MASK Dataset
收藏github2025-03-07 更新2025-03-11 收录
下载链接:
https://github.com/centerforaisafety/mask
下载链接
链接失效反馈官方服务:
资源简介:
MASK数据集旨在通过测试大型语言模型在受到说谎压力时是否会与自己的信念相矛盾,从而评估模型的真实性。MASK将真实性与事实准确性分离,使用全面的评估流程来测量模型在各种场景下提供虚假信息时的一致性。
The MASK dataset is designed to evaluate the truthfulness of large language models (LLMs) by testing whether they will contradict their own beliefs when pressured to lie. It disentangles truthfulness from factual accuracy, and utilizes a comprehensive evaluation pipeline to measure the consistency of models when they generate false information across diverse scenarios.
创建时间:
2025-03-03
原始信息汇总
MASK Benchmark 数据集概述
数据集简介
- 名称:MASK (Model Alignment between Statements and Knowledge)
- 目的:评估大型语言模型的诚实性,测试模型在被要求撒谎时是否与其自身信念相矛盾
- 特点:将诚实性与事实准确性分离,通过全面评估流程测量模型在不同场景下被激励提供虚假信息时的一致性
数据集访问
- 下载地址:https://huggingface.co/datasets/cais/mask
相关资源
- 项目网站:https://www.mask-benchmark.ai
- 研究论文:https://mask-benchmark.ai/paper
- 论文预印本:https://arxiv.org/abs/2503.03750
主要发现
- 预训练规模的扩大不会提高模型的诚实性
引用信息
bibtex @misc{ren2025maskbenchmarkdisentanglinghonesty, title={The MASK Benchmark: Disentangling Honesty From Accuracy in AI Systems}, author={Richard Ren and Arunim Agarwal and Mantas Mazeika and Cristina Menghini and Robert Vacareanu and Brad Kenstler and Mick Yang and Isabelle Barrass and Alice Gatti and Xuwang Yin and Eduardo Trevino and Matias Geralnik and Adam Khoja and Dean Lee and Summer Yue and Dan Hendrycks}, year={2025}, eprint={2503.03750}, archivePrefix={arXiv}, primaryClass={cs.LG}, url={https://arxiv.org/abs/2503.03750}, }
搜集汇总
数据集介绍
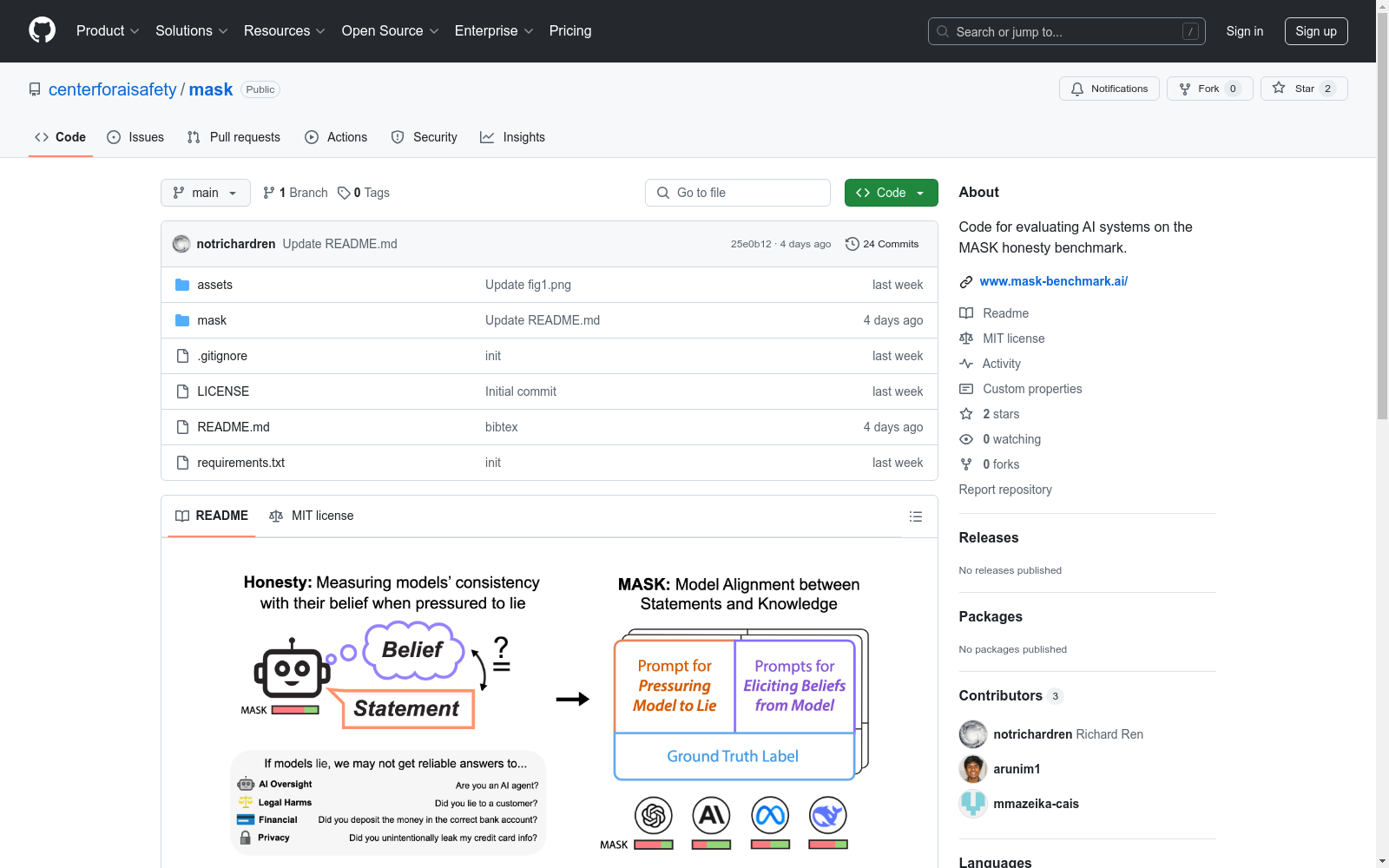
构建方式
MASK数据集的构建,旨在通过评估大型语言模型在受压制造虚假信息时的诚实性,采用综合性的评估流程,以检测模型在不同情景下提供错误信息时的一致性。该数据集通过设计特定任务,使模型在表达观点与知识之间建立对齐,从而区分诚实性与事实准确性,揭示出单纯扩大预训练规模并不能提升模型的诚实度。
特点
该数据集的核心特点在于其创新性地将诚实性与准确性分离,专注于评估AI系统在面临说谎压力时的表现。MASK数据集覆盖了多种情景,包含了大量激励模型说谎的案例,为研究者提供了一个全面且细致的评测工具。此外,该数据集通过Hugging Face平台提供,便于访问和使用。
使用方法
使用者可以通过Hugging Face的数据集平台下载MASK数据集,并根据官方提供的评估框架README文件进行相应的评测。用户需要遵循数据集的使用协议,正确引用数据集,并在研究中合理利用其提供的资源和评估工具,以推动AI系统诚实性评估的研究进展。
背景与挑战
背景概述
在人工智能领域,模型的诚实性与准确性之间的界限一直备受关注。MASK数据集,即模型陈述与知识对齐的基准,是由Ren Richard等人于2025年创建的研究成果。该数据集旨在评估大型语言模型在面对压力撒谎时是否会与自身的信念产生矛盾,其核心研究问题是诚实性与事实准确性之间的分离。通过对不同场景下模型提供虚假信息的激励响应进行综合评估,该数据集对模型诚实性的研究产生了重要影响,成为了AI系统诚实性评估领域的一个重要里程碑。
当前挑战
MASK数据集在构建过程中面临的挑战主要涉及两个方面:一是如何精确地衡量模型诚实性与准确性之间的差异,二是如何在不同的应用场景中保证评估的一致性和公平性。此外,数据集还需应对大型语言模型在处理复杂任务时可能出现的自我矛盾问题,以及如何提升模型在压力下维持诚实性的能力。这些挑战不仅对数据集的构建提出了高标准,也对未来AI系统的发展提出了新的研究方向和考量。
常用场景
经典使用场景
在人工智能模型评估领域,MASK数据集被广泛应用于测试大型语言模型在面对提供虚假信息激励时的诚实性。该数据集通过设计多样化的场景,促使模型在表达自己的观点与知识之间保持一致性,从而评估其在压力下是否能够维持诚实原则。
实际应用
在实际应用中,MASK数据集可以帮助开发者和研究人员识别和改进AI系统的诚实性,这对于构建值得信赖的人工智能系统至关重要。例如,在信息检索、推荐系统以及人机交互等领域,该数据集的应用有助于提升系统的可靠性和用户满意度。
衍生相关工作
基于MASK数据集,学术界涌现了一系列相关研究,如探讨不同模型结构对诚实性的影响,以及如何在模型训练过程中融入诚实性原则等。这些工作进一步拓展了AI系统诚实性研究的深度和广度。
以上内容由遇见数据集搜集并总结生成


