SiPaKosa
收藏Hugging Face2026-04-05 更新2026-04-06 收录
下载链接:
https://huggingface.co/datasets/RaniduG/SiPaKosa
下载链接
链接失效反馈官方服务:
资源简介:
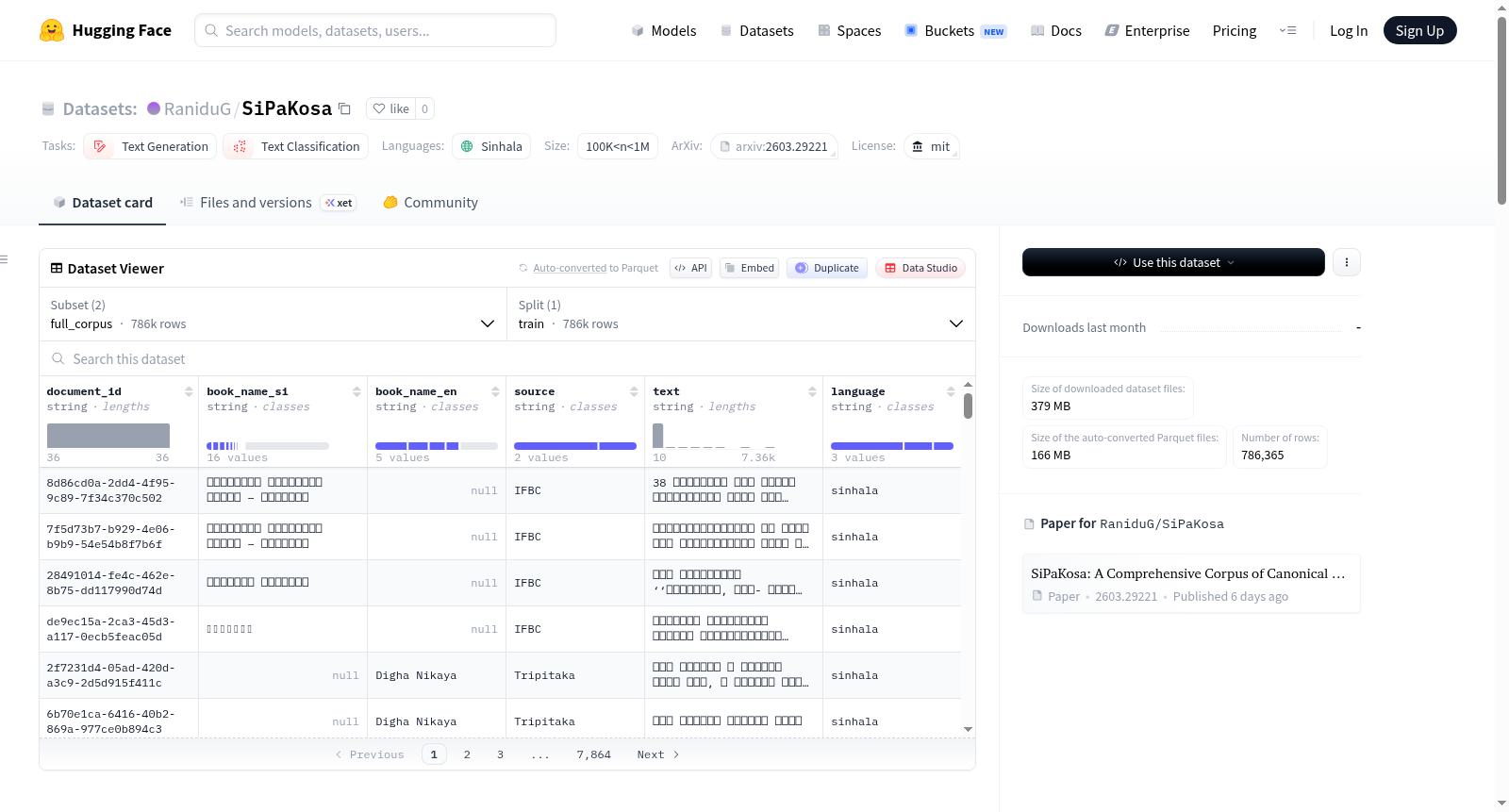
SiPaKosa 是一个包含僧伽罗语和巴利语的佛教经典文本的综合性语料库,数据来源于历史档案和网络爬取的经典经文。该数据集包含 786,344 个句子,其中 59.2% 为纯僧伽罗语句子,40.8% 为僧伽罗语和巴利语混合句子。数据来源包括 16 本历史书籍(IFBC)和 5 部尼柯耶(三藏)。数据集提供四种配置:`sinhala`(纯僧伽罗语文本)、`mixed`(混合语言文本)、`sinhala_metadata`(包含元数据的 CSV 文件)和 `mixed_metadata`(包含元数据的 CSV 文件)。元数据包括句子 ID、书籍类别、书籍名称(僧伽罗语和英语)、数据来源、文本内容和语言分类。数据集结构分为训练集、验证集和测试集,文件格式包括 txt 和 csv。此外,数据集还提供了详细的元数据结构,包括 PDF 和三藏相关的元数据文件。该数据集适用于文本生成和文本分类任务,并采用 MIT 许可证发布。
SiPaKosa is a comprehensive corpus of Buddhist canonical texts in Sinhala and Pali, sourced from historical archives and web-crawled canonical scriptures. The dataset contains 786,344 sentences, of which 59.2% are pure Sinhala sentences and 40.8% are mixed Sinhala-Pali sentences. Its data sources include 16 historical books (IFBC) and 5 Nikāyas (Tripitaka). The dataset provides four configurations: `sinhala` (pure Sinhala text), `mixed` (mixed-language text), `sinhala_metadata` (CSV file with metadata), and `mixed_metadata` (CSV file with metadata). The metadata includes sentence ID, book category, book names in Sinhala and English, data source, text content, and language classification. The dataset is structured into training, validation, and test sets, with file formats including txt and csv. Additionally, the dataset offers detailed metadata structures including PDF and Tripitaka-related metadata files. This dataset is applicable to text generation and text classification tasks, and is released under the MIT License.
创建时间:
2026-03-29
原始信息汇总
SiPaKosa 数据集概述
数据集基本信息
- 数据集名称: SiPaKosa: Sinhala-Pali Buddhist Corpus
- 许可证: MIT
- 任务类别: 文本生成、文本分类
- 语言: 僧伽罗语 (si)
- 数据规模: 100K < n < 1M
数据集描述
SiPaKosa 是一个全面的、包含僧伽罗语和巴利语的佛教经典和古典文本语料库,编译自历史档案和网络抓取的经典经文。
数据集统计
- 总句子数: 786,344
- 僧伽罗语句子: 465,539 (59.2%)
- 僧伽罗语-巴利语混合句子: 320,805 (40.8%)
- 数据来源: 16 本历史书籍 (IFBC) + 5 部尼柯耶 (Tripitaka)
数据集配置
该数据集提供四种配置:
| 配置名称 | 格式 | 列 | 最佳用途 |
|---|---|---|---|
sinhala |
txt | 仅文本 | 模型训练 |
mixed |
txt | 仅文本 | 模型训练 |
sinhala_metadata |
csv | sentence_id, book_category, book_name_si, book_name_en, source, text, language | 按书籍或来源筛选 |
mixed_metadata |
csv | sentence_id, book_category, book_name_si, book_name_en, source, text, language | 按书籍或来源筛选 |
数据集结构
数据文件以 Parquet 格式存储,按配置和划分组织:
- sinhala 配置:
data/sinhala/train.parquetdata/sinhala/validation.parquetdata/sinhala/test.parquet
- mixed 配置:
data/mixed/train.parquetdata/mixed/validation.parquetdata/mixed/test.parquet
CSV 列描述
| 列名 | 描述 | 示例 |
|---|---|---|
sentence_id |
全局唯一的句子ID | 1 |
book_category |
来源书籍的类别 | books-related-to-the-tipitaka |
book_name_si |
僧伽罗语书籍名称 (仅 IFBC) | විශුද්ධිමාර්ගය |
book_name_en |
英语书籍名称 (仅 Tripitaka) | Digha Nikaya |
source |
数据来源 | IFBC 或 Tripitaka |
text |
句子文本 | මා හට අසන්නට ලැබුණේ... |
language |
语言分类 | sinhala 或 mixed |
元数据结构
metadata/ 文件夹包含两个子文件夹:pdf/ 和 tripitaka/。
metadata/pdf/
包含 PDF 语料库中 16 本数字化佛教书籍的统计数据和清单数据。
corpus_manifest.json— 列出每本书的僧伽罗语和英语名称、类别和文件路径。corpus_statistics.json— 高级摘要:总书籍数 (16)、总页数 (7,064)、语言分布(僧伽罗语 vs. 混合)以及类别分布。detailed_corpus_statistics.json— 按书籍和按类别的详细分类,包括词数、字符数和每页平均值。涵盖三个类别:books-related-to-the-tipitaka、old-books和buddhist-characters。
metadata/tripitaka/
包含从 https://tripitaka.online 抓取的经藏数据,按尼柯耶组织。每个尼柯耶有自己的子文件夹(例如 digha/、majjhima/、anguttara/)。
每个子文件夹内包含:
suttas_batch_{number}.json— 分批的经藏记录。每个条目包含 URL、标题、僧伽罗语内容、巴利语内容、词数、尼柯耶信息、抓取方法和时间戳。error_log.json— 记录抓取失败的经藏。scraping_progress.json— 跟踪已抓取与出错的经藏数量。
相关链接
- 论文: https://arxiv.org/abs/2603.29221
- 引用文档:
docs/CITATION.bib
搜集汇总
数据集介绍
构建方式
在佛教文献数字化领域,SiPaKosa数据集的构建融合了历史档案整理与现代网络爬取技术。该数据集汇集了16部历史佛教书籍的数字化内容以及从Tripitaka在线平台系统采集的五部尼柯耶经典,通过自动化流程提取文本并划分句子,最终形成包含78万余句的大规模语料库。构建过程中,团队精心处理了僧伽罗语与巴利语的混合文本,确保语言分类的准确性,并为每一条数据标注了详尽的元信息,如书籍类别、名称及来源,为后续的学术研究奠定了坚实基础。
特点
SiPaKosa数据集的核心特点在于其语言构成的多样性与来源的权威性。数据集包含超过46万句纯僧伽罗语句子以及32万句僧伽罗语与巴利语混合句子,这种双语混合特性为研究语言接触与宗教文本翻译提供了独特资源。数据来源于权威的佛教经典,如《长部尼柯耶》等原始典籍,确保了文本的学术价值。此外,数据集提供了四种配置,包括纯文本格式与附带元数据的CSV格式,用户可根据需要选择适合训练或深入分析的版本,灵活应对不同研究场景。
使用方法
使用SiPaKosa数据集时,研究人员可通过Hugging Face的datasets库便捷加载不同配置。对于模型训练任务,可直接加载'sinhala'或'mixed'配置的纯文本数据,快速投入语言模型预训练或文本生成实验。若需进行细粒度分析,如按书籍来源或语言类别筛选,则可选用附带元数据的版本,利用Pandas等工具进行数据过滤与统计。数据集已预先划分为训练集、验证集和测试集,支持即插即用的评估流程,同时其丰富的元数据结构便于开展跨文本比较与历史语言学探究。
背景与挑战
背景概述
在自然语言处理领域,低资源语言的文本语料库构建一直是推动语言技术普及的关键环节。SiPaKosa数据集由研究人员RaniduG等人于2024年创建,专注于僧伽罗语和巴利语的佛教经典文本。该数据集整合了来自国际佛教数字图书馆(IFBC)的16部历史典籍以及从Tripitaka在线平台爬取的5部尼柯耶经典,共计包含超过78万条句子,其中僧伽罗语单语文本占比约59.2%,混合语言文本占40.8%。其核心研究目标在于为僧伽罗语和巴利语提供大规模、高质量的训练数据,以支持文本生成与分类任务,并促进南亚地区文化遗产的数字化保存与自然语言处理研究的发展。
当前挑战
SiPaKosa数据集致力于解决低资源语言在自然语言处理中面临的语料稀缺问题,其挑战首先体现在领域问题的复杂性上:佛教经典文本包含大量古语、专有名词和混合语言表达,对模型的语义理解与跨语言对齐能力提出了较高要求。在构建过程中,数据集面临多重技术挑战,包括历史典籍的数字化转换与字符编码统一、网络爬取时对非结构化HTML内容的解析与错误处理,以及混合语言句子的自动标注与质量控制。此外,确保文本的宗教与文化准确性,避免在数据清洗过程中引入语义偏差,也是构建过程中需要细致考量的关键环节。
常用场景
经典使用场景
在低资源语言处理领域,僧伽罗语和巴利语的文本资源相对稀缺,SiPaKosa数据集为相关研究提供了宝贵的语料基础。该数据集最经典的使用场景是作为大规模预训练语料,用于训练僧伽罗语或双语的语言模型。研究者利用其纯僧伽罗语或僧伽罗-巴利语混合的文本配置,能够有效提升模型在语法理解、词汇表征等方面的性能,为后续的下游任务奠定坚实的语言基础。
实际应用
在实际应用层面,SiPaKosa数据集能够支撑多种具体的语言技术服务。例如,它可以用于开发面向佛教典籍的数字化阅读与检索工具,帮助学者和信徒更便捷地查阅和研究经典。此外,基于该数据集训练的模型也能应用于教育领域,如开发辅助学习僧伽罗语或巴利语的智能应用,或者用于文化遗产的数字化保存与多语言知识库的构建,促进古老智慧在现代技术环境中的传承与传播。
衍生相关工作
围绕SiPaKosa数据集,已经衍生出一系列相关的经典研究工作。这些工作主要集中在利用该语料进行僧伽罗语语言模型的预训练与微调,例如开发专门的文本分类或命名实体识别模型以处理宗教文献。同时,该数据集也促进了跨语言研究,如僧伽罗语-巴利语或僧伽罗语-英语的机器翻译模型的探索。这些研究不仅验证了数据集的实用价值,也进一步丰富了低资源语言处理的技术路线与方法论。
以上内容由遇见数据集搜集并总结生成


