OpenSeek-Pretrain-100B
收藏魔搭社区2026-05-22 更新2025-04-26 收录
下载链接:
https://modelscope.cn/datasets/BAAI/OpenSeek-Pretrain-100B
下载链接
链接失效反馈官方服务:
资源简介:
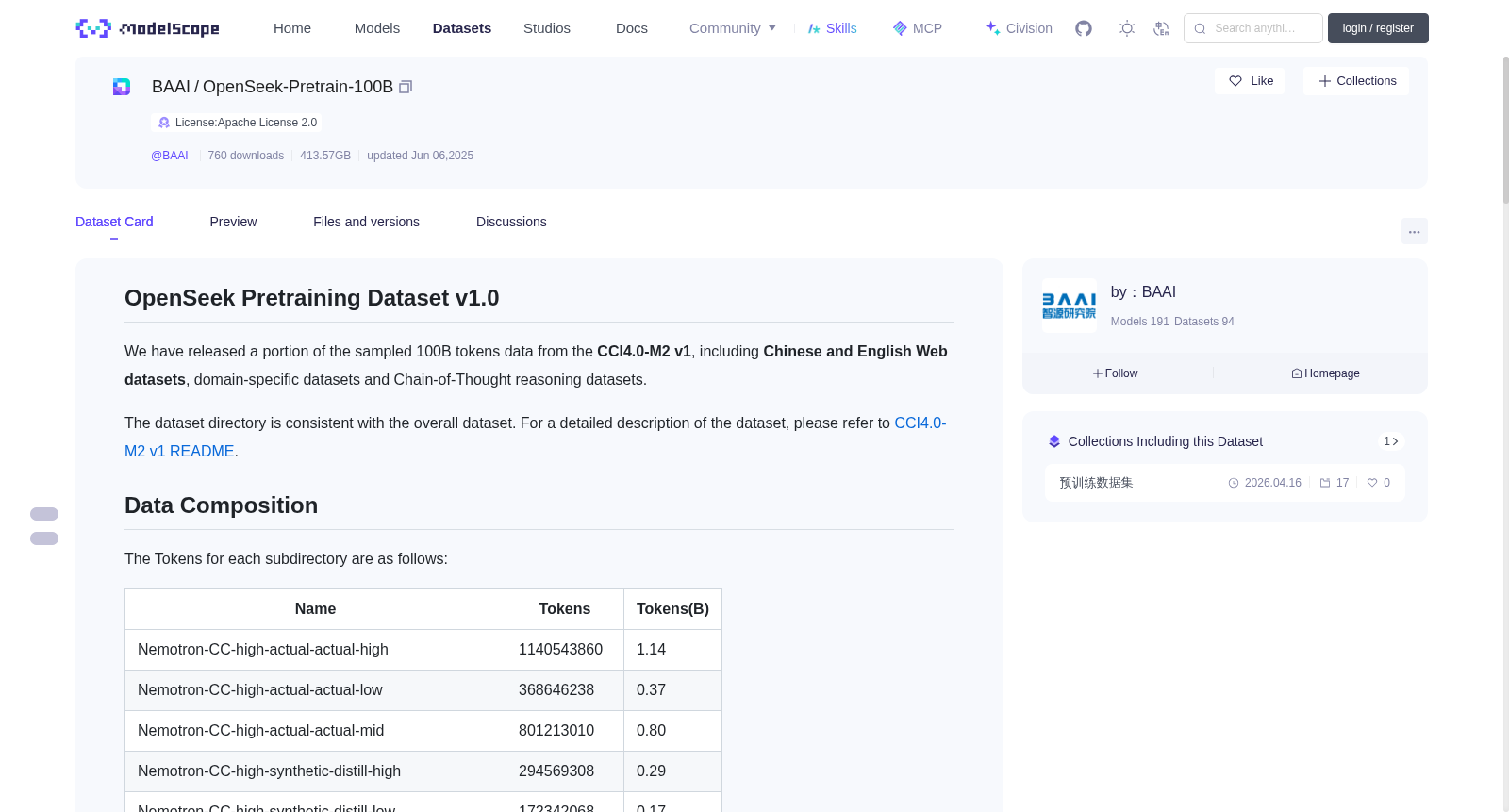
# OpenSeek Pretraining Dataset v1.0
We have released a portion of the sampled 100B tokens data from the **CCI4.0-M2 v1**, including **Chinese and English Web datasets**, domain-specific datasets and Chain-of-Thought reasoning datasets.
The dataset directory is consistent with the overall dataset. For a detailed description of the dataset, please refer to [CCI4.0-M2 v1 README](https://huggingface.co/datasets/BAAI/CCI4.0-M2-Base-v1/blob/main/README.md).
# Data Composition
The Tokens for each subdirectory are as follows:
| Name | Tokens | Tokens(B) |
|---------------------------------------------------|--------------|----------|
| Nemotron-CC-high-actual-actual-high | 1140543860 | 1.14 |
| Nemotron-CC-high-actual-actual-low | 368646238 | 0.37 |
| Nemotron-CC-high-actual-actual-mid | 801213010 | 0.80 |
| Nemotron-CC-high-synthetic-distill-high | 294569308 | 0.29 |
| Nemotron-CC-high-synthetic-distill-low | 172342068 | 0.17 |
| Nemotron-CC-high-synthetic-distill-mid | 240998642 | 0.24 |
| Nemotron-CC-high-synthetic-diverse_qa_pairs-high | 556137649 | 0.56 |
| Nemotron-CC-high-synthetic-diverse_qa_pairs-low | 418742390 | 0.42 |
| Nemotron-CC-high-synthetic-diverse_qa_pairs-mid | 515733187 | 0.52 |
| Nemotron-CC-high-synthetic-extract_knowledge-high | 475714119 | 0.48 |
| Nemotron-CC-high-synthetic-extract_knowledge-low | 68996838 | 0.07 |
| Nemotron-CC-high-synthetic-extract_knowledge-mid | 353316407 | 0.35 |
| Nemotron-CC-high-synthetic-knowledge_list-high | 268953064 | 0.27 |
| Nemotron-CC-high-synthetic-knowledge_list-low | 187973360 | 0.19 |
| Nemotron-CC-high-synthetic-knowledge_list-mid | 238373108 | 0.24 |
| Nemotron-CC-high-synthetic-wrap_medium-high | 848837296 | 0.85 |
| Nemotron-CC-high-synthetic-wrap_medium-low | 295324405 | 0.30 |
| Nemotron-CC-high-synthetic-wrap_medium-mid | 687328353 | 0.69 |
| Nemotron-CC-low-synthetic-wrap_medium-high | 479896420 | 0.48 |
| Nemotron-CC-low-synthetic-wrap_medium-low | 206574167 | 0.21 |
| Nemotron-CC-low-synthetic-wrap_medium-mid | 444865784 | 0.44 |
| Nemotron-CC-medium-actual-actual-high | 1174405205 | 1.17 |
| Nemotron-CC-medium-actual-actual-low | 698884310 | 0.70 |
| Nemotron-CC-medium-actual-actual-mid | 945401567 | 0.95 |
| arxiv | 660912931 | 0.66 |
| books | 483917796 | 0.48 |
| code-high | 1040945650 | 1.04 |
| code-low | 1175000655 | 1.18 |
| code-mid | 996826302 | 1.00 |
| cot_synthesis2_CC-high | 386941302 | 0.39 |
| cot_synthesis2_CC-low | 51390680 | 0.05 |
| cot_synthesis2_CC-mid | 1885475230 | 1.89 |
| cot_synthesis2_OpenSource-high | 265167656 | 0.27 |
| cot_synthesis2_OpenSource-low | 168830028 | 0.17 |
| cot_synthesis2_OpenSource-mid | 334976884 | 0.33 |
| cot_synthesis2_arxiv-high | 12894983685 | 12.89 |
| cot_synthesis2_arxiv-low | 9177670132 | 9.18 |
| cot_synthesis2_arxiv-mid | 10446468216 | 10.45 |
| cot_synthesis2_code-high | 473767419 | 0.47 |
| cot_synthesis2_code-low | 706636812 | 0.71 |
| cot_synthesis2_code-mid | 926436168 | 0.93 |
| cot_synthesis2_math-high | 1353517224 | 1.35 |
| cot_synthesis2_math-low | 1703361358 | 1.70 |
| cot_synthesis2_math-mid | 364330324 | 0.36 |
| cot_synthesis2_wiki-high | 650684154 | 0.65 |
| cot_synthesis2_wiki-low | 615978070 | 0.62 |
| cot_synthesis2_wiki-mid | 814947142 | 0.81 |
| cot_synthesis_CC-high | 229324269 | 0.23 |
| cot_synthesis_CC-low | 185148748 | 0.19 |
| cot_synthesis_CC-mid | 210471356 | 0.21 |
| cot_synthesis_OpenSource-high | 420505110 | 0.42 |
| cot_synthesis_OpenSource-low | 170987708 | 0.17 |
| cot_synthesis_OpenSource-mid | 1321855051 | 1.32 |
| cot_synthesis_arxiv-high | 5853027309 | 5.85 |
| cot_synthesis_arxiv-low | 7718911399 | 7.72 |
| cot_synthesis_arxiv-mid | 9208148090 | 9.21 |
| cot_synthesis_code-high | 789672525 | 0.79 |
| cot_synthesis_code-low | 417526994 | 0.42 |
| cot_synthesis_code-mid | 197436971 | 0.20 |
| cot_synthesis_math-high | 522900778 | 0.52 |
| cot_synthesis_math-low | 663320643 | 0.66 |
| cot_synthesis_math-mid | 660137084 | 0.66 |
| cot_synthesis_wiki-high | 412152225 | 0.41 |
| cot_synthesis_wiki-low | 367306600 | 0.37 |
| cot_synthesis_wiki-mid | 594421619 | 0.59 |
| math-high | 1871864190 | 1.87 |
| math-low | 1745580082 | 1.75 |
| math-mid | 1680811027 | 1.68 |
| pes2o | 6386997158 | 6.39 |
| pes2o-full-train | 1469110938 | 1.47 |
| pes2o-full-val | 14693152 | 0.01 |
| stack | 435813429 | 0.44 |
| wiki | 433002447 | 0.43 |
| zh_cc-high-loss0 | 1872431176 | 1.87 |
| zh_cc-high-loss1 | 1007405788 | 1.01 |
| zh_cc-high-loss2 | 383830893 | 0.38 |
| zh_cc-medidum-loss0 | 978118384 | 0.98 |
| zh_cc-medidum-loss1 | 951741139 | 0.95 |
| zh_cc-medidum-loss2 | 1096769115 | 1.10 |
# OpenSeek 预训练数据集 v1.0
我们从**CCI4.0-M2 v1**中发布了部分采样得到的1000亿Token数据,涵盖**中英文网页数据集**、领域专用数据集与思维链(Chain-of-Thought)推理数据集。
该数据集目录结构与整体数据集保持一致。如需获取该数据集的详细说明,请参阅[CCI4.0-M2 v1 README](https://huggingface.co/datasets/BAAI/CCI4.0-M2-Base-v1/blob/main/README.md)。
# 数据构成
各子目录的Token数量如下:
| 名称 | Token数量 | Token数(十亿) |
|---------------------------------------------------|--------------|----------|
| Nemotron-CC-high-actual-actual-high | 1140543860 | 1.14 |
| Nemotron-CC-high-actual-actual-low | 368646238 | 0.37 |
| Nemotron-CC-high-actual-actual-mid | 801213010 | 0.80 |
| Nemotron-CC-high-synthetic-distill-high | 294569308 | 0.29 |
| Nemotron-CC-high-synthetic-distill-low | 172342068 | 0.17 |
| Nemotron-CC-high-synthetic-distill-mid | 240998642 | 0.24 |
| Nemotron-CC-high-synthetic-diverse_qa_pairs-high | 556137649 | 0.56 |
| Nemotron-CC-high-synthetic-diverse_qa_pairs-low | 418742390 | 0.42 |
| Nemotron-CC-high-synthetic-diverse_qa_pairs-mid | 515733187 | 0.52 |
| Nemotron-CC-high-synthetic-extract_knowledge-high | 475714119 | 0.48 |
| Nemotron-CC-high-synthetic-extract_knowledge-low | 68996838 | 0.07 |
| Nemotron-CC-high-synthetic-extract_knowledge-mid | 353316407 | 0.35 |
| Nemotron-CC-high-synthetic-knowledge_list-high | 268953064 | 0.27 |
| Nemotron-CC-high-synthetic-knowledge_list-low | 187973360 | 0.19 |
| Nemotron-CC-high-synthetic-knowledge_list-mid | 238373108 | 0.24 |
| Nemotron-CC-high-synthetic-wrap_medium-high | 848837296 | 0.85 |
| Nemotron-CC-high-synthetic-wrap_medium-low | 295324405 | 0.30 |
| Nemotron-CC-high-synthetic-wrap_medium-mid | 687328353 | 0.69 |
| Nemotron-CC-low-synthetic-wrap_medium-high | 479896420 | 0.48 |
| Nemotron-CC-low-synthetic-wrap_medium-low | 206574167 | 0.21 |
| Nemotron-CC-low-synthetic-wrap_medium-mid | 444865784 | 0.44 |
| Nemotron-CC-medium-actual-actual-high | 1174405205 | 1.17 |
| Nemotron-CC-medium-actual-actual-low | 698884310 | 0.70 |
| Nemotron-CC-medium-actual-actual-mid | 945401567 | 0.95 |
| arxiv | 660912931 | 0.66 |
| books | 483917796 | 0.48 |
| code-high | 1040945650 | 1.04 |
| code-low | 1175000655 | 1.18 |
| code-mid | 996826302 | 1.00 |
| cot_synthesis2_CC-high | 386941302 | 0.39 |
| cot_synthesis2_CC-low | 51390680 | 0.05 |
| cot_synthesis2_CC-mid | 1885475230 | 1.89 |
| cot_synthesis2_OpenSource-high | 265167656 | 0.27 |
| cot_synthesis2_OpenSource-low | 168830028 | 0.17 |
| cot_synthesis2_OpenSource-mid | 334976884 | 0.33 |
| cot_synthesis2_arxiv-high | 12894983685 | 12.89 |
| cot_synthesis2_arxiv-low | 9177670132 | 9.18 |
| cot_synthesis2_arxiv-mid | 10446468216 | 10.45 |
| cot_synthesis2_code-high | 473767419 | 0.47 |
| cot_synthesis2_code-low | 706636812 | 0.71 |
| cot_synthesis2_code-mid | 926436168 | 0.93 |
| cot_synthesis2_math-high | 1353517224 | 1.35 |
| cot_synthesis2_math-low | 1703361358 | 1.70 |
| cot_synthesis2_math-mid | 364330324 | 0.36 |
| cot_synthesis2_wiki-high | 650684154 | 0.65 |
| cot_synthesis2_wiki-low | 615978070 | 0.62 |
| cot_synthesis2_wiki-mid | 814947142 | 0.81 |
| cot_synthesis_CC-high | 229324269 | 0.23 |
| cot_synthesis_CC-low | 185148748 | 0.19 |
| cot_synthesis_CC-mid | 210471356 | 0.21 |
| cot_synthesis_OpenSource-high | 420505110 | 0.42 |
| cot_synthesis_OpenSource-low | 170987708 | 0.17 |
| cot_synthesis_OpenSource-mid | 1321855051 | 1.32 |
| cot_synthesis_arxiv-high | 5853027309 | 5.85 |
| cot_synthesis_arxiv-low | 7718911399 | 7.72 |
| cot_synthesis_arxiv-mid | 9208148090 | 9.21 |
| cot_synthesis_code-high | 789672525 | 0.79 |
| cot_synthesis_code-low | 417526994 | 0.42 |
| cot_synthesis_code-mid | 197436971 | 0.20 |
| cot_synthesis_math-high | 522900778 | 0.52 |
| cot_synthesis_math-low | 663320643 | 0.66 |
| cot_synthesis_math-mid | 660137084 | 0.66 |
| cot_synthesis_wiki-high | 412152225 | 0.41 |
| cot_synthesis_wiki-low | 367306600 | 0.37 |
| cot_synthesis_wiki-mid | 594421619 | 0.59 |
| math-high | 1871864190 | 1.87 |
| math-low | 1745580082 | 1.75 |
| math-mid | 1680811027 | 1.68 |
| pes2o | 6386997158 | 6.39 |
| pes2o-full-train | 1469110938 | 1.47 |
| pes2o-full-val | 14693152 | 0.01 |
| stack | 435813429 | 0.44 |
| wiki | 433002447 | 0.43 |
| zh_cc-high-loss0 | 1872431176 | 1.87 |
| zh_cc-high-loss1 | 1007405788 | 1.01 |
| zh_cc-high-loss2 | 383830893 | 0.38 |
| zh_cc-medidum-loss0 | 978118384 | 0.98 |
| zh_cc-medidum-loss1 | 951741139 | 0.95 |
| zh_cc-medidum-loss2 | 1096769115 | 1.10 |
提供机构:
maas
创建时间:
2025-04-22
搜集汇总
数据集介绍
背景与挑战
背景概述
OpenSeek-Pretrain-100B是一个大规模预训练数据集,包含100B tokens,涵盖中英文网页、特定领域及链式推理数据,适用于多种自然语言处理任务。
以上内容由遇见数据集搜集并总结生成


