DollyTails-12K
收藏Hugging Face2025-01-17 更新2025-01-18 收录
下载链接:
https://huggingface.co/datasets/PKU-Alignment/DollyTails-12K
下载链接
链接失效反馈官方服务:
资源简介:
DollyTails-12K数据集设计用于遵循指令的任务,采用System 2(类似于O1)的思维范式。数据集中的提示来源于databricks/databricks-dolly-15k,并由GPT-4o进行思考和答案的注释。经过仔细的过滤和筛选,最终数据集包含12K个问答对。每个任务平均有4.93个推理步骤,最多不超过7个步骤,以避免训练过程中不必要的开销。该数据集可用于对大型语言模型(LLM)进行监督微调(SFT),以获得具有System 2类似推理范式的模型。
DollyTails-12K dataset is designed for instruction-following tasks, adopting the System 2 thinking paradigm similar to that of O1. The prompts in the dataset are sourced from databricks/databricks-dolly-15k, and annotated with reasoning steps and final answers generated by GPT-4o. After rigorous filtering and screening, the finalized dataset contains 12K question-answer pairs. Each task has an average of 4.93 reasoning steps, with a maximum of 7 steps, to avoid unnecessary overhead during model training. This dataset can be utilized for supervised fine-tuning (SFT) of Large Language Models (LLMs) to develop models equipped with System 2-like reasoning paradigms.
提供机构:
PKU-Alignment
创建时间:
2025-01-17
搜集汇总
数据集介绍
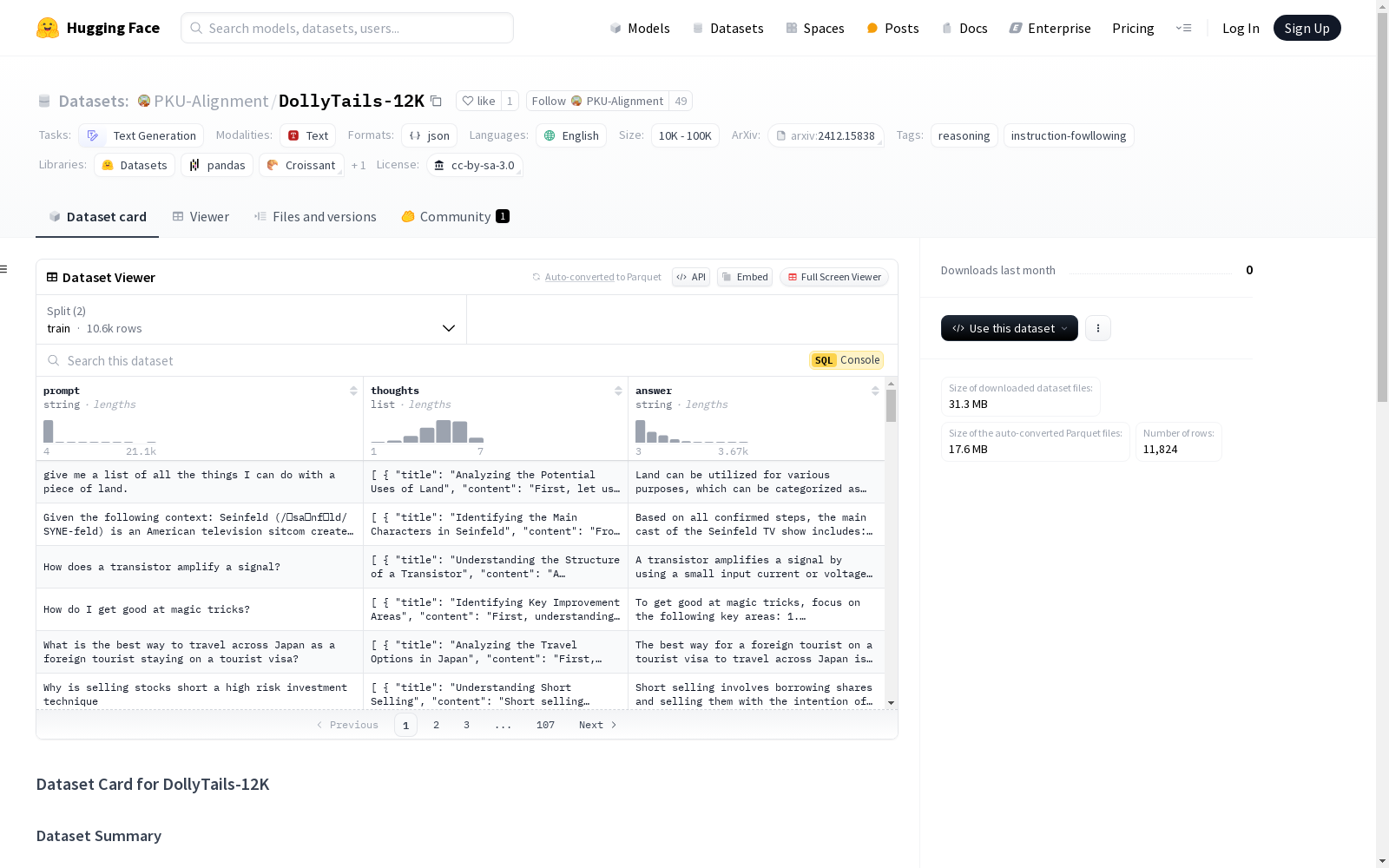
构建方式
DollyTails-12K数据集的构建基于System 2思维范式,专为指令跟随任务设计。其提示词来源于databricks-dolly-15k数据集,并由GPT-4o进行思考和答案的标注。经过严格的筛选和过滤,最终形成了包含12,000个问答对的数据集。每个任务平均包含4.93个推理步骤,且最多不超过7个步骤,以避免冗长样本带来的训练负担。
使用方法
使用DollyTails-12K数据集时,可通过Hugging Face的`datasets`库加载训练集和验证集。具体代码示例如下:`train_dataset = load_dataset('PKU-Alignment/DollyTails-12K', split='train')`和`val_dataset = load_dataset('PKU-Alignment/DollyTails-12K', split='validation')`。该数据集适用于大语言模型的监督微调,用户可参考[Align-Anything](https://github.com/PKU-Alignment/align-anything)项目中的训练代码进行模型优化。
背景与挑战
背景概述
DollyTails-12K数据集由北京大学对齐研究团队于2024年发布,旨在通过系统2(System 2)思维范式提升大语言模型(LLM)在指令跟随任务中的表现。该数据集基于Databricks的Dolly-15K数据集构建,并通过GPT-4o对问题和答案进行了精细的注释与筛选,最终形成了包含12,000个问答对的高质量数据集。每个任务平均包含4.93个推理步骤,最多不超过7步,以避免冗长样本对训练效率的影响。DollyTails-12K的发布为大语言模型的监督微调(SFT)提供了重要资源,推动了指令跟随与推理能力的研究进展。
当前挑战
DollyTails-12K数据集在构建与应用中面临多重挑战。首先,在领域问题层面,如何确保模型在复杂推理任务中表现出系统2思维的高效性与准确性是一个核心难题,尤其是在多步推理任务中,模型容易陷入局部最优或产生逻辑错误。其次,在数据集构建过程中,如何平衡样本的多样性与质量,避免因过度筛选导致数据偏差,同时控制推理步骤的复杂度以提升训练效率,是另一个关键挑战。此外,数据集的高质量标注依赖于GPT-4o的能力,但其生成结果的可靠性与一致性仍需进一步验证与优化。
常用场景
经典使用场景
DollyTails-12K数据集在自然语言处理领域中被广泛应用于指令跟随任务的模型训练。通过提供包含多步推理的问答对,该数据集特别适用于训练大型语言模型(LLM)以模拟人类复杂的思维过程。研究人员可以利用该数据集进行监督微调(SFT),从而提升模型在复杂推理任务中的表现。
解决学术问题
DollyTails-12K数据集解决了在指令跟随任务中模型推理能力不足的问题。通过引入多步推理的问答对,该数据集帮助模型更好地理解和执行复杂的指令,从而提升了模型在需要深度推理的任务中的表现。这一数据集的出现为研究如何增强语言模型的推理能力提供了重要的实验基础。
实际应用
在实际应用中,DollyTails-12K数据集可以用于开发智能助手、自动化客服系统以及其他需要复杂指令理解和执行的场景。通过使用该数据集进行模型训练,系统能够更准确地理解用户的需求,并提供更加智能和个性化的服务。
数据集最近研究
最新研究方向
在自然语言处理领域,DollyTails-12K数据集以其独特的System 2思维范式在指令跟随任务中展现出显著的研究价值。该数据集通过GPT-4o的精细标注,提供了12K个问答对,每个任务平均包含4.93个推理步骤,旨在训练大型语言模型以实现类似System 2的推理能力。当前研究热点集中在如何利用该数据集进行监督微调(SFT),以提升模型在复杂指令理解和多步推理任务中的表现。此外,结合Align-Anything项目的最新进展,研究者们正在探索如何通过语言反馈训练全模态模型,以进一步扩展模型的应用场景和性能边界。这一研究方向不仅推动了指令跟随模型的智能化进程,也为多模态交互系统的开发提供了新的思路和工具。
以上内容由遇见数据集搜集并总结生成


