SynergyAmodal16K
收藏arXiv2025-04-28 更新2025-04-30 收录
下载链接:
https://github.com/imlixinyang/SynergyAmodal
下载链接
链接失效反馈官方服务:
资源简介:
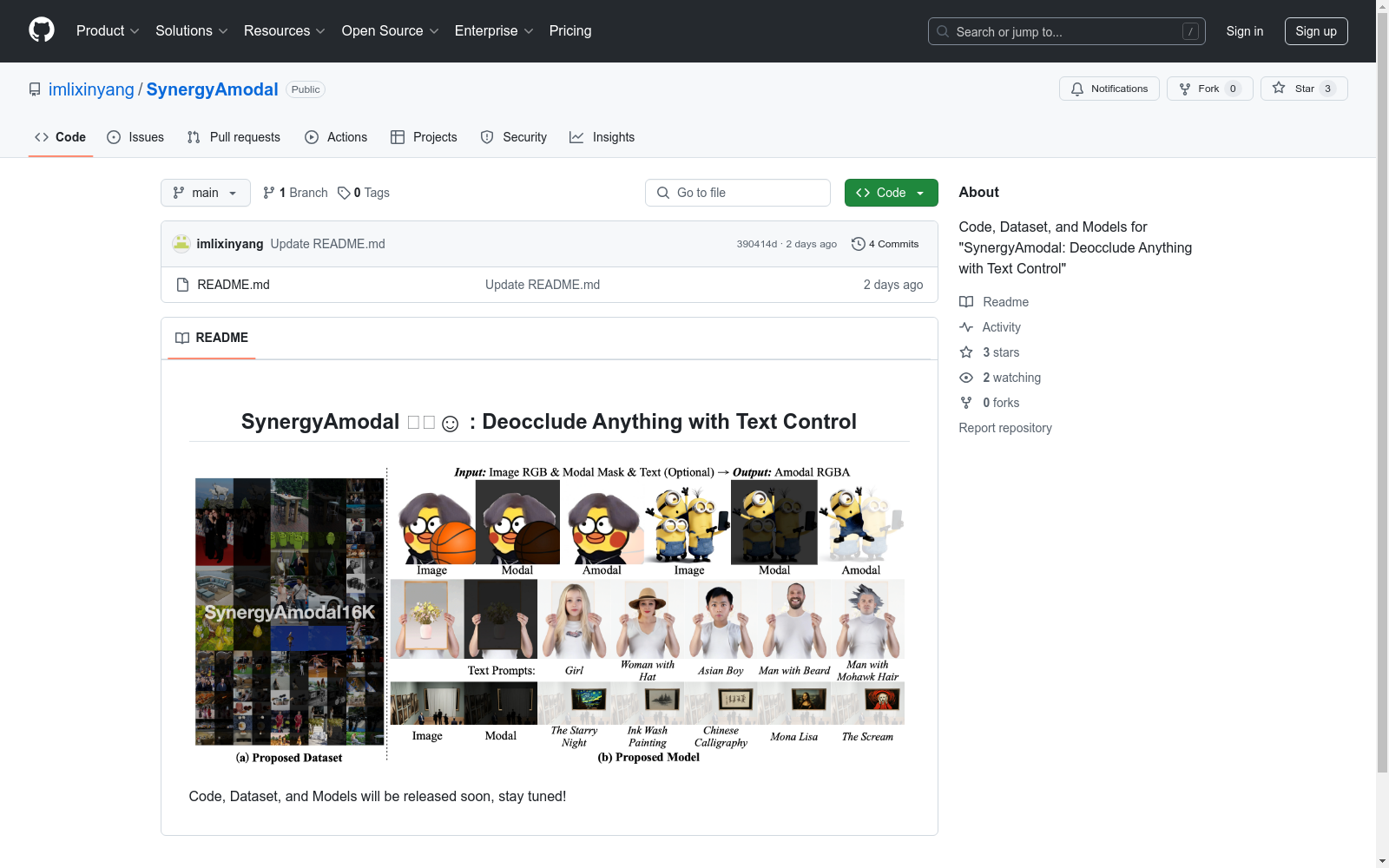
SynergyAmodal16K是一个高质量的16K样本数据集,基于EntitySeg数据集,涵盖了广泛的实例类别和遮挡场景,并伴有高质量的注释,包括遮挡形状、外观和标题。该数据集旨在解决图像去遮挡(或非模态完成)任务中的数据稀缺问题,通过将自然场景中的图像数据、人类专业知识和生成先验相结合,以实现多样性和逼真度的平衡。数据集的创建过程采用了一种数据-人类-模型协同合成的流水线,首先通过自监督学习算法训练一个部分完成模型,然后通过人类专家的指导和先验模型约束进行筛选和注释,最终生成高质量的配对非模态数据。SynergyAmodal16K数据集适用于AIGC、自动驾驶和机器人等领域,旨在帮助研究人员构建更强大的非模态完成模型,以实现零样本泛化能力和文本可控性。
SynergyAmodal16K is a high-quality 16K-sample dataset based on the EntitySeg dataset. It covers a wide range of instance categories and occlusion scenarios, accompanied by high-quality annotations including occlusion shapes, appearances and captions. This dataset aims to address the data scarcity issue in the task of image amodal completion (or occlusion removal). It balances diversity and realism by combining natural scene image data, human expertise and generative priors. The dataset construction adopts a data-human-model collaborative synthesis pipeline: first, a partial completion model is trained via self-supervised learning algorithms, then filtered and annotated under the guidance of human experts and constraints from prior models, ultimately generating high-quality paired amodal data. The SynergyAmodal16K dataset is applicable to fields such as AIGC, autonomous driving and robotics, and aims to help researchers build more powerful amodal completion models to achieve zero-shot generalization capability and text controllability.
提供机构:
厦门大学
创建时间:
2025-04-28
原始信息汇总
SynergyAmodal 数据集概述
数据集名称
SynergyAmodal 😷⇒☺️
数据集简介
Deocclude Anything with Text Control
数据集状态
Code, Dataset, and Models will be released soon, stay tuned!
搜集汇总
数据集介绍
构建方式
SynergyAmodal16K数据集的构建采用了数据-人类-模型协同合成的方法。首先,通过设计一种遮挡感知的自监督学习算法,利用野外图像数据的多样性来训练部分补全扩散模型。随后,通过人类专家的指导和先验模型的约束,对初始的去遮挡结果进行过滤、精炼、选择和标注,确保数据的合理性和保真度。最终,生成了包含约16K样本的高质量配对去遮挡数据集,涵盖了广泛的实例类别和遮挡场景。
使用方法
SynergyAmodal16K数据集可用于训练和评估去遮挡模型,特别是在零样本泛化和文本可控性方面表现优异。用户可以通过输入RGB图像和模态掩码,利用文本提示控制生成过程,输出完整的模态RGBA表示。此外,数据集还可用于结合3D生成模型进行模态3D重建,扩展其在真实场景中的应用。
背景与挑战
背景概述
SynergyAmodal16K是由厦门大学多媒体可信感知与高效计算教育部重点实验室的研究团队于2025年提出的新型去遮挡数据集。该数据集针对计算机视觉领域的amodal completion(模态补全)任务,旨在解决复杂遮挡场景下物体完整形状和外观的恢复问题。研究团队创新性地提出了数据-人类-模型协同合成框架,通过融合真实场景图像的多样性、人类专家的合理性判断和生成模型的保真度优势,构建了包含16,000个样本的高质量配对数据集。数据集基于EntitySeg基准扩展,涵盖了丰富的生活场景和物体类别,每个样本均包含模态图像、遮挡掩模、完整amodal RGBA图像及文本描述等多模态标注。这一工作显著推进了开放世界遮挡场景的理解与生成技术,为AIGC、自动驾驶等应用提供了重要基础支撑。
当前挑战
SynergyAmodal16K面临的核心挑战体现在两个维度:在任务层面,amodal completion需解决遮挡区域形状推断的多义性问题,特别是当物体关键特征被遮挡时,如何保持语义合理性和视觉连贯性;同时还需处理复杂层次遮挡关系下的内容生成,这对模型的场景理解能力提出极高要求。在构建层面,研究团队需要平衡数据规模与质量,克服真实场景遮挡标注的高成本难题;此外,合成数据的物理合理性与视觉保真度之间存在固有矛盾,需通过创新的自监督学习和人类专家协同机制来解决。数据集还需应对开放世界场景的极端多样性,确保模型在未见过的物体类别和遮挡模式上仍具泛化能力。
常用场景
经典使用场景
在计算机视觉领域,SynergyAmodal16K数据集被广泛应用于图像去遮挡(amodal completion)任务的研究。该数据集通过结合真实世界图像的多样性和人类专家的标注,为研究者提供了高质量的遮挡物体形状和外观恢复的基准数据。其经典使用场景包括训练和评估去遮挡模型,特别是在需要恢复被遮挡物体完整形状和外观的复杂场景中。
解决学术问题
SynergyAmodal16K数据集解决了图像去遮挡任务中高质量标注数据稀缺的问题。通过结合数据驱动、人类驱动和模型驱动的方法,该数据集提供了多样化的遮挡场景和高质量的标注,使得研究者能够开发出更具泛化能力的去遮挡模型。此外,该数据集还支持文本控制生成,为研究可控图像生成提供了新的可能性。
实际应用
在实际应用中,SynergyAmodal16K数据集可用于自动驾驶、机器人视觉和增强现实等领域。例如,在自动驾驶中,车辆需要准确识别被部分遮挡的行人或车辆,该数据集提供的去遮挡模型可以帮助系统更准确地理解复杂场景。此外,该数据集还可用于图像编辑和内容生成,提升视觉效果的真实性和一致性。
数据集最近研究
最新研究方向
在计算机视觉领域,SynergyAmodal16K数据集为遮挡物体的完整形状和外观恢复(即amodal completion)提供了高质量的数据支持。该数据集通过结合野外图像数据、人类专家知识和生成模型先验,构建了一个包含16K样本的多样化、高保真amodal数据集。最新研究集中在利用扩散模型进行amodal completion,并通过文本提示控制生成过程,实现了零样本泛化和文本可控性。这一方向在自动驾驶、机器人技术和AIGC等领域具有重要应用前景,为解决复杂遮挡场景下的视觉理解问题提供了新的解决方案。
相关研究论文
- 1SynergyAmodal: Deocclude Anything with Text Control厦门大学 · 2025年
以上内容由遇见数据集搜集并总结生成


