soar_arc_train_5M
收藏Hugging Face2025-06-24 更新2025-06-25 收录
下载链接:
https://huggingface.co/datasets/julien31/soar_arc_train_5M
下载链接
链接失效反馈官方服务:
资源简介:
SOAR-ARC模型是一个自我改进的语言模型,用于程序合成。该模型通过创建一个进化搜索和学习的良性循环,使得AI模型能够从自己的经验中学习,不断提高能力,解决之前无法解决的问题。数据集包含了大约500万个ARC解决方案,确保了多样性和高质量,可用于进一步的研究和开发。
The SOAR-ARC model is a self-improving language model designed for program synthesis. This model establishes a virtuous cycle of evolutionary search and learning, enabling the AI model to learn from its own experience, continuously enhance its capabilities, and solve problems that were previously unsolvable. The dataset contains approximately 5 million ARC solutions, ensuring diversity and high quality, and is available for further research and development.
创建时间:
2025-06-20
搜集汇总
数据集介绍
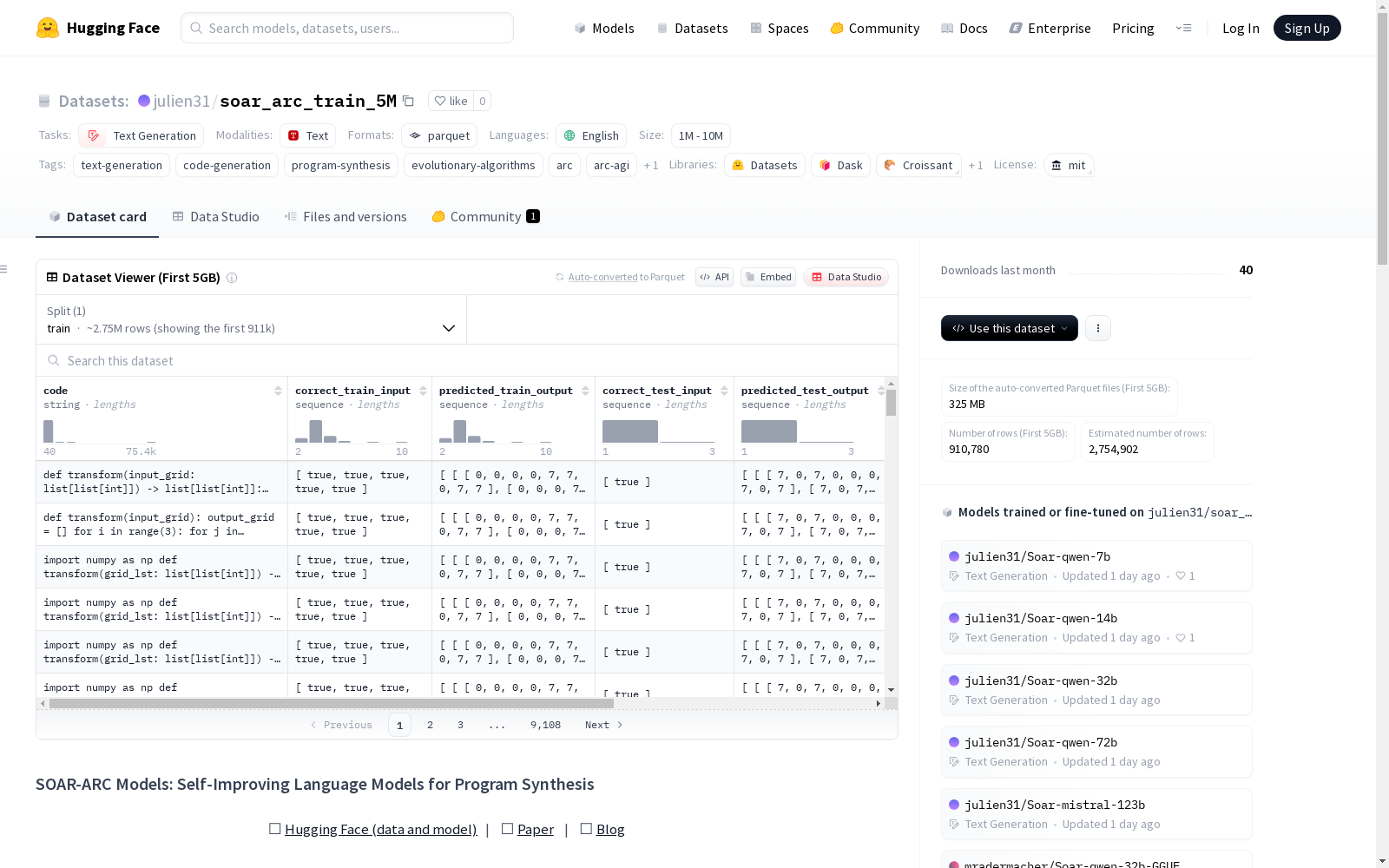
构建方式
在程序合成领域,soar_arc_train_5M数据集的构建采用了创新的演化搜索与自我改进机制。该数据集通过SOAR框架系统性地生成并筛选了约500万条ARC任务解决方案,其中针对原始ARC任务的解决方案通过代码去重确保唯一性,而基于后见重新标记生成的合成任务解决方案则通过输出结果进行去重。这种双重去重策略有效保障了数据集的多样性和高质量特性,为复杂推理任务的研究提供了坚实基础。
特点
作为程序合成领域的突破性资源,该数据集最显著的特点在于其自我改进的演化特性。所有解决方案均源自语言模型在ARC-AGI基准上的自主探索过程,既包含成功案例也整合了失败尝试的转化价值。数据集特别强调Python程序的纯自动化合成能力,摆脱了对人工定义领域特定语言的依赖,完整呈现了从初始采样到迭代优化的全周期演化轨迹,为研究语言模型的自我提升机制提供了独特视角。
使用方法
该数据集主要服务于程序合成与代码生成研究,使用时需配合特定格式的提示模板。研究人员可通过加载训练好的SOAR模型,输入包含ARC任务示例的结构化提示,模型将输出对应的Python解决方案函数。完整的使用流程涉及提示格式化、推理执行、代码验证及结果可视化等环节,具体实施细节可参考官方提供的Jupyter Notebook示例和GitHub仓库中的标准化操作指南。
背景与挑战
背景概述
soar_arc_train_5M数据集由Julien Pourcel、Cédric Colas和Pierre-Yves Oudeyer等研究人员于2025年发布,旨在推动程序合成领域的发展。该数据集包含约500万条Abstraction and Reasoning Corpus(ARC)解决方案,专注于提升语言模型在复杂推理任务中的表现。作为国际机器学习大会(ICML)的推荐研究成果,其核心创新在于SOAR框架,通过进化搜索和自学习机制,使模型能够从自身经验中持续优化,突破传统语言模型在程序合成任务中的瓶颈。这一突破为人工智能在抽象推理和程序生成领域的研究提供了重要数据支撑。
当前挑战
该数据集面临的主要挑战体现在两个方面:在领域问题层面,ARC任务以其高度抽象性和多样性著称,要求模型具备超越模式识别的深层推理能力,这对传统语言模型的泛化能力构成严峻考验;在构建过程中,研究团队需处理海量候选程序的去重问题,原始任务解决方案通过代码去重,而合成任务则基于输出结果去重,这种双重去重机制虽保障了数据质量,但大幅增加了数据清洗的复杂度。此外,如何有效利用失败程序进行后见学习,将其转化为有价值的训练样本,也是数据集构建过程中的关键挑战。
常用场景
经典使用场景
在程序合成领域,soar_arc_train_5M数据集为研究者提供了一个丰富的资源库,用于训练和评估语言模型在抽象推理任务上的表现。该数据集包含了500万条经过去重的ARC解决方案,涵盖了原始任务和通过后见之明标记生成的合成任务。研究者可以利用这些数据来探索模型在程序合成中的自我改进能力,特别是在处理复杂、未见过的推理任务时。
实际应用
在实际应用中,soar_arc_train_5M数据集为开发智能编程助手和自动化代码生成工具提供了重要支持。通过利用数据集中的解决方案,开发者可以训练模型以生成高效的Python代码,解决复杂的抽象推理任务。此外,该数据集还可用于教育领域,帮助学生和研究者理解程序合成的原理和方法。
衍生相关工作
soar_arc_train_5M数据集衍生了一系列经典研究工作,特别是在自我改进语言模型和进化程序合成领域。基于该数据集,研究者开发了SOAR框架,通过进化搜索和后见之明学习,显著提升了模型在ARC任务上的表现。相关成果已在ICML等顶级会议上发表,并推动了开源社区对程序合成的进一步探索。
以上内容由遇见数据集搜集并总结生成


