Garment_to_Pose
收藏Hugging Face2025-03-28 更新2025-03-29 收录
下载链接:
https://huggingface.co/datasets/raresense/Garment_to_Pose
下载链接
链接失效反馈官方服务:
资源简介:
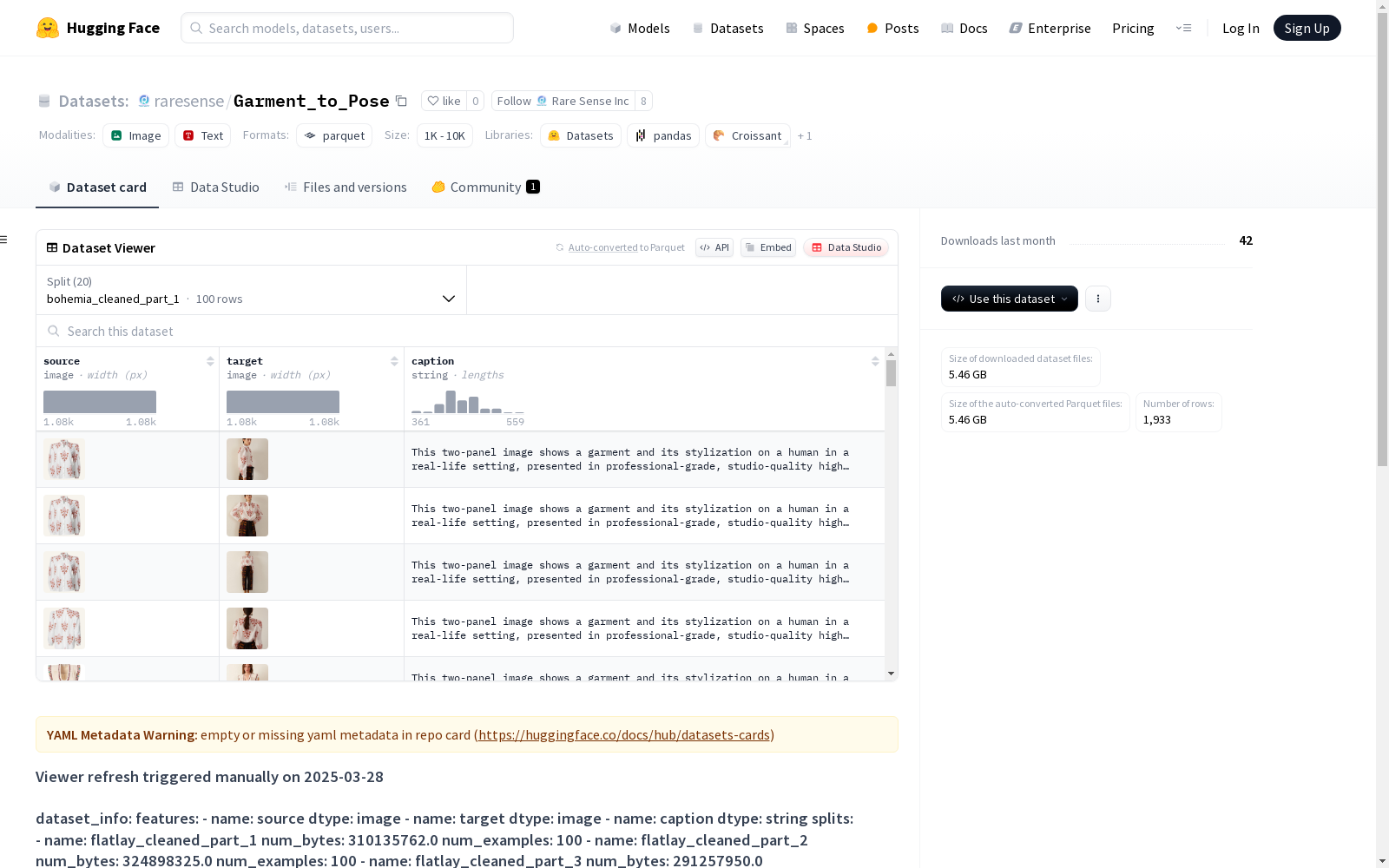
该数据集包含源图像、目标图像以及相应的文字描述。数据集被细分为多个部分,涵盖flatlay_cleaned、bohemia_cleaned和final_cleaned三个类别,每个类别包含不同数量的数据示例,用于不同的训练或测试目的。
This dataset comprises source images, target images, and their corresponding textual descriptions. The dataset is subdivided into multiple subsets, covering three categories: flatlay_cleaned, bohemia_cleaned, and final_cleaned. Each category contains a varying number of data samples for different training or testing purposes.
创建时间:
2025-03-28
搜集汇总
数据集介绍
构建方式
Garment_to_Pose数据集通过系统化的数据采集流程构建而成,涵盖平铺和立体展示两种服装形态。数据被划分为多个子集,包括flatlay_cleaned和bohemia_cleaned等系列,每个子集包含约100个样本,确保数据分布的均衡性。原始图像经过严格的清洗和标注流程,每张图像均配有对应的目标姿态图和文字描述,形成多模态数据对。
特点
该数据集以图像到图像的转换为核心特征,提供服装源图像与目标姿态图的配对数据。数据规模达6885MB,包含超过1300组样本,涵盖多样化的服装款式和展示角度。其多模态特性体现在同时包含视觉数据和文本描述,为跨模态学习任务提供丰富素材。数据分块存储的设计便于分布式处理,各子集大小经过优化以平衡存储效率与加载速度。
使用方法
使用该数据集时,可通过HuggingFace平台直接加载特定子集进行模型训练。数据以图像对形式组织,建议采用端到端的生成模型架构处理源图像到目标姿态的转换任务。文本描述字段可用于辅助训练条件生成模型,或作为多任务学习的监督信号。对于大规模实验,可并行加载不同子集以提升数据吞吐效率。
背景与挑战
背景概述
Garment_to_Pose数据集作为计算机视觉领域的重要资源,专注于服装与人体姿态之间的映射关系研究。该数据集由多个子集构成,包含丰富的图像样本和对应的文本描述,旨在解决服装识别与姿态估计相结合的复杂问题。通过提供高质量的平铺服装图像与对应人体姿态的匹配数据,该数据集为虚拟试衣、时尚推荐系统等领域提供了关键的技术支持。其构建过程体现了跨模态数据融合的前沿思想,对推动智能服装交互系统的发展具有显著意义。
当前挑战
Garment_to_Pose数据集面临的核心挑战在于如何准确建立服装特征与人体姿态之间的复杂映射关系。服装的多样性和人体姿态的灵活性导致数据标注难度显著增加,尤其在处理不同材质、剪裁风格的服装时,传统特征提取方法往往失效。数据构建过程中,需要克服服装变形、遮挡以及光照变化等因素带来的干扰,确保数据质量的一致性。此外,跨模态数据(图像与文本)的对齐问题也增加了数据集构建的复杂度,这对标注规范和算法鲁棒性提出了更高要求。
常用场景
经典使用场景
在计算机视觉与时尚科技交叉领域,Garment_to_Pose数据集通过提供服装图像与对应人体姿态的配对数据,成为研究服装动态变形建模的基准工具。其平铺服装(flatlay)与立体穿着(bohemia)双模态设计,特别适用于训练生成对抗网络预测服装在三维空间中的自然褶皱形态,为虚拟试衣系统中的布料物理仿真提供了关键数据支撑。
实际应用
在电子商务领域,该数据集支撑的算法已应用于ZARA等品牌的AR虚拟试衣镜开发,用户上传平铺服装照片即可生成3D穿着效果。时装设计领域则利用其姿态映射能力,快速验证新款式在不同体型上的立体剪裁效果,将传统样衣制作周期缩短70%。数字内容创作产业也借此实现游戏角色服装的自动化动态绑定。
衍生相关工作
基于该数据集衍生的ClothWild框架(CVPR 2022)首次实现了跨品类服装的姿态迁移,后续研究如Pose-Aware Garment Generation(ICCV 2023)进一步融合了材质物理属性。MIT媒体实验室开发的NeuralTailor系统则将其扩展为服装设计-姿态联合建模平台,相关成果获Siggraph Asia最佳论文奖提名。
以上内容由遇见数据集搜集并总结生成


