Balochi-Multilingual-dataset
收藏Hugging Face2024-12-19 更新2024-12-20 收录
下载链接:
https://huggingface.co/datasets/Salman95s/Balochi-Multilingual-dataset
下载链接
链接失效反馈官方服务:
资源简介:
Balochi语言数据集是一个全面的资源,用于在Balochi语言中训练大型语言模型(LLMs)。该数据集旨在超越基本的翻译任务,支持Balochi中的全生成文本和对话式AI能力。数据集包括单语Balochi文本、多语言翻译语料库以及各种对话和特定领域的文本,支持多种用例,如生成AI、多语言翻译、文化洞察和特定领域的应用。数据集涵盖Balochi、英语、乌尔都语和波斯语,涉及多个领域,如一般对话、文学、新闻、学术文本、技术内容、文化和历史叙述、旅行和教育材料以及助手和聊天场景。数据集还包括对话样本、专业场景和技术术语。尽管数据集经过精心策划以包含多样化和代表性内容,但用户应注意数据中的潜在偏见、可能的冒犯性内容和翻译限制。
The Balochi Language Dataset is a comprehensive resource for training large language models (LLMs) in the Balochi language. This dataset aims to transcend basic translation tasks, enabling full generative text and conversational AI capabilities in Balochi. It includes monolingual Balochi texts, multilingual translation corpora, as well as diverse conversational and domain-specific texts, supporting a wide array of use cases such as generative AI, multilingual translation, cultural insights, and domain-specific applications. Covering four languages including Balochi, English, Urdu, and Persian, the dataset spans multiple domains: general conversations, literature, news, academic texts, technical content, cultural and historical narratives, travel and educational materials, as well as assistant and chat scenarios. Additionally, the dataset contains conversational samples, professional scenarios, and technical terminology. While the dataset has been meticulously curated to incorporate diverse and representative content, users should remain mindful of potential biases, possible offensive material, and translation limitations inherent in the data.
创建时间:
2024-12-16
原始信息汇总
Balochi Language Dataset
概述
该数据集是一个全面的资源,用于训练Balochi语言的大型语言模型(LLMs)。它旨在超越基本的翻译任务,支持Balochi中的完全生成文本和对话式AI功能。
数据集包括单语Balochi文本、多语言翻译语料库以及各种对话和领域特定文本,支持多种用例,如:
- 生成式AI:构建Balochi的聊天机器人和生成文本系统。
- 多语言翻译:在Balochi和其他语言(如英语、乌尔都语和波斯语)之间进行翻译。
- 文化洞察:为文化和历史文本提供背景。
- 领域特定应用:技术、教育和助手导向的任务。
关键特性
-
语言:Balochi、英语、乌尔都语、波斯语。
-
领域:
- 普通对话
- 文学
- 新闻
- 学术文本
- 技术内容
- 文化和历史叙事
- 旅行和教育材料
- 助手和聊天场景
-
数据集规模:
- 单语和多语言对总计数万条记录。
- 包括对话样本、专业场景和技术术语。
数据集亮点
单语数据
- 专注于来自文化、历史和对话背景的Balochi文本。
- 包含经过清理和格式化的版本,用于模型训练。
多语言翻译数据
- Balochi-English:通用和技术翻译。
- Balochi-Urdu:新闻和对话翻译。
- Balochi-Persian:文学和历史翻译。
对话样本
包括各种现实场景:
- 日常互动(例如,问候、家庭讨论)。
- 专业设置(例如,面试、会议)。
- 教育背景(例如,课堂问题)。
- 旅行场景(例如,在机场、预订酒店)。
技术术语
涵盖领域如:
- 计算
- 医学
- 物理
- 互联网技术
偏见、风险和局限性
该数据集经过精心策划,以包含多样化和具有代表性的内容。然而,用户应注意以下几点:
-
数据偏见:
- 尽管努力确保多样性,但源材料中固有的一些偏见可能仍然存在。
- Balochi的某些方言或地区变体可能代表性不足。
-
潜在的冒犯性内容:
- 虽然数据已经过清理,但仍有可能无意中包含敏感或冒犯性术语。
- 用户应在必要时实施后处理和过滤机制。
-
翻译局限性:
- 翻译不能保证完美,在敏感或关键应用中可能需要人工审查。
数据来源
Balochi数据集是通过多样化和高质量的来源开发的,以确保广泛的语境覆盖。以下是数据集创建中使用的主要来源列表:
-
GlotSparse:
- 一个用于稀疏语言建模的多语言数据集。包含从各种网络来源提取的Balochi文本,提供了宝贵的单语数据。
-
GlotCC-V1:
- 一个专注于从Common Crawl创建多语言语料库的数据集。该来源提供了广泛的Balochi文本,涵盖了多种领域。
-
URL-NLP Repository:
- 由Google Research收集的语言数据集和工具。该存储库中的Balochi特定数据增强了数据集的语言多样性。
-
PanLex Meanings: Balochi:
- 一个提供Balochi词汇意义和语义对的数据集,支持词汇开发和语义理解。
-
PanLex Meanings:
- 一个跨语言词汇意义的多语言数据集。Balochi子集丰富了数据集,提供了宝贵的翻译对和词汇条目。
-
Goldfish Project:
- 一个包含结构化语言数据的项目。它为该数据集提供了额外的见解和潜在的跨语言信息。
许可
该数据集在CC-BY-SA 4.0许可下发布。这意味着您可以使用、分享和修改它,前提是给予适当的归属。
搜集汇总
数据集介绍
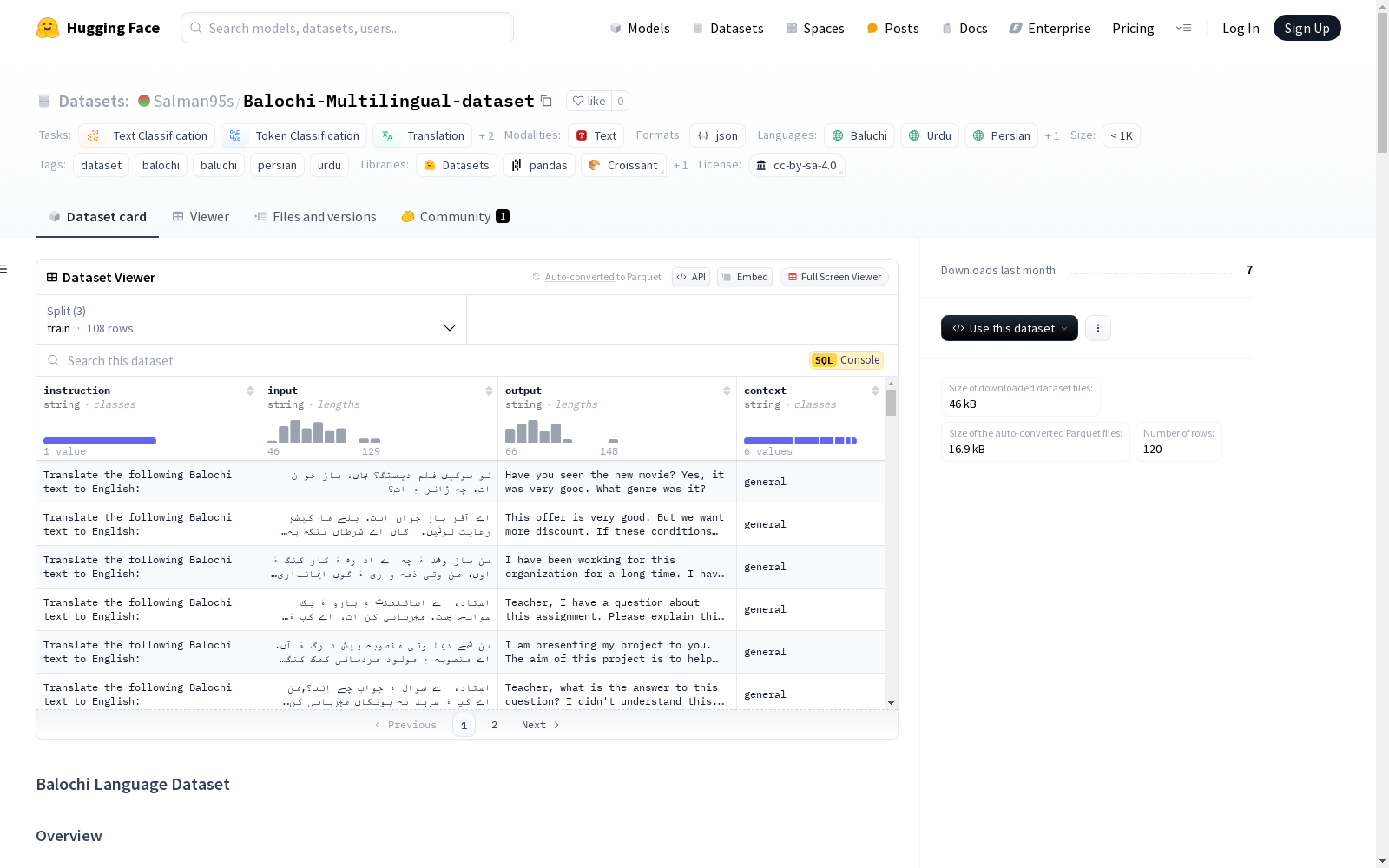
构建方式
该数据集的构建基于多种高质量的资源,旨在为巴洛奇语(Balochi)提供全面的语言模型训练支持。数据集整合了来自GlotSparse、GlotCC-V1、URL-NLP Repository、PanLex Meanings、Goldfish Project等多个来源的文本数据,涵盖了巴洛奇语的单语文本、多语言翻译语料以及多种领域和场景的对话样本。这些数据经过精心筛选和格式化,确保了其在模型训练中的适用性和多样性。
特点
该数据集具有显著的多语言和多领域特点。它不仅包含了巴洛奇语的单语文本,还提供了与英语、乌尔都语和波斯语的多语言翻译对,支持跨语言的翻译任务。此外,数据集涵盖了从日常对话到专业场景、从文学到技术术语的广泛领域,为构建生成式AI、翻译系统和文化研究提供了丰富的素材。
使用方法
该数据集适用于多种自然语言处理任务,包括文本分类、命名实体识别、翻译、文本生成和问答系统。用户可以通过加载数据集并根据具体任务需求进行预处理和模型训练。建议在使用过程中注意数据中的潜在偏见和敏感内容,并根据需要进行后处理和过滤,以确保模型的公平性和安全性。
背景与挑战
背景概述
Balochi-Multilingual-dataset 是一个专门为巴洛奇语(Balochi)设计的多功能数据集,旨在推动该语言在大型语言模型(LLMs)中的应用。该数据集由多个研究机构和项目共同开发,包括乌普萨拉大学(Uppsala University)的巴洛奇语言项目,以及GlotSparse、GlotCC-V1等数据源。其核心研究问题是如何在巴洛奇语中实现生成式文本、多语言翻译以及对话式AI功能,从而促进该语言在文化、教育和科技等领域的应用。该数据集的创建不仅填补了巴洛奇语在自然语言处理领域的空白,还为跨语言交流和文化传承提供了重要支持。
当前挑战
Balochi-Multilingual-dataset 在构建过程中面临多项挑战。首先,巴洛奇语作为一种小众语言,其数据资源相对匮乏,导致数据集的多样性和代表性难以保证。其次,多语言翻译任务中,巴洛奇语与其他语言(如英语、乌尔都语和波斯语)之间的翻译质量参差不齐,可能需要人工校对以确保准确性。此外,数据集中可能存在潜在的偏见和敏感内容,尽管已进行清理,但仍需进一步的过滤和处理。最后,巴洛奇语的方言和区域变体多样,如何在数据集中平衡这些差异也是一个重要挑战。
常用场景
经典使用场景
Balochi-Multilingual-dataset 数据集的经典使用场景主要集中在巴洛奇语的生成式人工智能、多语言翻译以及文化洞察等领域。该数据集支持构建巴洛奇语的聊天机器人和生成式文本系统,能够实现巴洛奇语与英语、乌尔都语、波斯语之间的多语言翻译,并提供丰富的文化与历史文本背景,适用于技术、教育和助手型任务。
实际应用
在实际应用中,Balochi-Multilingual-dataset 数据集广泛应用于多个领域。例如,在教育领域,它可以用于开发巴洛奇语的教学辅助工具,帮助学生更好地理解和使用该语言。在旅游行业,该数据集支持构建多语言翻译系统,提升游客在巴洛奇语地区的沟通体验。此外,在文化保护与传播方面,该数据集为巴洛奇语的文化与历史文本提供了数字化支持,促进了该语言的文化传承与推广。
衍生相关工作
Balochi-Multilingual-dataset 数据集的发布催生了一系列相关研究与应用。例如,基于该数据集的生成式文本模型被用于开发巴洛奇语的聊天机器人,提升了对话系统的自然度和流畅性。同时,多语言翻译模型的研究也得到了推动,特别是在巴洛奇语与其他语言之间的翻译精度上取得了显著进展。此外,该数据集还激发了对巴洛奇语语法和语义的深入研究,为语言学领域的学者提供了宝贵的研究素材。
以上内容由遇见数据集搜集并总结生成


