KOREAson/YiSang-HighQuality
收藏Hugging Face2026-04-04 更新2026-01-03 收录
下载链接:
https://hf-mirror.com/datasets/KOREAson/YiSang-HighQuality
下载链接
链接失效反馈官方服务:
资源简介:
---
license: apache-2.0
task_categories:
- text-generation
language:
- ko
- en
tags:
- reasoning
- chain-of-thought
dataset_info:
features:
- name: instruction
dtype: string
- name: response
dtype: string
splits:
- name: train
num_bytes: 3859604712
num_examples: 283687
download_size: 1734927587
dataset_size: 3859604712
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
---
# YiSang-HighQuality
<p align="center">
📖 Check out the KO-REAson <a href="https://arxiv.org/abs/2510.04230" target="_blank">technical report</a>.
<br>
📍 Rest of the model and datasets are available <a href="https://huggingface.co/KOREAson">here. </a>
</p>
**YiSang-HighQuality** is a collection of ~280K long-CoT reasoning traces generated via [Qwen3-32B](https://huggingface.co/Qwen/Qwen3-32B). This dataset is a high-yield subset of the larger Yi-Sang collection, designed to enhance multilingual reasoning through **Language-Mixed Chain-of-Thought (CoT)**, which switches between English and Korean to minimize translation artifacts while leveraging English as a reasoning anchor.
This is the dataset used to train our KOREAson-0831 and 1009 series.
## Family Details
The **KO-REAson** release includes nine models and three datasets.
| Model (link) | Licence | Note |
| -------------------------------------------------------------------------------------------- | -------------------- | ------------------- |
| [KO-REAson-AX3_1-35B-1009](https://huggingface.co/KOREAson/KO-REAson-AX3_1-35B-1009) | Apache 2.0 | **Our BEST Model** |
| [YiSang-HighQuality](https://huggingface.co/datasets/KOREAson/YiSang-HighQuality) | Apache 2.0 | **Dataset used for Training** |
## Citation
```bibtex
@article{son2025pushing,
title={Pushing on Multilingual Reasoning Models with Language-Mixed Chain-of-Thought},
author={Son, Guijin and Yang, Donghun and Patel, Hitesh Laxmichand and Agarwal, Amit and Ko, Hyunwoo and Lim, Chanuk and Panda, Srikant and Kim, Minhyuk and Drolia, Nikunj and Choi, Dasol and others},
journal={arXiv preprint arXiv:2510.04230},
year={2025}
}
```
## Contact
For any questions contact us via the following email :)
```
spthsrbwls123@yonsei.ac.kr
```
license: apache-2.0
许可证:Apache 2.0
task_categories:
任务类别:
- text-generation
- 文本生成
language:
语言:
- ko
- 韩语
- en
- 英语
tags:
标签:
- reasoning
- 推理
- chain-of-thought
- 思维链(Chain-of-Thought)
dataset_info:
数据集信息:
features:
特征项:
- name: instruction
字段名:指令
数据类型:字符串
- name: response
字段名:回复
数据类型:字符串
splits:
数据划分:
- name: train
名称:训练集
字节数:3859604712
样本数:283687
download_size: 下载大小:1734927587
dataset_size: 数据集总大小:3859604712
configs:
配置项:
- config_name: default
配置名称:默认配置
data_files:
数据文件:
- split: train
数据划分:训练集
path: data/train-*
文件路径:data/train-*
# YiSang-HighQuality 数据集
<p align="center">
📖 查阅<a href="https://arxiv.org/abs/2510.04230" target="_blank">KO-REAson技术报告</a>。
<br>
📍 其余模型与数据集可于<a href="https://huggingface.co/KOREAson">此处</a>获取。
</p>
**YiSang-HighQuality** 是一个包含约28万条长思维链(Chain-of-Thought, CoT)推理轨迹的数据集,由[Qwen3-32B](https://huggingface.co/Qwen/Qwen3-32B)生成。该数据集是更大规模Yi-Sang数据集集合的高价值子集,旨在通过**混合语言思维链(Language-Mixed Chain-of-Thought)** 增强多语言推理能力:该方法在英语与韩语之间切换,以英语作为推理锚点,最大限度减少翻译伪影。
本数据集用于训练我们的KOREAson-0831与1009系列模型。
## 系列详情
**KO-REAson** 发布套件包含9个模型与3个数据集。
| 模型(链接) | 许可证 | 备注 |
| -------------------------------------------------------------------------------------------- | -------------------- | ------------------- |
| [KO-REAson-AX3_1-35B-1009](https://huggingface.co/KOREAson/KO-REAson-AX3_1-35B-1009) | Apache 2.0 | **我们的最优模型** |
| [YiSang-HighQuality](https://huggingface.co/datasets/KOREAson/YiSang-HighQuality) | Apache 2.0 | **训练所用数据集** |
## 引用
bibtex
@article{son2025pushing,
title={Pushing on Multilingual Reasoning Models with Language-Mixed Chain-of-Thought},
author={Son, Guijin and Yang, Donghun and Patel, Hitesh Laxmichand and Agarwal, Amit and Ko, Hyunwoo and Lim, Chanuk and Panda, Srikant and Kim, Minhyuk and Drolia, Nikunj and Choi, Dasol and others},
journal={arXiv preprint arXiv:2510.04230},
year={2025}
}
## 联系方式
如有任何疑问,请通过以下邮箱联系我们:
spthsrbwls123@yonsei.ac.kr
提供机构:
KOREAson
搜集汇总
数据集介绍
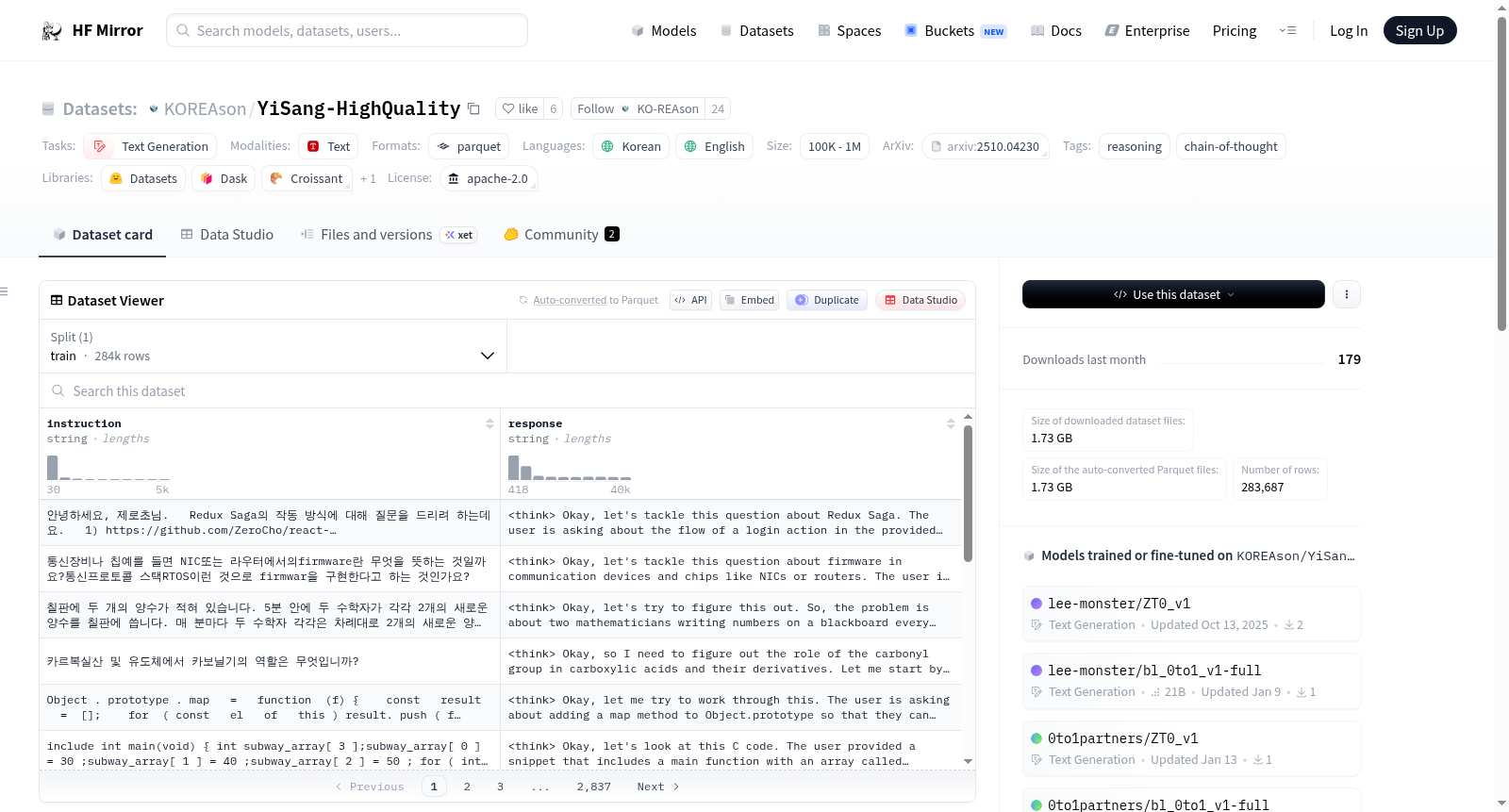
构建方式
在自然语言处理领域,高质量推理数据的构建对提升模型的多语言思维链能力至关重要。YiSang-HighQuality数据集通过Qwen3-32B模型生成约28.3万条长链思维轨迹,作为大规模Yi-Sang集合的高质量子集,其构建过程专注于语言混合的思维链方法,在英语和韩语之间灵活切换,以减少翻译过程中的语义失真,同时以英语作为推理的锚点,确保逻辑连贯性。
特点
该数据集的核心特点在于其语言混合的思维链设计,通过交替使用英语和韩语,有效避免了单一语言翻译可能引入的偏差,从而提升了多语言推理的纯净度。数据集包含指令与响应两个关键字段,结构清晰,专为训练高级推理模型而优化,已成功应用于KO-REAson系列模型的开发,体现了其在增强模型跨语言逻辑能力方面的独特价值。
使用方法
在模型训练与应用中,YiSang-HighQuality数据集主要用于微调或预训练阶段,以强化模型的多语言推理性能。研究人员可直接从HuggingFace平台下载该数据集,利用其指令-响应对进行监督学习,特别适用于需要处理韩语和英语混合场景的思维链任务,为构建如KO-REAson-0831等先进模型提供可靠的数据支撑。
背景与挑战
背景概述
在人工智能领域,提升大语言模型的多语言推理能力是当前研究的前沿课题。YiSang-HighQuality数据集由韩国延世大学等机构的研究团队于2025年创建,作为KO-REAson项目的重要组成部分,其核心研究问题聚焦于通过语言混合的思维链技术来优化模型在韩语和英语语境下的复杂推理表现。该数据集从更广泛的Yi-Sang集合中精选出约28万条高质量推理轨迹,旨在减少翻译过程中的语义失真,同时以英语作为推理锚点来增强跨语言逻辑一致性,为多语言推理模型的训练提供了关键数据支撑,显著推动了相关领域的技术发展。
当前挑战
该数据集致力于应对多语言复杂推理任务中的核心挑战,即如何在韩语和英语混合的语境下,保持思维链的逻辑连贯性与语义准确性,避免因语言切换导致的推理断层或信息损失。在构建过程中,研究团队面临的主要挑战包括:从海量原始数据中筛选出高质量、高信息密度的推理样本,确保每条思维链都能有效体现跨语言推理的深度;同时,需精细设计语言混合策略,以平衡两种语言在推理过程中的角色,最小化翻译伪影,这对数据标注的严谨性与算法设计的精确性提出了极高要求。
常用场景
经典使用场景
在自然语言处理领域,推理能力的提升是推动模型智能化的核心挑战之一。YiSang-HighQuality数据集以其约28万条长链思维推理轨迹,为训练大规模语言模型提供了高质量的监督数据。该数据集最经典的使用场景在于支持语言混合的思维链生成,通过交替使用英语和韩语,模型能够在多语言环境中进行复杂推理,有效减少翻译过程中的信息损失,从而增强模型在数学、逻辑和常识推理任务中的表现。
衍生相关工作
围绕YiSang-HighQuality数据集,学术界和工业界衍生了一系列经典研究工作。最突出的成果是KO-REAson模型系列,这些模型利用该数据集进行训练,在多语言推理基准测试中展现了卓越性能。相关技术报告《Pushing on Multilingual Reasoning Models with Language-Mixed Chain-of-Thought》系统阐述了语言混合思维链的理论与实践,为后续研究提供了重要参考,并激励了更多关于跨语言数据合成和模型优化的探索。
数据集最近研究
最新研究方向
在自然语言处理领域,多语言推理模型的性能提升是当前研究的前沿焦点。YiSang-HighQuality数据集通过语言混合思维链技术,巧妙融合英语和韩语,旨在减少翻译过程中的信息损失,同时利用英语作为推理锚点,为模型训练提供了高质量的多语言推理轨迹。这一方法不仅响应了全球化背景下对跨语言人工智能系统的迫切需求,还推动了如KO-REAson系列模型的发展,相关技术报告已在学术社区引发广泛讨论,为多语言推理任务的基准测试和实际应用奠定了重要基础,促进了人工智能在复杂逻辑处理中的泛化能力。
以上内容由遇见数据集搜集并总结生成


