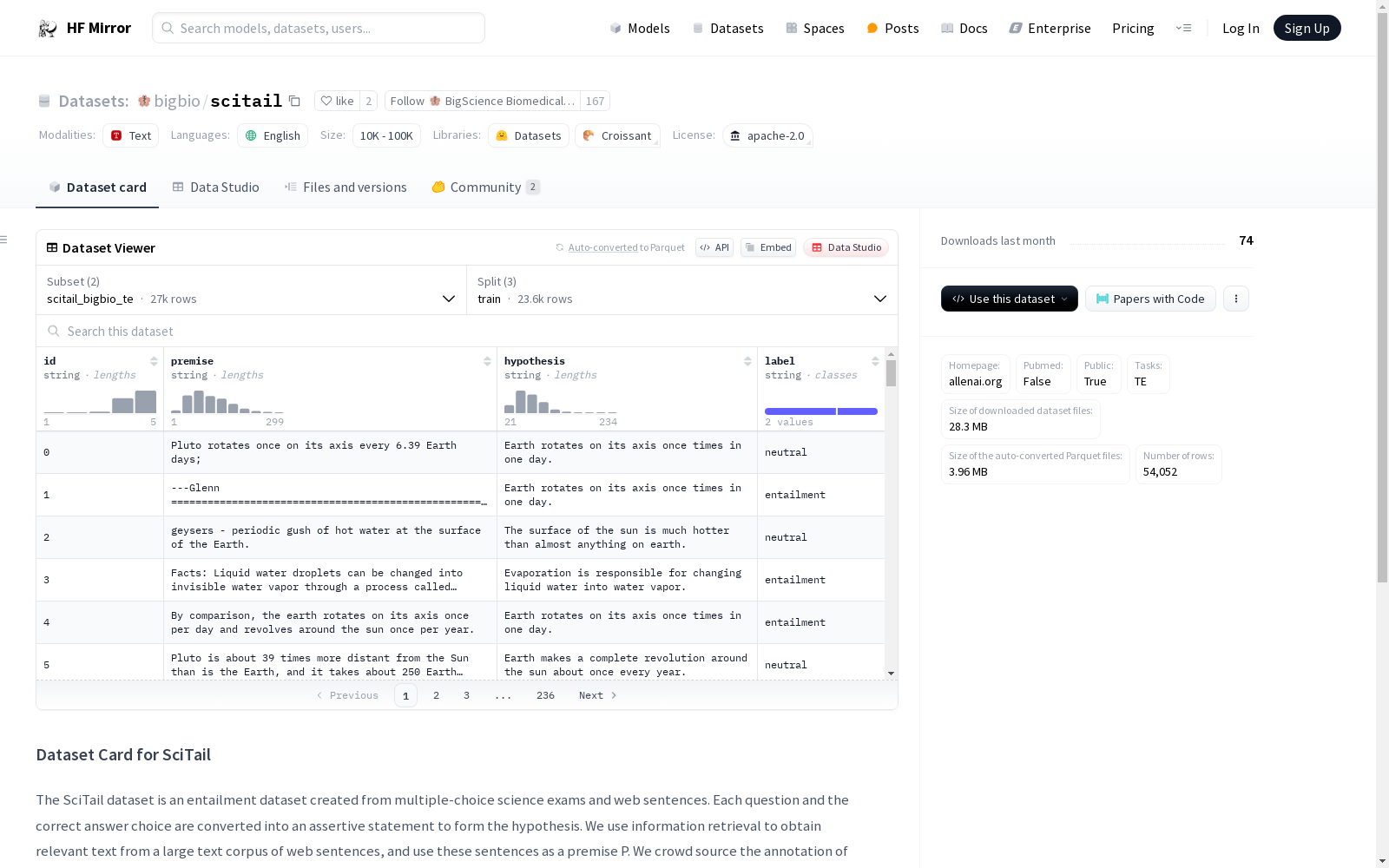
SciTail数据集是一个从多项选择科学考试和网络句子中创建的蕴含数据集。每个问题和正确答案被转换为一个断言语句以形成假设。我们使用信息检索从大量网络句子文本语料库中获取相关文本,并将这些句子作为前提P。我们通过众包的方式对这些前提-假设对进行标注,以确定它们是否支持(蕴含)或中立,从而创建SciTail数据集。该数据集包含27,026个示例,其中10,101个示例带有蕴含标签,16,925个示例带有中立标签。
The SciTail dataset is an entailment dataset constructed from multiple-choice science exams and web sentences. Each question and its correct answer are converted into declarative statements to form hypotheses. We used information retrieval to retrieve relevant texts from a large corpus of web sentences, and took these sentences as premise P. We annotated these premise-hypothesis pairs via crowdsourcing to determine whether their relationship is entailment (support) or neutral, thereby creating the SciTail dataset. This dataset contains 27,026 instances, among which 10,101 instances carry the entailment label and 16,925 instances carry the neutral label.
提供机构:
bigbio
原始信息汇总
数据集概述:SciTail
基本信息
- 名称:SciTail
- 语言:英语
- 许可证:Apache-2.0
- 多语言性:单语种
- 公开状态:公开
- 任务类型:文本蕴含(TEXTUAL_ENTAILMENT)
数据集描述
- 来源:由多选科学考试题目和网络句子构建
- 构建方法:将每个问题和正确答案转换为断言性陈述作为假设,通过信息检索从大型网络句子文本库中获取相关文本作为前提P,并通过众包方式标注前提-假设对是否支持(蕴含)或不支持(中性)
- 数据量:包含27,026个例子,其中10,101个例子标注为蕴含,16,925个例子标注为中性
引用信息
@inproceedings{scitail, author = {Tushar Khot and Ashish Sabharwal and Peter Clark}, booktitle = {AAAI}, title = {SciTail: A Textual Entailment Dataset from Science Question Answering}, year = {2018} }
搜集汇总
数据集介绍
构建方式
SciTail数据集的构建基于科学试题与网络句子的结合。该数据集的构建者首先从多选题的科学考试中提取出问题和正确答案,并将它们转化为肯定陈述以形成假设。接着,利用信息检索技术从大量的网络句子中获取相关文本,作为前提P。最后,通过众包的方式对前提-假设对进行标注,判断其为支持(entails)或中立(neutral),从而形成了包含27,026个例子的SciTail数据集。
使用方法
使用SciTail数据集时,研究者可以将其应用于文本蕴含的模型训练和评估。数据集的每一例子都包含一个前提和一个假设,以及一个标签,指示假设是否由前提所支持。用户可以根据自己的需求,利用这些标注好的数据对模型进行训练,或对已有模型进行性能评估。
背景与挑战
背景概述
在自然语言处理领域,文本蕴含作为一项基础任务,旨在判断一个句子(前提)是否能够推导出另一个句子(假设)。SciTail数据集,由Tushar Khot、Ashish Sabharwal和Peter Clark等于2018年创建,是针对科学领域文本蕴含任务的一个专业数据集。该数据集依托于多项选择题的科学考试和网页句子,通过将问题和正确答案转换为肯定陈述形成假设,并结合信息检索技术从大量网页句子中获取相关文本作为前提,进而构建起包含27,026个例子的数据集,其中10,101个标注为蕴含标签,16,925个标注为中立标签。SciTail数据集的问世,为科学领域的文本蕴含研究提供了重要的资源,对相关领域的发展产生了积极影响。
当前挑战
SciTail数据集在构建过程中,首先面临的挑战是如何从海量的科学文本中高效地检索到与问题相关的句子,并确保其质量与相关性。其次,数据集中蕴含标签与中立标签的分布不均,可能导致模型偏向于多数类别,影响其泛化能力。此外,科学领域的专业性和复杂性使得标注过程具有较高难度,对标注员的科学知识和语言理解能力提出了较高要求。在解决领域问题时,如何设计能够适应科学文本特点的文本蕴含模型,以及如何评估模型的性能,是该数据集相关研究的两大挑战。
常用场景
经典使用场景
在文本理解和推理研究领域,SciTail数据集的经典使用场景在于评估模型在科学文本中的推理能力。通过将科学考题与网络句子相结合,构建前提-假设对,进而标注为蕴含或中立,该数据集为研究者提供了一个独特的测试平台。
解决学术问题
SciTail数据集解决了科学文本推理中的标注一致性问题和数据集规模限制问题,它通过众包方式确保了标注的质量,并提供了足够的数据量,以支持大规模的机器学习模型训练与评估。
实际应用
实际应用中,SciTail数据集被广泛用于提升机器学习模型在科学领域的文本理解能力,这对于科学知识问答系统、教育辅助工具以及信息检索系统具有重要的意义和影响。
数据集最近研究
最新研究方向
SciTail数据集作为文本蕴含领域的重要资源,其最新研究方向聚焦于提升科学文本理解的准确性与深度。近期研究围绕如何更高效地利用该数据集进行模型训练,以实现对科学领域文本蕴含关系的精确预测。这不仅涉及到自然语言处理技术的深化,还关乎科学知识图谱的构建与应用。SciTail在学术界的广泛采用,推动了文本蕴含任务在科学问答领域的实际应用,对提升人工智能在科学教育辅助、信息检索等方面的能力具有重要意义。
以上内容由遇见数据集搜集并总结生成


