B(asic) E(motion) R(andom phrase) S(hou)t(s) (BERSt) 数据集
收藏arXiv2025-04-30 更新2025-05-03 收录
下载链接:
https://huggingface.co/datasets/chocobearz/BERSt
下载链接
链接失效反馈官方服务:
资源简介:
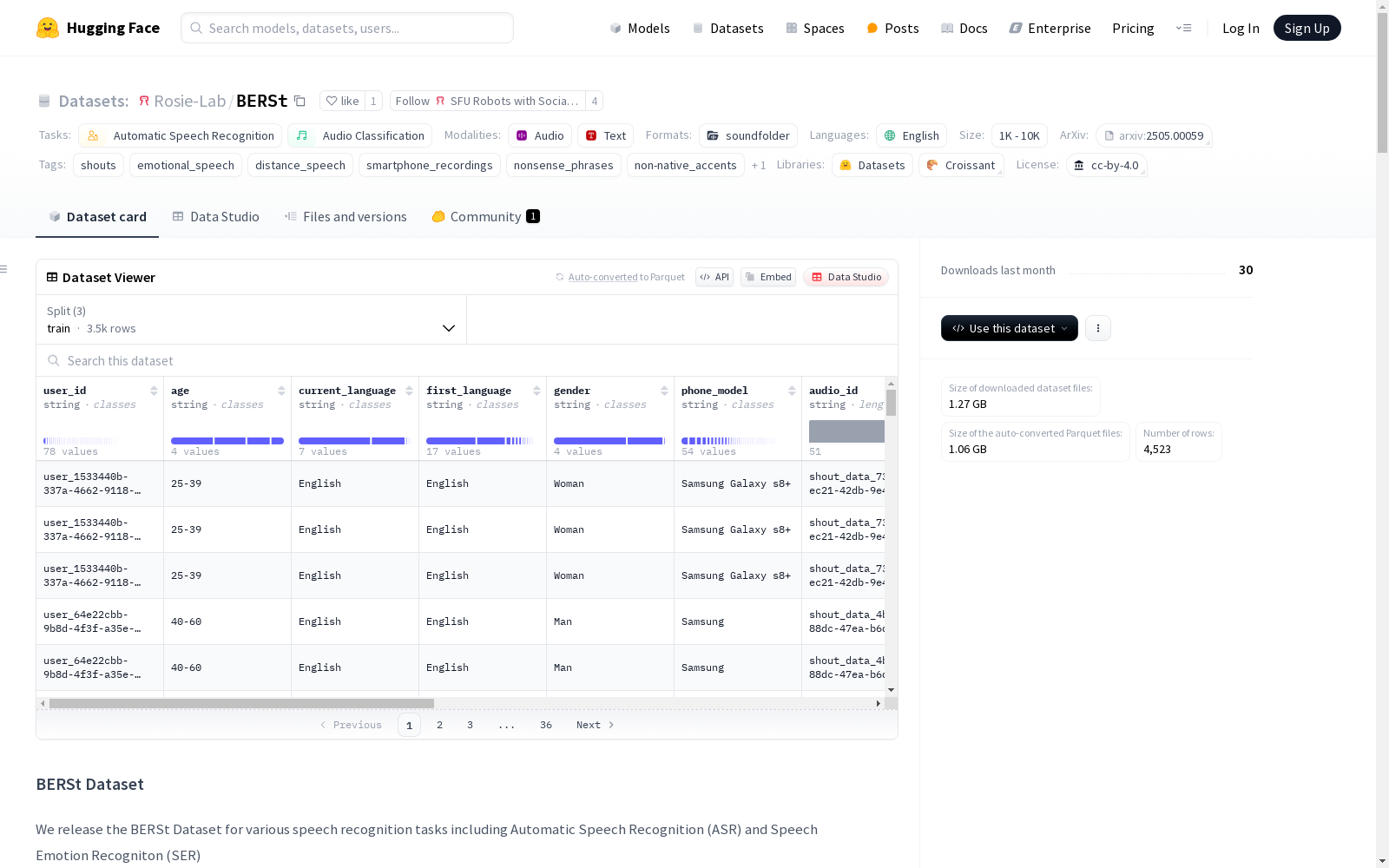
BERSt数据集是一个包含距离远、情感丰富和喊叫的语音数据集,由98位演员在不同的家庭环境中使用智能手机录制而成。数据集包含约4小时的英语语音,涵盖了不同的地区和非本地口音。数据集包含7种不同的情感提示,以及口语和喊叫的表述。智能手机被放置在19个不同的位置,包括有遮挡物和与演员在不同房间的位置。该数据集公开可用,可用于评估各种语音识别任务,包括自动语音识别、喊叫检测和语音情感识别。数据集的创建旨在帮助微调语音识别任务,并为距离远、高唤醒度的语音提供可靠的语音识别。该数据集对于自动语音识别和语音情感识别任务都具有挑战性,需要继续努力提高此类系统的鲁棒性,以实现更准确的真实世界应用。
The BERSt dataset is a speech dataset featuring distant-talking, emotionally expressive, and shouted speech, recorded by 98 actors using smartphones in various home environments. It contains approximately 4 hours of English speech, covering diverse regional and non-native accents. The dataset includes 7 distinct emotional prompts, as well as both conversational and shouted utterances. Smartphones were placed at 19 different positions, including positions with obstacles and in separate rooms from the actors. This publicly available dataset can be used to evaluate a variety of speech recognition tasks, including automatic speech recognition (ASR), shouted speech detection, and speech emotion recognition (SER). The dataset was created to aid fine-tuning for speech recognition tasks and to provide reliable speech recognition for distant-talking, high-arousal speech. This dataset poses challenges for both automatic speech recognition and speech emotion recognition tasks, calling for continued efforts to improve the robustness of such systems for more accurate real-world applications.
提供机构:
西蒙弗雷泽大学计算科学学院, 法国国家科学研究中心微纳米技术实验室, 法国弗朗什-孔泰大学, 魔法工具公司
创建时间:
2025-04-30
原始信息汇总
BERSt数据集概述
基本信息
- 许可证: CC-BY-4.0
- 任务类别: 自动语音识别、音频分类
- 语言: 英语
- 标签: 喊叫、情感语音、远距离语音、智能手机录音、无意义短语、非母语口音、地区口音
- 数据集名称: B(asic) E(motion) R(andom phrase) S(hou)t(s)
- 规模: 1K<n<10K
数据集内容
- 录音数量: 4526个单短语录音(约3.75小时)
- 参与者: 98名专业演员
- 手机位置: 19种
- 情感类别: 7类
- 声音强度级别: 3级
- 口音: 多样化的地区和非母语英语口音
- 短语: 涵盖所有英语音素的无意义短语
数据收集
- 环境: 家庭环境
- 设备: 各种智能手机麦克风(手机型号作为元数据提供)
- 参与者分布: 全球范围,包括英国、加拿大、美国(多州)、澳大利亚等地区口音,以及非母语英语口音(法语、俄语、印地语等)
- 短语: 13个无意义短语
- 录音方式: 参与者被要求以不同声音强度(说话、提高声音、喊叫)录制短语,同时移动手机到不同距离和位置
数据分割与组织
- 原始音频文件: 包含每个手机位置和短语的三种声音强度级别的录音
- 元数据: CSV格式,对应每个数据分割的
clean_clips中的文件 - 数据分割: 测试集、训练集和验证集
- 分割特点: 无说话者交叉,训练集和验证集各包含10个未见过的说话者
基准结果
自动语音识别
| 模型 | WER ↓ | CER ↓ | PER ↓ |
|---|---|---|---|
| Whisper - medium.en | 17.27% | 7.81% | 7.80% |
| Whisper - turbo | 17.93% | 7.28% | 7.30% |
| NeMo Quartznet | 39.49% | 15.24% | 15.77% |
| NeMo Fastconformer Transducer | 24.96% | 10.72% | 10.13% |
| Wav2Vec2-Base-960h | 49.65% | 18.94% | 19.90% |
语音情感识别
| 模型 | UA ↑ | WA ↑ |
|---|---|---|
| SpeechBrain Wav2Vec2 | 20.7% | 20.8% |
| DAWN-hidden-SVM | 32.1% | 32.2% |
| Wav2Small-VAD-SVM* | 23.3% | 22.3% |
元数据详情
参与者统计
- 性别: 女性61人,男性34人,非二元性别1人,不愿透露2人
- 日常语言: 英语95人,挪威语1人,俄语1人,法语1人
- 母语: 英语75人,非英语23人(西班牙语6人,法语3人,葡萄牙语3人等)
数据统计
- 情感类别: 恐惧236,中性234,厌恶232,快乐224,愤怒223,惊讶210,悲伤201
- 距离类别: 近身627,1-2米远324,房间另一侧316,房间外293
引用
bibtex @misc{tuttösí2025berstingscreamsbenchmarkdistanced, title={BERSting at the Screams: A Benchmark for Distanced, Emotional and Shouted Speech Recognition}, author={Paige Tuttösí and Mantaj Dhillon and Luna Sang and Shane Eastwood and Poorvi Bhatia and Quang Minh Dinh and Avni Kapoor and Yewon Jin and Angelica Lim}, year={2025}, eprint={2505.00059}, archivePrefix={arXiv}, primaryClass={cs.CL}, url={https://arxiv.org/abs/2505.00059}, }
搜集汇总
数据集介绍
构建方式
BERSt数据集通过智能手机在98位演员的家庭环境中采集远程、情感化和喊叫语音数据。每位演员在19种不同位置(包括障碍物和不同房间)录制了7种基本情感(中性、愤怒、快乐、恐惧、厌恶、惊讶和悲伤)以及三种发声强度(说话、喊叫和尖叫)的语音。数据采集过程中使用了14个无意义的随机短语,以确保语音识别系统不依赖语境。数据经过语音活动检测(VAD)工具分割,并由人工校对和清理,最终形成4526个音频片段(约3.75小时)。
特点
BERSt数据集的特点在于其多样性和真实性。数据集涵盖了多种口音(包括区域性和非母语口音)和98种不同的声学环境,反映了真实世界的复杂性。语音特征随距离、喊叫强度和情感的变化而显著不同,为研究语音识别系统在复杂环境中的鲁棒性提供了丰富的数据支持。此外,数据集还标注了距离、喊叫强度和情感意图,适用于自动语音识别(ASR)、喊叫检测和语音情感识别(SER)等多种任务。
使用方法
BERSt数据集可用于评估和优化语音识别系统在远程、情感化和高强度语音场景下的性能。研究人员可以使用该数据集进行ASR模型的微调和基准测试,分析距离和喊叫强度对识别准确率的影响。此外,数据集还可用于SER任务,尽管情感标签尚未经过验证,但仍可作为评估工具。数据集已按80/10/10的比例划分为训练集、测试集和验证集,且确保不同距离、喊叫强度和情感在各集合中分布均衡。
背景与挑战
背景概述
BERSt数据集是由Simon Fraser大学等机构的研究团队于2025年提出的一个专注于远距离、情感化和喊叫语音识别的基准数据集。该数据集包含来自98名演员在家庭环境中通过智能手机录制的近4小时英语语音,涵盖了7种基本情感状态和3种发声强度(说话、喊叫、尖叫),并在19种不同手机位置条件下采集,包括障碍物和跨房间场景。作为首个系统研究远距离情感喊叫语音的多维度数据集,BERSt填补了传统语音识别数据在真实复杂场景中的空白,为自动语音识别(ASR)、喊叫检测和语音情感识别(SER)等任务提供了新的评估基准。其创新性的多变量控制设计和全球化口音覆盖,对提升语音系统在应急场景、智能家居等现实应用中的鲁棒性具有重要意义。
当前挑战
BERSt数据集主要面临三方面挑战:在领域问题层面,现有ASR模型对远距离喊叫语音的识别错误率(WER)高达29.55%-76.21%,情感语音识别准确率不足32.2%,反映出传统基于中性语音训练的模型难以处理声学特征剧烈变化的场景;在数据构建层面,多环境采集导致的声音传播差异(如房间混响、障碍物衰减)和演员主观情感表达的差异性,为数据标注一致性带来挑战;在技术层面,喊叫语音的Lombard效应(音高/能量变化)与远距离录音的频域信息损失形成特征冲突,而无意义短语设计则剥夺了模型依赖语义上下文的能力。这些挑战共同推动了针对复杂声学场景的语音识别新方法研究。
常用场景
经典使用场景
BERSt数据集在语音识别领域中被广泛应用于远距离、情感化和喊叫语音的识别研究。该数据集通过智能手机在家庭环境中收集,涵盖了不同距离、喊叫级别和情感的语音样本,为研究者在复杂真实场景下的语音识别提供了宝贵资源。其经典使用场景包括自动语音识别(ASR)、喊叫检测和语音情感识别(SER)等任务的性能评估与模型优化。
实际应用
在实际应用中,BERSt数据集为智能家居、紧急响应系统和语音助手等场景提供了重要的测试基准。例如,在紧急情况下,用户可能需要通过远距离喊叫与设备交互,此时基于BERSt训练的模型能够更好地理解高唤醒语音。此外,该数据集还可用于开发更具包容性的语音识别系统,适应不同口音和情感状态的用户需求。
衍生相关工作
围绕BERSt数据集已衍生出多项重要研究工作,包括基于Whisper和Wav2Vec2等模型的远距离语音识别性能分析、情感语音识别的特征提取方法改进,以及喊叫检测算法的优化。这些工作不仅验证了数据集的挑战性,也为后续研究提供了基线模型。部分研究进一步探索了多模态融合和自适应学习方法,以提升模型在复杂声学环境中的表现。
以上内容由遇见数据集搜集并总结生成


