traffic-accidents-reports-5k
收藏Hugging Face2025-08-29 更新2025-08-30 收录
下载链接:
https://huggingface.co/datasets/zBotta/traffic-accidents-reports-5k
下载链接
链接失效反馈官方服务:
资源简介:
这是一个包含5千个事故报告的数据集,适用于文本生成任务,特别是将5W1H格式(包括什么、何时、何地、谁、怎样、为什么和应急措施)转换为一个不带换行的单段落中性报告。数据集分为训练集、验证集和测试集,样本量分别为大约4500、500和100。数据集是英文的,采用Parquet格式存储,适用于对小型指令模型进行微调,以便生成简洁、结构化的事故报告。
This is a dataset comprising 5,000 accident reports tailored for text generation tasks, specifically aimed at converting content structured in the 5W1H format (encompassing what, when, where, who, how, why, and emergency response measures) into a single, continuous neutral paragraph without line breaks. The dataset is divided into training, validation, and test subsets, with approximate sample counts of 4,500, 500, and 100 respectively. Stored in Parquet format, the dataset is in English and is intended for fine-tuning small-scale instruction-tuned models to generate concise and well-structured accident reports.
创建时间:
2025-08-29
原始信息汇总
数据集概述
基本信息
- 数据集名称:5k Accident Reports
- 数据集标识:zBotta/traffic-accidents-reports-5k
- 任务类别:文本生成(text-generation)
- 数据规模:1K<n<10K
- 语言:英语
- 许可证:MIT
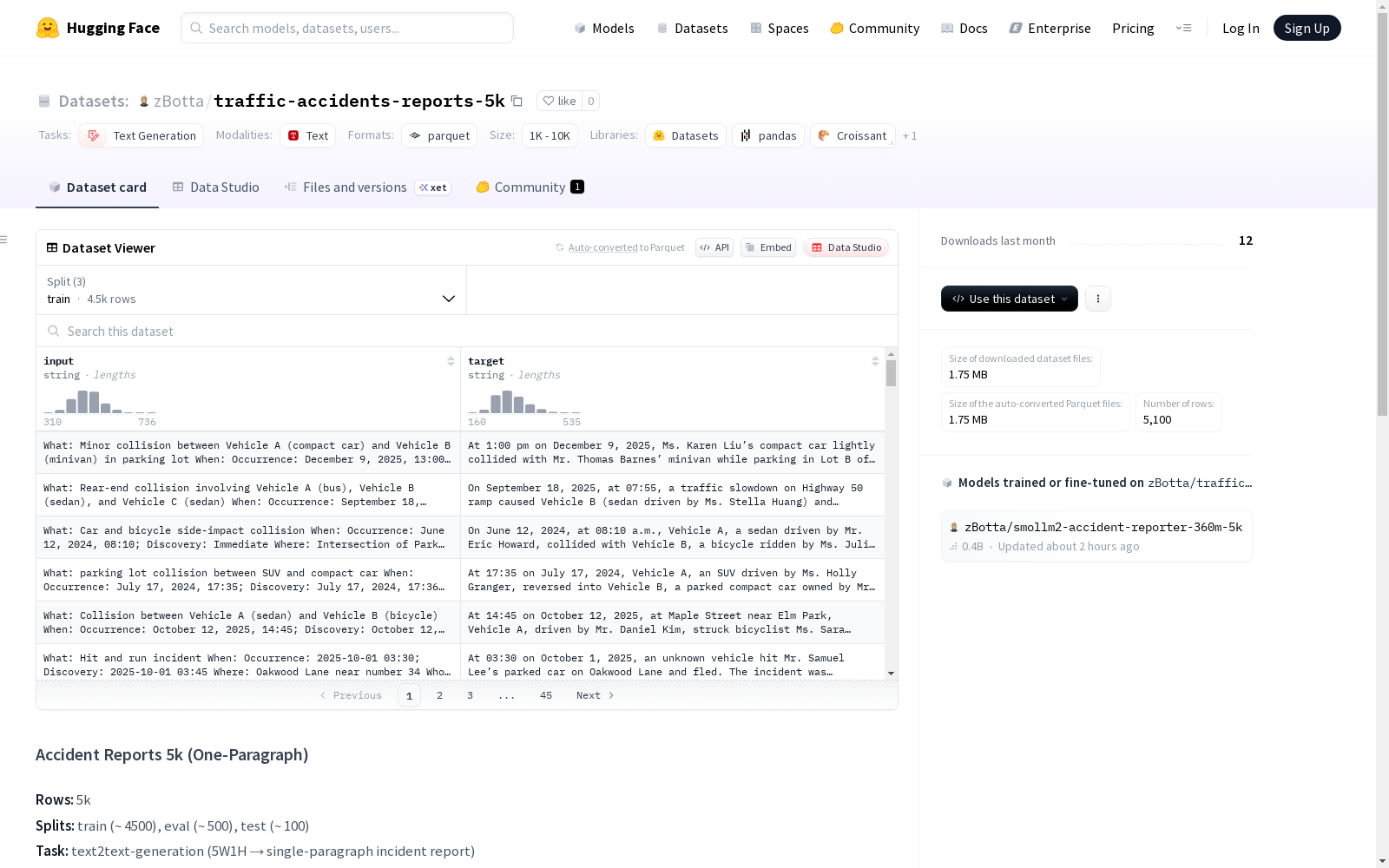
数据内容
- 总样本量:5,100条
- 特征字段:
input(字符串):包含5W1H信息行(What、When、Where、Who、How、Why、ContingencyActions)target(字符串):单段落中性事件报告(无换行符)
- 文件格式:parquet数据集(训练就绪)
数据划分
- 训练集(train):4,499个样本,3,582,676字节
- 验证集(eval):500个样本,398,073字节
- 测试集(test):101个样本,76,508字节
技术规格
- 下载大小:1,745,985字节
- 数据集总大小:4,057,257字节
用途说明
- 主要用途:用于微调小型指令模型,生成简洁、结构化的事件报告
- 任务类型:文本到文本生成(5W1H → 单段落事件报告)
限制说明
- 数据为合成/策划文本,使用时需根据具体领域需求进行验证
搜集汇总
数据集介绍
构建方式
在交通安全管理领域,结构化数据的高效转化至关重要。本数据集通过人工标注与规则化合成相结合的方式构建,从原始事故记录中提取5W1H要素(何事、何时、何地、何人、如何、为何及应急措施),并转化为标准化的文本输入格式。每个样本均经过双重校验,确保输入字段与目标文本的对应准确性,最终形成包含5100个样本的平行语料库,按4:1:0.1的比例划分为训练集、验证集和测试集。
特点
该数据集最显著的特征在于其高度结构化的输入设计,采用5W1H框架系统化组织事故要素,为目标文本生成提供清晰的逻辑骨架。所有输出文本均经过标准化处理,保持客观中立的叙述风格且严格遵循单段落无换行格式,有效避免了文本生成的随意性。数据集规模控制在五千余条,既满足模型微调需求又保持轻量化特性,所有数据均以Parquet格式存储确保加载效率。
使用方法
使用者可通过Hugging Face数据集库直接加载该资源,调用load_dataset函数即可获取已分割的训练、验证和测试集。该数据集专为文本生成任务设计,输入为结构化的5W1H元数据,输出为连贯的事故报告段落,适用于微调生成式语言模型。在实际应用中,建议先对合成数据进行领域适应性验证,再结合具体场景调整生成策略,以获得更符合实际需求的事故报告输出。
背景与挑战
背景概述
交通事故报告数据集traffic-accidents-reports-5k由研究机构于现代人工智能发展时期创建,专注于智能交通系统中的自然语言处理应用。该数据集旨在通过结构化的事故报告生成,提升交通安全管理的自动化水平,核心研究问题聚焦于如何从5W1H关键要素自动生成简洁、准确的事故描述段落。其对智能交通系统、保险理赔自动化及公共安全数据分析领域产生了显著影响,为小规模指令微调模型提供了高质量训练资源。
当前挑战
该数据集主要解决交通事故报告自动生成的领域挑战,包括从碎片化信息中构建连贯叙事、保持事实准确性与语言中立性,以及处理多样化的场景复杂性。构建过程中面临合成数据与真实场景的语义对齐难题,需确保5W1H要素到段落生成的逻辑一致性,同时克服标注过程中主观偏差对报告中立性的影响,并维持数据规模与质量平衡以支持模型泛化能力。
常用场景
经典使用场景
在交通安全研究领域,该数据集被广泛用于训练文本生成模型,将结构化的5W1H事件要素转化为连贯的事故报告段落。研究人员通过输入包含时间、地点、人员、原因等关键信息的结构化数据,模型能够自动生成符合规范的单段落事故描述文本,显著提升了事故报告撰写的效率与标准化程度。
解决学术问题
该数据集有效解决了自然语言生成领域中结构化数据到流畅文本的转换难题,为学术研究提供了高质量的文本生成基准。通过提供标准化的输入输出对应关系,它助力于研究事件报告生成模型的性能评估与优化,推动了可控文本生成技术在实际应用中的发展,对提升自动化报告系统的准确性与可靠性具有重要意义。
衍生相关工作
基于该数据集,衍生出了多项关于指令微调小模型的研究,探索了在有限数据下提升文本生成质量的方法。相关经典工作包括改进的序列到序列模型架构、针对事件报告领域的特定优化技术,以及多任务学习框架,这些研究进一步扩展了数据集在学术与工业界的应用范围与影响力。
以上内容由遇见数据集搜集并总结生成


