有没有相关的论文或文献参考?
这个数据集是基于什么背景创建的?
数据集的作者是谁?
能帮我联系到这个数据集的作者吗?
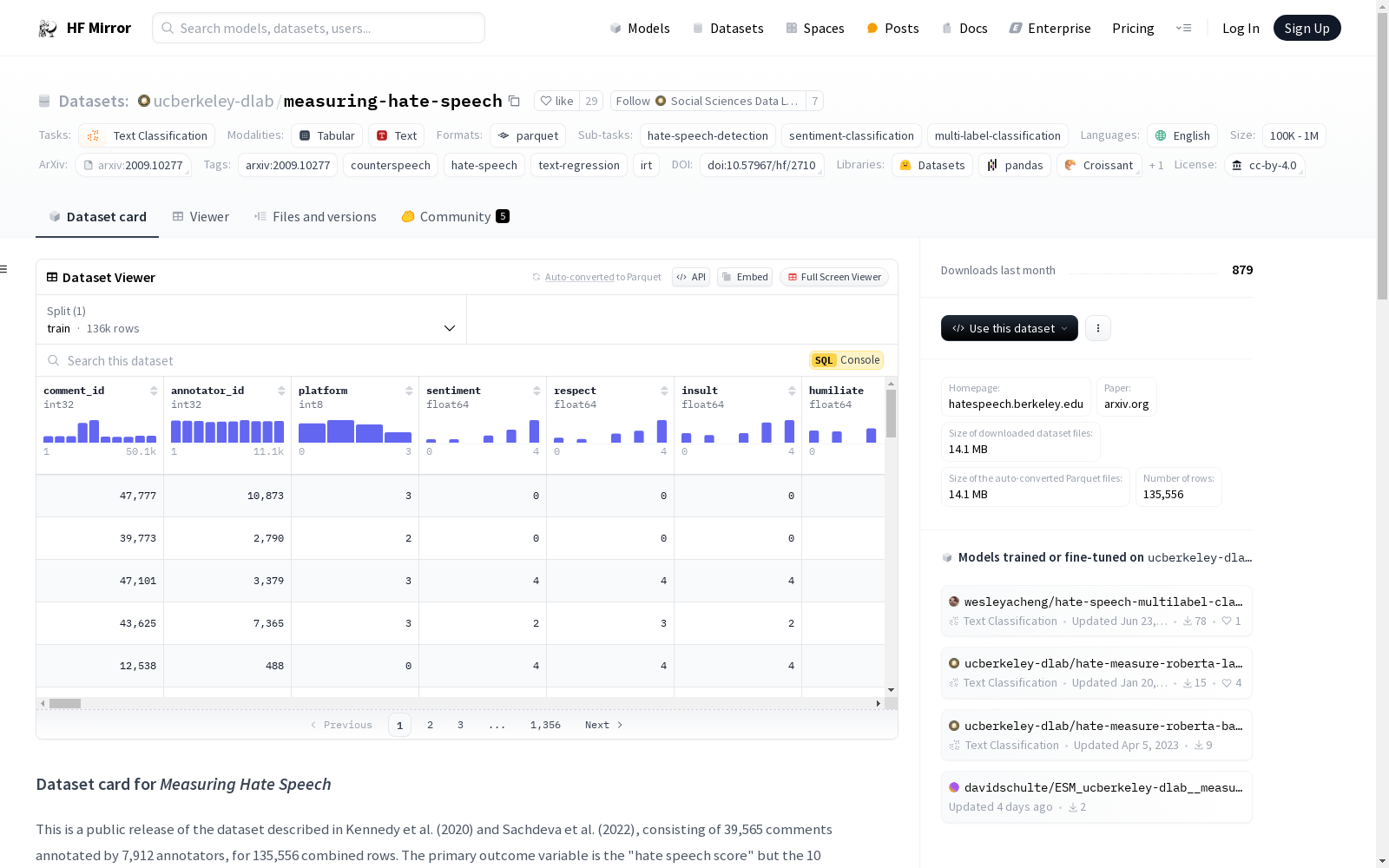
这个数据集如何下载?
使用以下Python代码下载数据集:
python
import datasets
dataset = datasets.load_dataset(ucberkeley-dlab/measuring-hate-speech, binary)
df = dataset[train].to_pandas()
df.describe()
@article{kennedy2020constructing, title={Constructing interval variables via faceted Rasch measurement and multitask deep learning: a hate speech application}, author={Kennedy, Chris J and Bacon, Geoff and Sahn, Alexander and von Vacano, Claudia}, journal={arXiv preprint arXiv:2009.10277}, year={2020} }
中国1km分辨率逐月降水量数据集(1901-2023)
该数据集为中国逐月降水量数据,空间分辨率为0.0083333°(约1km),时间为1901.1-2023.12。数据格式为NETCDF,即.nc格式。该数据集是根据CRU发布的全球0.5°气候数据集以及WorldClim发布的全球高分辨率气候数据集,通过Delta空间降尺度方案在中国降尺度生成的。并且,使用496个独立气象观测点数据进行验证,验证结果可信。本数据集包含的地理空间范围是全国主要陆地(包含港澳台地区),不含南海岛礁等区域。为了便于存储,数据均为int16型存于nc文件中,降水单位为0.1mm。 nc数据可使用ArcMAP软件打开制图; 并可用Matlab软件进行提取处理,Matlab发布了读入与存储nc文件的函数,读取函数为ncread,切换到nc文件存储文件夹,语句表达为:ncread (‘XXX.nc’,‘var’, [i j t],[leni lenj lent]),其中XXX.nc为文件名,为字符串需要’’;var是从XXX.nc中读取的变量名,为字符串需要’’;i、j、t分别为读取数据的起始行、列、时间,leni、lenj、lent i分别为在行、列、时间维度上读取的长度。这样,研究区内任何地区、任何时间段均可用此函数读取。Matlab的help里面有很多关于nc数据的命令,可查看。数据坐标系统建议使用WGS84。
国家青藏高原科学数据中心 收录
中国交通事故深度调查(CIDAS)数据集
交通事故深度调查数据通过采用科学系统方法现场调查中国道路上实际发生交通事故相关的道路环境、道路交通行为、车辆损坏、人员损伤信息,以探究碰撞事故中车损和人伤机理。目前已积累深度调查事故10000余例,单个案例信息包含人、车 、路和环境多维信息组成的3000多个字段。该数据集可作为深入分析中国道路交通事故工况特征,探索事故预防和损伤防护措施的关键数据源,为制定汽车安全法规和标准、完善汽车测评试验规程、
北方大数据交易中心 收录
AISHELL/AISHELL-1
Aishell是一个开源的中文普通话语音语料库,由北京壳壳科技有限公司发布。数据集包含了来自中国不同口音地区的400人的录音,录音在安静的室内环境中使用高保真麦克风进行,并下采样至16kHz。通过专业的语音标注和严格的质量检查,手动转录的准确率超过95%。该数据集免费供学术使用,旨在为语音识别领域的新研究人员提供适量的数据。
hugging_face 收录
PlantVillage
在这个数据集中,39 种不同类别的植物叶子和背景图像可用。包含 61,486 张图像的数据集。我们使用了六种不同的增强技术来增加数据集的大小。这些技术是图像翻转、伽玛校正、噪声注入、PCA 颜色增强、旋转和缩放。
OpenDataLab 收录
熟肉制品在全国需求价格弹性分析数据
为更好了解各市对熟肉制品的市场需求情况,本行业所有企业对相关熟肉制品需求弹性数据进行采集计算。如果熟肉制品需求量变动的比率大于价格变动的比率,那么熟肉制品需求富有弹性,说明顾客对于熟肉制品价格变化的敏感程度大,弹性越大,需求对价格变化越敏感,本行业所有企业可以在该市适当的降低熟肉制品价格来获得较多的收益。如果熟肉制品需求缺乏弹性,本行业所有企业可以在该市适当的提高熟肉制品价格来获得较多的收益。该项数据对本行业所有企业在全国的市场营销决策有重要意义。1.数据采集:采集相关熟肉制品在某一时间段全国的的需求数据和价格数据,按照市级进行整理归纳,得到该熟肉制品的需求量变动数值和价格变化数值。 2.算法规则:对采集得到的数据按照如下公式进行计算:需求弹性系数Ed=-(△Q/Q)÷(△P/P),得到需求弹性系数。式中:Q表示产品的需求量,单位为份;P表示产品的价格,单位为元;△Q表示需求量同比变动值,单位为份;△P表示价格同比变动值,单位为元。取需求弹性系数的绝对值|Ed|作为分析数据时的参考系数。 3.数据分析:根据|Ed|的数值可分析该熟肉制品的需求价格弹性。(1)|Ed|=1(单位需求价格弹性),说明需求量变动幅度与价格变动幅度相同;(2)1<|Ed|(需求富有弹性),说明需求量变动幅度大于价格变动幅度;(3)|Ed|<1(需求缺乏弹性),说明需求量变动幅度小于价格变动幅度。
浙江省数据知识产权登记平台 收录