polyreaction
收藏Hugging Face2025-05-01 更新2025-05-02 收录
下载链接:
https://huggingface.co/datasets/ZYMScott/polyreaction
下载链接
链接失效反馈官方服务:
资源简介:
纳米抗体多反应性预测数据集,用于预测纳米抗体是否具有与多个不相关抗原结合的多反应性。该数据集基于实验室实验和公开文献中的纳米抗体多反应性数据,包含训练集、验证集和测试集,可用于开发预测模型、筛选高度特异性的纳米抗体候选者以及理解序列特征和多反应性的分子基础。
Nanobody polyreactivity prediction dataset. This dataset is designed to predict whether nanobodies possess polyreactivity, i.e., the ability to bind to multiple unrelated antigens. It is constructed using nanobody polyreactivity data sourced from laboratory experiments and peer-reviewed published literature, and includes training, validation, and test sets. The dataset can be utilized to develop predictive models, screen highly specific nanobody candidates, and elucidate the molecular basis linking sequence features to polyreactivity.
创建时间:
2025-04-24
原始信息汇总
Nanobody Polyreactivity Prediction Dataset 数据集概述
数据集简介
- 用途:预测纳米抗体是否表现出多反应性(即与多种不相关抗原结合的倾向)
- 重要性:多反应性在治疗应用中通常是不希望出现的特征,可能导致副作用和疗效降低
- 应用场景:用于筛选高质量治疗候选抗体和理解抗体特异性的分子基础
数据来源
- 基于实验室实验测量的纳米抗体多反应性数据
- 从公开文献中收集
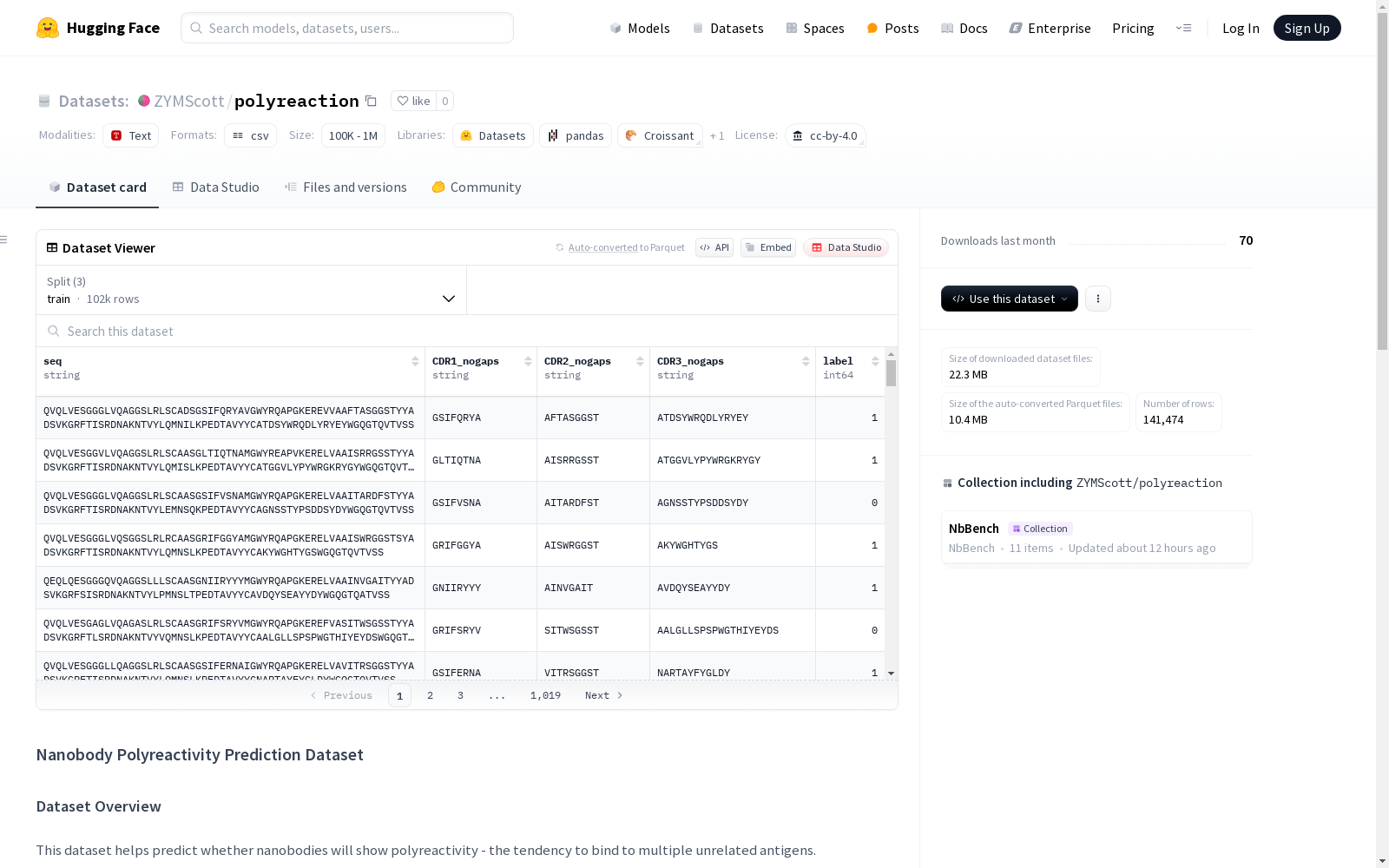
数据结构
- 数据划分:分为训练集、验证集和测试集
- 文件格式:CSV文件
- 包含列:
seq:纳米抗体氨基酸序列label:二进制标签(1表示高多反应性,0表示低多反应性)
- 包含列:
使用与限制
使用场景
- 开发预测纳米抗体多反应性的模型
- 筛选高特异性纳米抗体候选物
- 理解多反应性的序列特征和分子基础
局限性
- 测量多反应性的实验方法可能存在差异
- 多反应性是一个连续谱而非严格的二元属性
- 不同实验条件可能影响多反应性
评估指标
- 准确率(Accuracy)
- F1分数(F1 Score)
- 精确率(Precision)
- 召回率(Recall)
- AUROC(接收者操作特征曲线下面积)
- AUPRC(精确率-召回率曲线下面积)
许可信息
- 许可证类型:CC-BY-4.0
搜集汇总
数据集介绍
构建方式
在抗体工程领域,纳米抗体的多反应性预测对治疗性候选分子筛选至关重要。该数据集基于实验室测量的纳米抗体多反应性实验数据构建,数据来源均来自公开文献。研究人员通过检测纳米抗体与多种非相关抗原的结合能力,将其分类为多反应性或非多反应性,形成具有明确标注的序列数据集。数据以标准化流程进行收集和验证,确保实验方法的可靠性和结果的可比性。
使用方法
研究人员可利用该数据集开发预测模型,通过分析序列特征与多反应性的关联规律,建立高效的筛选工具。典型应用场景包括治疗性纳米抗体候选分子的虚拟筛选,以及多反应性分子机制的研究。使用时应结合多种评估指标,包括准确率、F1分数和AUROC等,全面衡量模型性能。考虑到多反应性本质上是连续特性,在模型开发中需注意二元分类的局限性,必要时可采用概率输出或回归方法进行优化。
背景与挑战
背景概述
纳米抗体多反应性预测数据集(Nanobody Polyreactivity Prediction Dataset)聚焦于生物医药领域中的关键问题——纳米抗体的多反应性预测。纳米抗体作为单域抗体的一种,因其体积小、稳定性高而在治疗性抗体开发中备受关注。然而,多反应性(即抗体与多种非相关抗原结合的特性)会显著降低治疗效果并引发副作用。该数据集由研究团队通过整合公开文献中的实验数据构建,旨在为筛选高质量治疗候选抗体提供数据支持,并深入探究抗体特异性的分子基础。其核心研究问题在于建立序列特征与多反应性之间的可靠关联,对加速抗体药物开发具有重要价值。
当前挑战
该数据集面临双重挑战:在科学层面,多反应性本质上属于连续光谱特性,将其简化为二元分类可能丢失关键生物信息;实验测量方法的差异性导致数据异质性,影响模型泛化能力。在技术层面,氨基酸序列的稀疏表征难以捕捉决定多反应性的复杂结构特征,而有限的数据规模对深度学习模型构成挑战。评估指标虽全面涵盖分类性能(如AUROC、AUPRC),但如何建立与真实生物效应相关的评价体系仍需探索。数据构建过程中,实验条件标准化与多反应性阈值界定等环节均存在显著技术难度。
常用场景
经典使用场景
在生物医药领域,纳米抗体的多反应性预测是药物开发中的关键环节。polyreaction数据集通过提供标注明确的纳米抗体序列及其多反应性标签,为研究人员构建机器学习模型提供了坚实基础。该数据集最经典的使用场景是训练深度学习模型,如卷积神经网络或Transformer架构,以从氨基酸序列中自动识别导致多反应性的关键模式。
解决学术问题
该数据集有效解决了治疗性抗体开发中的核心难题——如何早期预测候选抗体的多反应性。通过提供标准化的实验数据,研究人员能够系统探究序列特征与多反应性的关联机制,弥补了传统实验方法耗时费力的不足。其重要意义在于为理性设计高特异性抗体提供了数据支撑,显著降低了药物开发中的后期失败风险。
实际应用
在制药工业实践中,该数据集已被广泛应用于候选药物分子的虚拟筛选环节。生物技术公司利用基于该数据集训练的预测模型,能够快速评估抗体库中分子的多反应性倾向,大幅提高筛选效率。特别是在CAR-T细胞治疗和双特异性抗体开发领域,这种早期风险预测能力显著降低了研发成本。
数据集最近研究
最新研究方向
近年来,纳米抗体多反应性预测研究已成为生物医药领域的热点之一。随着人工智能技术在蛋白质工程中的深入应用,该数据集被广泛用于开发基于深度学习的多反应性预测模型。研究者们正探索将Transformer架构与图神经网络相结合,以更精准地捕捉纳米抗体序列中的结构特征与多反应性之间的复杂关系。在抗体药物研发领域,这一研究方向对于提高候选分子筛选效率、降低临床前开发成本具有显著意义。最新进展表明,结合物理化学特征与序列信息的混合模型在该数据集上取得了突破性性能,为理解多反应性的分子机制提供了新视角。
以上内容由遇见数据集搜集并总结生成


