FontAdapter Dataset
收藏arXiv2025-06-06 更新2025-06-11 收录
下载链接:
https://fontadapter.github.io/
下载链接
链接失效反馈官方服务:
资源简介:
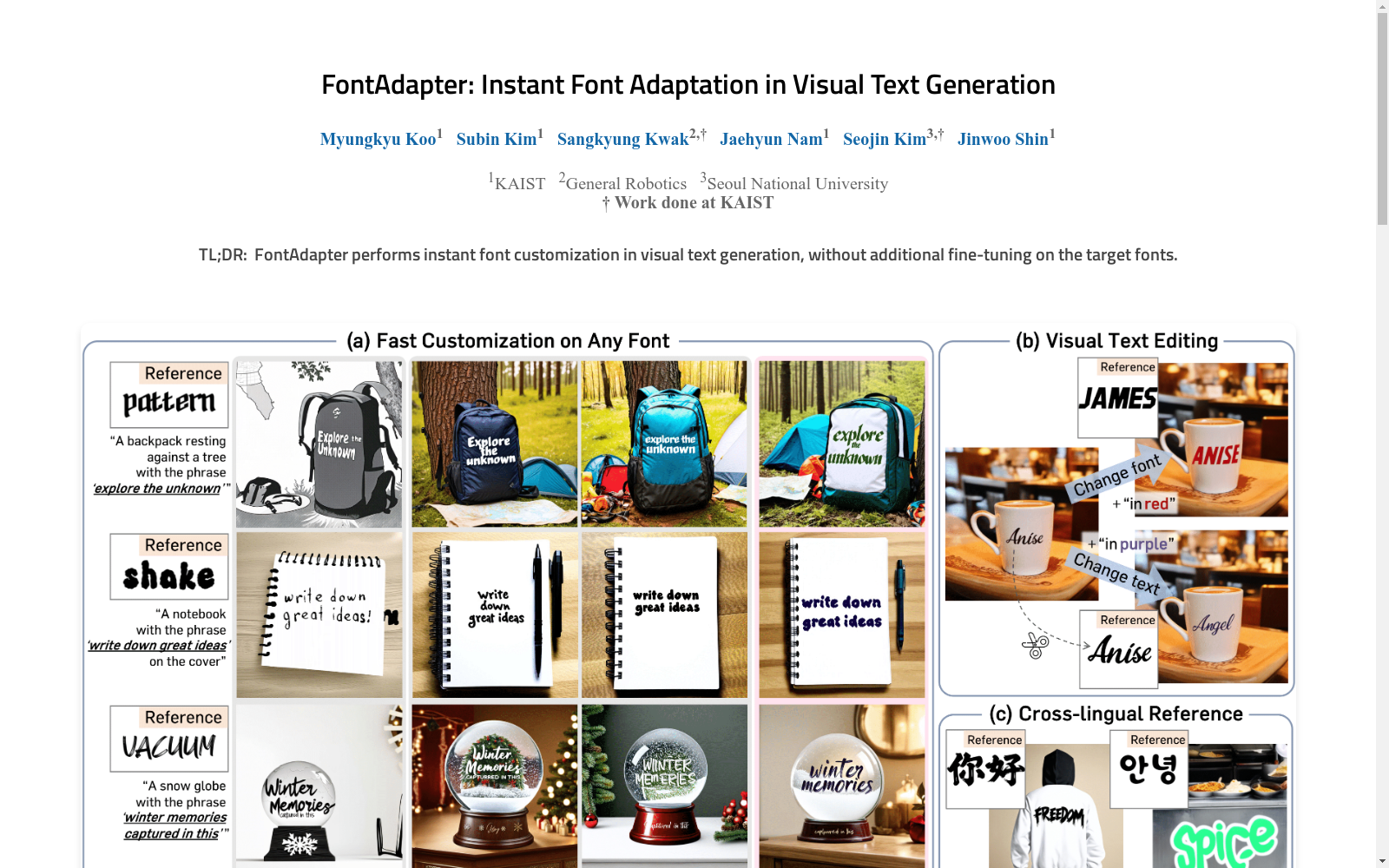
FontAdapter数据集是专为FontAdapter框架设计的合成数据集,用于视觉文本生成中的即时字体适应。该数据集分为两个阶段:第一阶段包含仅文本的图像,用于提取字体属性;第二阶段包含场景文本图像,用于将提取的字体风格集成到复杂的背景中。通过使用大规模在线字体,该数据集支持FontAdapter学习并适应各种字体风格,从而在视觉文本生成中实现高质量的字体定制。
The FontAdapter dataset is a synthetic dataset specifically designed for the FontAdapter framework, targeting instant font adaptation in visual text generation. This dataset is divided into two stages: the first stage consists of text-only images for font attribute extraction, while the second stage contains scene text images used to integrate the extracted font styles into complex backgrounds. By leveraging large-scale online fonts, this dataset enables FontAdapter to learn and adapt to various font styles, thereby achieving high-quality font customization in visual text generation.
提供机构:
韩国科学技术院(KAIST)
创建时间:
2025-06-06
搜集汇总
数据集介绍
构建方式
在视觉文本生成领域,FontAdapter数据集的构建采用了创新的两阶段课程学习策略。针对传统方法难以捕捉细微字体属性的局限,研究团队首先构建了专注于孤立字形提取的纯文本数据集(黑色字形置于白色背景),以消除复杂背景的干扰;随后开发了场景文本数据集,将着色后的字形自然融入由Stable Diffusion 3生成的多样化现实背景中。通过在线大规模字体资源的系统化利用,两个阶段分别生成15,000组纯文本图像和场景文本图像,并采用人工标注的边界框确保文本精确嵌入。这种阶段特异性数据集构建方法,配合SDEdit视觉增强和专家模型精修流程,显著提升了合成数据的真实性与域适应能力。
特点
该数据集的核心特征体现在其多层次的架构设计上。纯文本子集通过极简的视觉环境(黑白对比)强化模型对字形细节的捕捉能力,而场景文本子集则通过GPT-4o生成的语义化背景提示语,构建了500种包含精确文本定位坐标的复杂场景。数据集特别设计了参考-目标文本内容差异化的配对机制,确保模型学习内容无关的字体属性迁移能力。定量评估显示,数据集支持模型在Max-IoU(0.4293)、HOG相似度(0.6138)等字体相似度指标上显著超越基线方法,同时维持0.7904的标准化编辑距离(NED),证明其在保持文本准确性方面的优势。跨语言字体迁移等衍生功能的实现,进一步验证了数据集构建的鲁棒性。
使用方法
使用该数据集需遵循其两阶段训练范式。第一阶段利用纯文本子集训练Resampler模块和图像-图像注意力层,专注字体属性提取;第二阶段冻结Resampler并采用场景文本子集,仅优化注意力层以实现字体风格与复杂背景的融合。评估时需通过TexRNet文本分割和HRNet对齐构建标准化流程,采用多维度指标体系:字体相似度(Max-IoU/HOG)、文本准确性(PP-OCRv3识别)、提示对齐度(CLIP/SigLIP分数)。对于特定应用如视觉文本编辑,可结合SDEdit实现文本内容/字体的动态修改;字体混合功能则通过线性插值图像提示token实现。注意需保持评估字体与训练集的非重叠性,并遵循论文提供的300字体/1000单词的基准划分。
背景与挑战
背景概述
FontAdapter Dataset由KAIST、General Robotics和首尔国立大学的研究团队于2025年6月发布,旨在解决视觉文本生成中的字体即时适配问题。该数据集基于大规模在线字体资源构建,通过两阶段课程学习框架(字体属性提取与场景文本合成)突破传统微调方法的高计算成本瓶颈,支持11秒内完成新字体适配。其创新性体现在合成数据集的阶段化设计:首阶段采用白底黑字的纯净字形数据,次阶段生成自然场景嵌入的彩色文本,为多语言字体迁移、文本编辑等任务建立了新基准。
当前挑战
核心挑战聚焦于两个维度:领域问题方面,需克服扩散模型对预设字体集的依赖,实现参考图像驱动的任意字体风格迁移,同时解决字形结构保持与复杂背景融合的兼容性问题;构建过程方面,面临合成数据真实性不足的局限——单纯渲染的文本缺乏自然光影和材质交互,为此团队引入SDEdit后处理与专家模型精修策略,通过最大IoU>0.59与HOG相似度>0.80的联合过滤标准确保数据质量。此外,两阶段训练中需精确平衡字体特征提取模块(Resampler)与背景融合模块的优化时序,避免特征退化。
常用场景
经典使用场景
FontAdapter数据集在视觉文本生成领域具有广泛的应用场景,特别是在需要快速适应未见过的字体风格时。该数据集通过两阶段课程学习方案,首先从孤立字形中提取字体属性,然后将这些风格整合到多样化的自然背景中。这种设计使得FontAdapter能够在几秒钟内完成对新字体的适配,而无需额外的微调,极大地提高了字体定制的效率和实用性。
衍生相关工作
FontAdapter数据集衍生了一系列相关经典工作,主要集中在字体生成和视觉文本渲染领域。例如,DiffSTE和Glyph-ByT5等研究利用预定义字体集进行微调,实现了字体条件文本编辑和控制设计文本生成。此外,IP-Adapter及其扩展工作通过图像提示适配器,进一步提升了模型在字体风格定制方面的表现。这些工作共同推动了视觉文本生成技术的发展。
数据集最近研究
最新研究方向
近年来,视觉文本生成领域取得了显著进展,特别是在文本到图像扩散模型的应用方面。FontAdapter数据集的提出,为解决未见字体的即时适配问题提供了创新解决方案。该数据集通过两阶段课程学习策略,首先从孤立字形中提取字体属性,随后将这些风格融入多样化自然背景中,显著提升了字体风格的自定义生成效率和质量。这一研究方向与当前个性化内容生成的热点紧密相关,尤其在广告设计、品牌定制和多媒体内容创作等领域具有广泛的应用潜力。FontAdapter的推出不仅大幅降低了计算成本,还支持视觉文本编辑、字体风格混合和跨语言字体转换等高级功能,为视觉文本生成领域树立了新的技术标杆。
相关研究论文
- 1FontAdapter: Instant Font Adaptation in Visual Text Generation韩国科学技术院(KAIST) · 2025年
以上内容由遇见数据集搜集并总结生成


