go_emotions_speech_rp-large-en
收藏Hugging Face2025-03-21 更新2025-03-22 收录
下载链接:
https://huggingface.co/datasets/Bakanayatsu/go_emotions_speech_rp-large-en
下载链接
链接失效反馈官方服务:
资源简介:
这是一个英文文本分类数据集,包含合成文本,大小在100K到1M之间。数据集由纯语音和角色扮演文本组成,建议使用数据集的前1%和后1%作为测试集。数据集未去重,并且可以与'Bakanayatsu/go_emotions_speech-lite-en'数据集结合使用。
This is an English text classification dataset composed of synthetic text, with a total of 100K to 1M samples. The dataset consists of pure speech transcripts and role-playing texts. It is recommended to use the top 1% and bottom 1% of the dataset as the test set. The dataset is undeduplicated and can be used in conjunction with the 'Bakanayatsu/go_emotions_speech-lite-en' dataset.
创建时间:
2025-03-21
搜集汇总
数据集介绍
构建方式
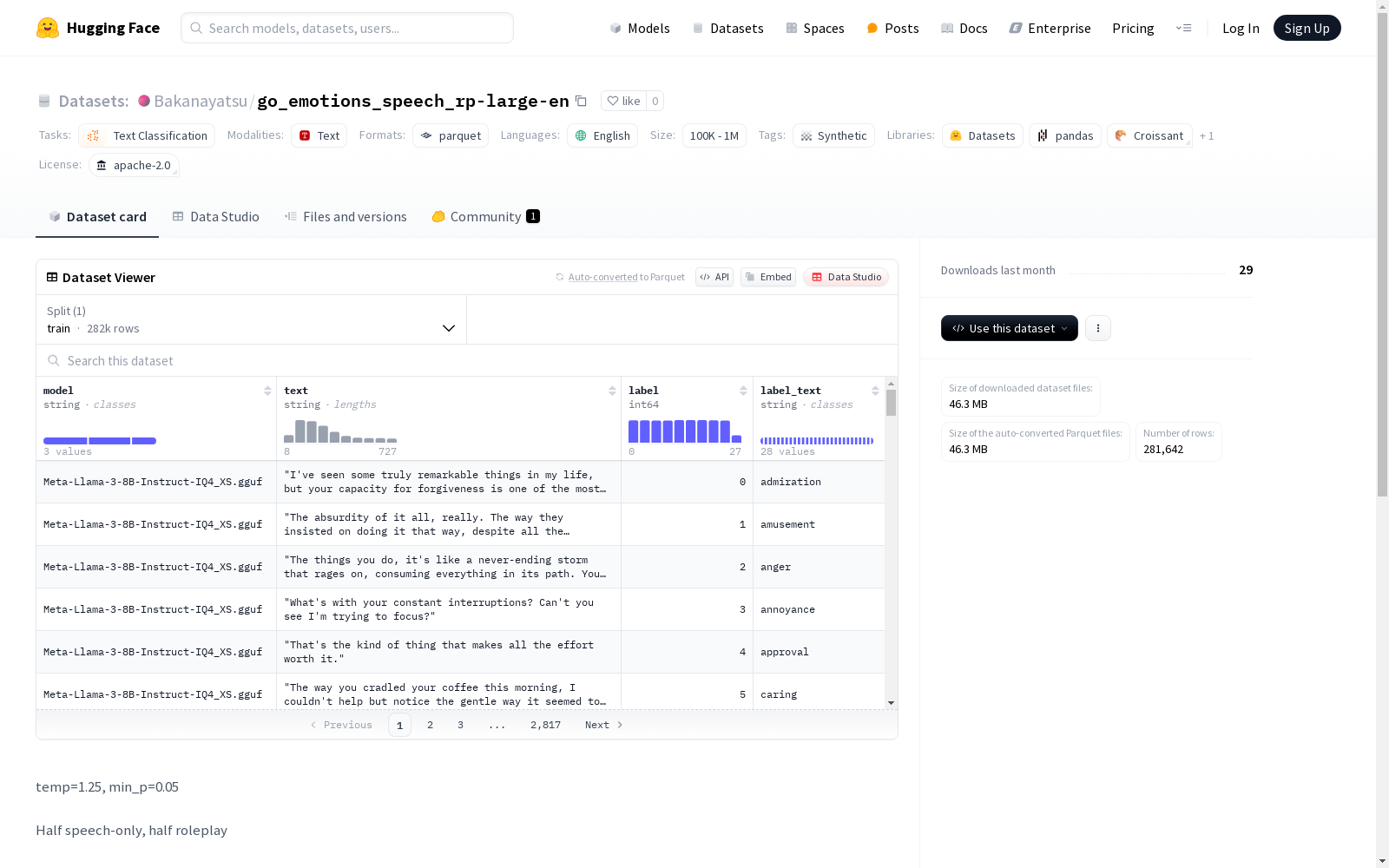
go_emotions_speech_rp-large-en数据集的构建采用了混合策略,其中一半数据来源于纯语音内容,另一半则通过角色扮演生成。这种独特的构建方式旨在捕捉多样化的情感表达,尤其是在不同情境下的语音情感变化。数据集的生成过程中,使用了特定的参数设置(如temp=1.25, min_p=0.05),以确保生成内容的多样性和质量。此外,数据集未进行去重处理,保留了原始数据的丰富性和复杂性。
特点
该数据集的特点在于其规模较大,包含超过10万条但不足100万条数据条目,涵盖了广泛的语音情感表达。数据集的语言为英语,适用于文本分类任务,尤其是情感分析领域。其独特的混合构建方式使得数据集能够同时反映真实语音和模拟情境下的情感表达,为研究者提供了丰富的实验素材。此外,数据集的测试集建议使用前1%和后1%的数据,这种设计有助于评估模型在不同数据分布下的表现。
使用方法
使用go_emotions_speech_rp-large-en数据集时,可以通过Hugging Face的`datasets`库加载数据。加载后,建议将数据集的前1%和后1%作为测试集,中间98%作为训练集。这种划分方式有助于评估模型在不同数据分布下的泛化能力。此外,该数据集可以与`go_emotions_speech-lite-en`数据集结合使用,以进一步扩展实验的规模和多样性。通过合理的数据划分和组合,研究者可以充分利用该数据集进行情感分析相关的研究和模型训练。
背景与挑战
背景概述
go_emotions_speech_rp-large-en数据集是一个专注于英语情感分类的文本数据集,由Bakanayatsu团队创建并发布。该数据集结合了语音转录文本和角色扮演对话,旨在为情感分析领域提供多样化的数据支持。其核心研究问题在于如何通过大规模、多样化的文本数据,提升情感分类模型的泛化能力和鲁棒性。该数据集的发布为情感计算、自然语言处理等领域的研究者提供了重要的数据资源,推动了情感识别技术的发展。
当前挑战
go_emotions_speech_rp-large-en数据集在构建和应用过程中面临多重挑战。首先,情感分类本身具有高度主观性,如何准确标注情感标签并确保数据质量是一大难题。其次,数据集包含语音转录和角色扮演两种来源的文本,如何平衡两类数据的分布并避免偏差是构建过程中的关键挑战。此外,数据集的规模较大,未进行去重处理,可能导致模型训练时出现冗余数据,影响模型性能。最后,如何有效划分训练集和测试集以评估模型的泛化能力,也是该数据集应用中的一大挑战。
常用场景
经典使用场景
在情感计算领域,go_emotions_speech_rp-large-en数据集被广泛应用于语音情感识别任务。该数据集结合了语音和角色扮演数据,能够有效捕捉到人类语音中的情感变化,为情感识别模型提供了丰富的训练样本。通过该数据集,研究者可以训练出能够准确识别语音中情感状态的模型,进而推动情感计算技术的发展。
解决学术问题
go_emotions_speech_rp-large-en数据集解决了情感计算领域中语音情感识别的关键问题。传统的情感识别模型往往依赖于文本数据,而该数据集通过引入语音数据,弥补了文本数据在情感表达上的不足。此外,数据集中的角色扮演数据进一步丰富了情感表达的多样性,使得模型能够更好地理解和识别复杂的情感状态。
衍生相关工作
基于go_emotions_speech_rp-large-en数据集,研究者们开发了多种情感识别模型和算法。这些工作不仅提升了语音情感识别的准确率,还推动了情感计算领域的进一步发展。例如,一些研究通过结合深度学习和传统机器学习方法,提出了更加高效的情感识别模型。此外,该数据集还被用于跨语言情感识别的研究,为多语言情感计算提供了新的思路。
以上内容由遇见数据集搜集并总结生成


