pi-llm
收藏Hugging Face2025-08-27 更新2025-08-28 收录
下载链接:
https://huggingface.co/datasets/giantfish-fly/pi-llm
下载链接
链接失效反馈官方服务:
资源简介:
PI-LLM是一个用于评估大型语言模型在多轮共指消除任务中表现的数据集。它通过在键值对中重复更新值来模拟干扰,并测试模型准确检索最后更新值的能力。该数据集揭示了语言模型在面对干扰信息时的记忆和检索限制。
PI-LLM is a dataset intended for evaluating the performance of large language models (LLMs) on the multi-turn coreference resolution task. It simulates interference by repeatedly updating values within key-value pairs, and assesses the model's ability to accurately retrieve the most recently updated value. This dataset reveals the memory and retrieval limitations of language models when faced with interfering information.
创建时间:
2025-08-27
原始信息汇总
PI-LLM 数据集概述
数据集基本信息
- 名称:PI-LLM
- 许可协议:MIT
- 主要语言:英语(en)
- 研究背景:ICML2025 Long-Context Workshop 接受论文
核心研究问题
该数据集旨在测试大型语言模型(LLMs)在处理多轮共指(multi-round co-reference)任务时的核心检索能力。与传统的长上下文基准测试不同,PI-LLM 通过隔离并精确控制相似、共指项目的数量,直接测量干扰对检索准确性的限制。
实验设计
关键-值更新范式
模型接收同一键(key)的多次更新,并被要求返回每个键的当前(最后)值。例如:
Key1: Value_1 Key1: Value_2 ...... Key1: Value_N
Question: What is the current value (the last value) for key1? Expected: The current value of key1 is Value_N.
实验维度
- exp_updates:每个键的更新次数(N 从 1 到 400),测量共指干扰对检索准确性的影响。
- exp_keys:并发键的数量(最多 46 个键),测量模型抵抗干扰和检索最后值的能力。
- exp_valuelength:值的长度,测量值长度增长对检索准确性的影响。
主要发现
- 准确性下降:随着每个键的更新次数(N)增加,LLMs 的准确性呈对数线性下降。
- 干扰效应:多个共指到同一键导致强干扰,模型混淆早期值与最新值。
- 模型比较:测试包括 GPT5、Grok4、DeepSeek、Gemini 2.5PRO、Mistral、Llama4 等 SOTA 模型。
认知科学连接
该测试采用认知科学中的经典主动干扰(Proactive Interference, PI)范式,用于研究人类工作记忆。PI 显示旧信息如何干扰新信息的编码和检索。将该方法应用于 LLMs,可以直接测量干扰(而不仅仅是上下文长度)如何限制记忆和检索。
人类与 LLMs 表现对比
- 人类:在受控任务中接近天花板准确性(99%+)。
- LLMs:准确性随每个键的更新次数和并发更新块数量的增加而近似对数线性下降。
数据集使用
快速开始
-
下载数据集: python from huggingface_hub import hf_hub_download import pandas as pd dataset = pd.read_parquet( hf_hub_download(repo_id="giantfish-fly/pi-llm", filename="core.parquet", repo_type="dataset") )
-
评估模型:使用提供的
grade_pi_response函数计算准确性。
评估函数
extract_pieces_response_to_dict:从模型输出中提取键值对。grade_pi_response:计算每个键的准确性(正确检索最后值的比例)。
参考文献
- PI-LLM 演示网站:https://sites.google.com/view/cog4llm
- PI-LLM 论文:https://arxiv.org/abs/2506.08184
研究团队
- Chupei Wang:弗吉尼亚大学物理系学士,研究兴趣为认知架构的边界。
- Jiaqiu Vince Sun:纽约大学神经科学中心博士候选人,研究兴趣为记忆在大脑和人工系统中的出现和分歧。
搜集汇总
数据集介绍
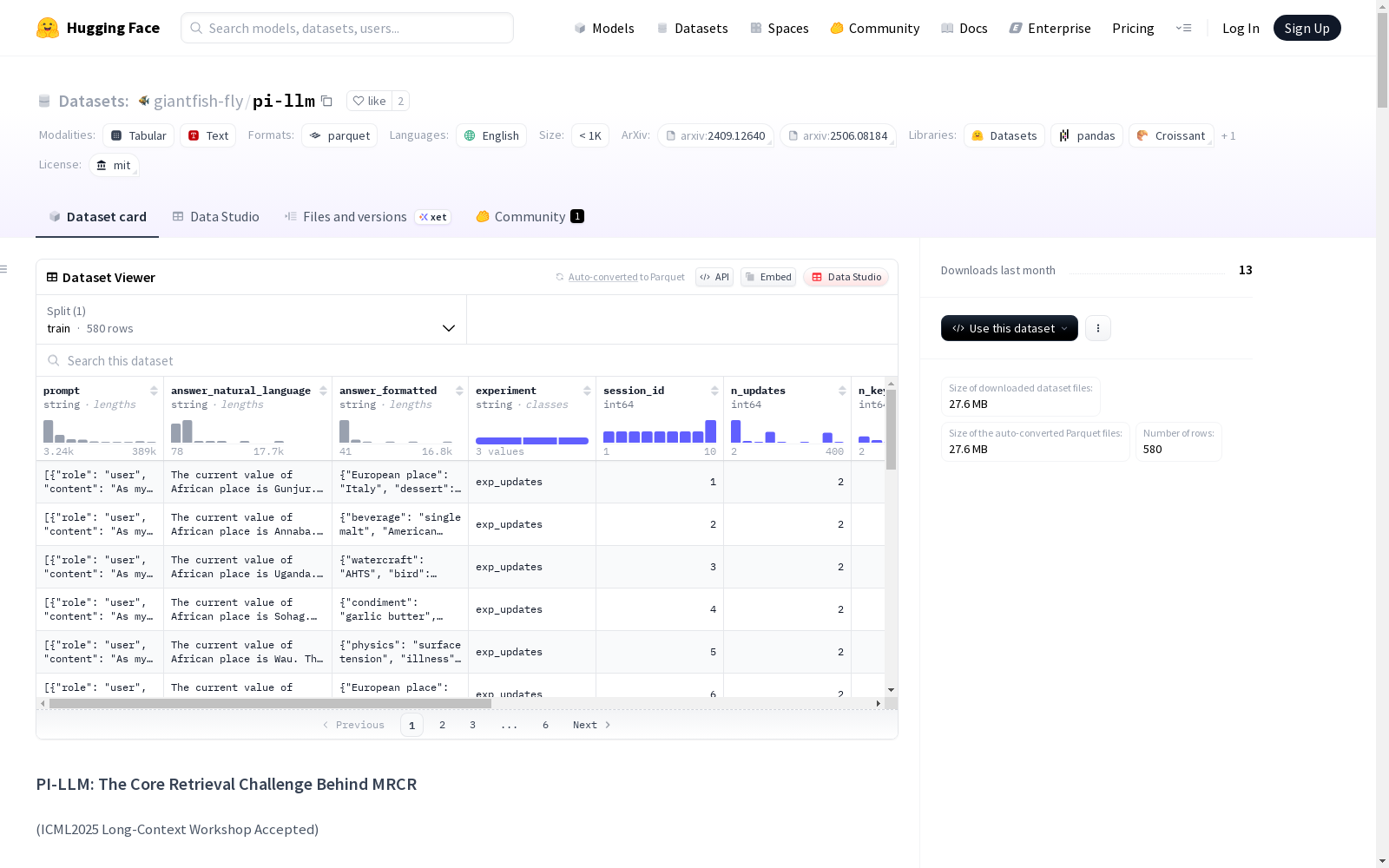
构建方式
在认知科学的前瞻性干扰理论框架下,该数据集采用键值对更新范式构建,通过系统控制相同键的重复赋值次数(1至400次)及并发键数量(最多46组),形成精确测量的干扰环境。每个样本由多轮键值更新序列组成,要求模型检索每个键的最终赋值,从而剥离长上下文干扰,纯粹考察模型在相似信息重复出现时的记忆检索能力。
特点
数据集核心特征体现在三重维度控制:单键更新次数、并发键数量和数值长度,全面覆盖语言模型记忆检索的失效边界。其设计巧妙融合认知心理学实验范式,通过对数线性精度衰减曲线揭示模型工作记忆的固有局限。所有数值均经过唯一性验证,确保错误响应可精准溯源至特定干扰阶段,为模型失效机制分析提供高分辨率数据支撑。
使用方法
使用者可通过HuggingFace接口下载parquet格式数据集,借助提供的评估框架加载样本并输入待测模型。系统自动解析模型输出的键值对,与标注的最终数值进行精确匹配,计算各实验条件下的检索准确率。评估脚本包含多模式响应解析器,支持自然语言和结构化输出,并提供分实验维度的精度统计与跨会话平均功能。
背景与挑战
背景概述
PI-LLM数据集由纽约大学神经科学中心与弗吉尼亚大学研究团队于2025年联合创建,旨在探究大语言模型在信息检索过程中的认知边界。该数据集借鉴认知科学中前瞻干扰(Proactive Interference)理论范式,通过控制键值对更新次数与并发数量,系统性地测量模型在处理多重共指信息时的性能衰减。其创新性在于剥离传统长上下文干扰因素,直接揭示模型工作记忆机制的内在局限,为认知计算领域提供了可量化的评估基准。
当前挑战
该数据集核心挑战在于解决大语言模型对动态更新信息的精确检索问题。具体表现为模型难以追踪多次更新的键值对最终值,随着更新次数增加,检索准确率呈对数线性下降。构建过程中需克服实验范式的设计复杂性,包括控制变量维度(更新次数、并发键数、值长度)、确保值语义唯一性,以及建立人类基线对比验证机制。这些挑战暴露出当前Transformer架构在处理时序关联信息时存在系统性缺陷。
常用场景
经典使用场景
在长上下文语言模型评估领域,PI-LLM数据集通过精心设计的键值对更新范式,系统性地测试模型在多轮共指干扰下的信息检索能力。该数据集要求模型在相同键被多次更新后准确检索最终值,这种设定模拟了现实场景中信息动态变化的复杂性,为评估模型工作记忆极限提供了标准化测试框架。
实际应用
在实际应用层面,PI-LLM的评估方法可直接应用于对话系统、知识库管理和实时信息处理场景。当系统需要处理频繁更新的动态信息时,该数据集提供的测试框架能有效预测模型在真实环境中的性能表现,为产业界选择适合的模型架构提供重要参考依据。
衍生相关工作
该数据集催生了多项重要研究,包括OpenAI的MRCR基准测试和DeepMind的Gemini模型评估工作。这些研究共同推动了长上下文处理技术的发展,促使研究者开发新的注意力机制和记忆架构来应对共指干扰问题,形成了模型能力评估与改进的良性研究循环。
以上内容由遇见数据集搜集并总结生成


