BEE-spoke-data/yahoo_answers_topics-long-text
收藏Hugging Face2024-02-19 更新2024-03-04 收录
下载链接:
https://hf-mirror.com/datasets/BEE-spoke-data/yahoo_answers_topics-long-text
下载链接
链接失效反馈官方服务:
资源简介:
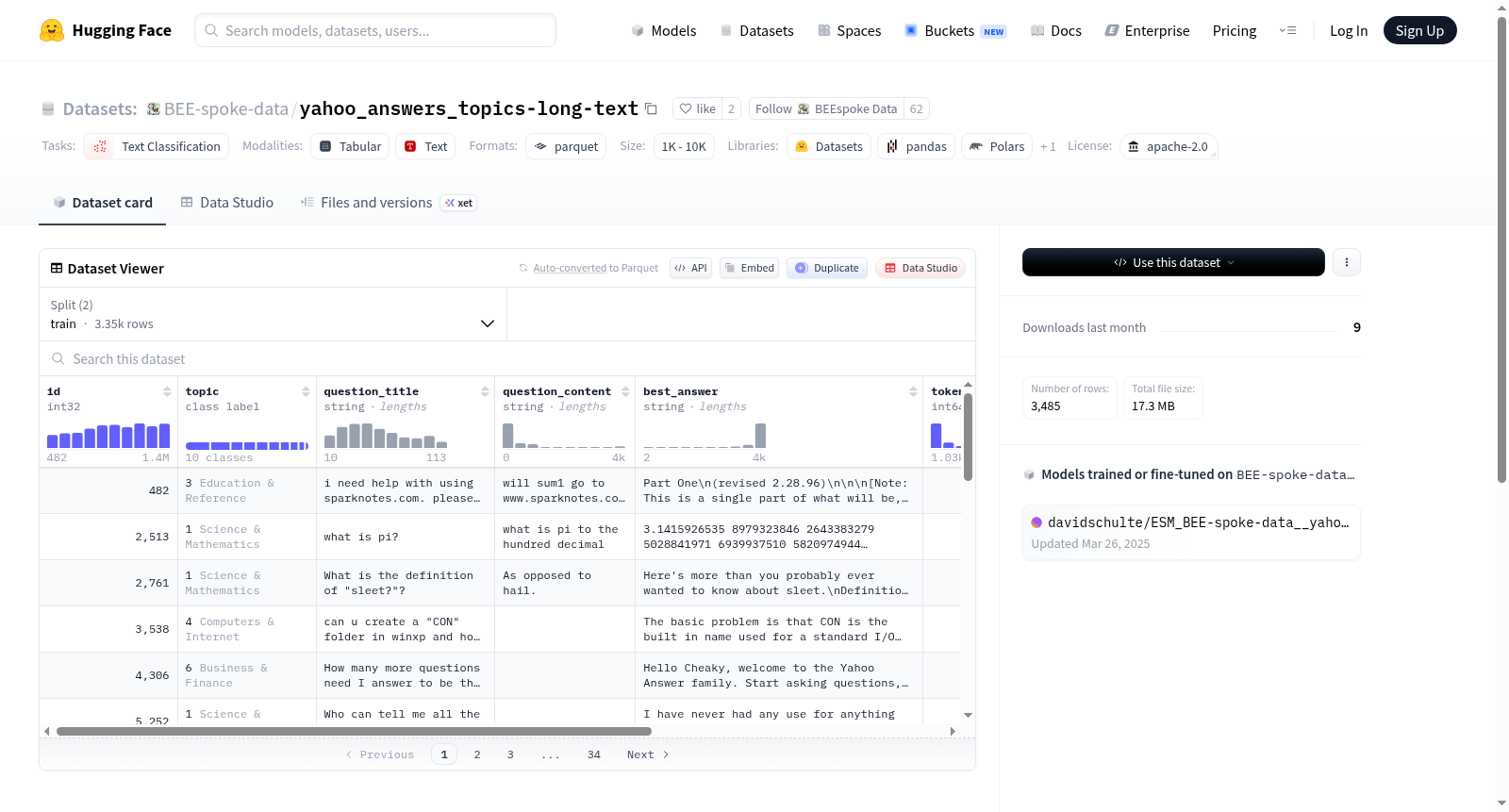
该数据集基于yahoo_answers_topics,用于文本分类任务。数据集包含多个特征,如id、主题、问题标题、问题内容、最佳答案、token计数、文本和标签。数据集分为训练集和测试集,分别包含3352和133个样本。文本长度至少为1024个token。
该数据集基于yahoo_answers_topics,用于文本分类任务。数据集包含多个特征,如id、主题、问题标题、问题内容、最佳答案、token计数、文本和标签。数据集分为训练集和测试集,分别包含3352和133个样本。文本长度至少为1024个token。
提供机构:
BEE-spoke-data
原始信息汇总
数据集概述
基本信息
- 许可证: Apache 2.0
- 来源数据集: yahoo_answers_topics
- 任务类别: 文本分类
数据集特征
- id: 整数类型 (int32)
- topic: 类别标签,包括以下类别:
- 0: 社会与文化
- 1: 科学与数学
- 2: 健康
- 3: 教育与参考
- 4: 计算机与互联网
- 5: 体育
- 6: 商业与金融
- 7: 娱乐与音乐
- 8: 家庭与关系
- 9: 政治与政府
- question_title: 字符串类型 (string)
- question_content: 字符串类型 (string)
- best_answer: 字符串类型 (string)
- token_count: 整数类型 (int64)
- text: 字符串类型 (string)
- label: 字符串类型 (string)
数据集分割
- 训练集:
- 字节数: 27806643
- 样本数: 3352
- 测试集:
- 字节数: 1097817
- 样本数: 133
数据集大小
- 下载大小: 17288090 字节
- 数据集大小: 28904460 字节
配置
- 默认配置:
- 训练集路径: data/train-*
- 测试集路径: data/test-*
额外信息
- 文本特征: text 字段包含 1024 个或更多令牌
搜集汇总
数据集介绍
构建方式
在自然语言处理领域,长文本分类任务一直是研究的难点与热点。该数据集源自雅虎问答平台,是对经典yahoo_answers_topics数据集的深度扩展与重构。其构建核心在于筛选出文本长度超过1024个token的样本,从而聚焦于长序列场景。原始数据中的问题标题、问题内容与最佳答案被拼接为单一文本字段,同时保留主题标签作为分类目标。数据集划分为训练集(3352条)和测试集(133条),并以Apache-2.0许可证开放,为长文本分类研究提供了高质量的基础资源。
使用方法
该数据集在HuggingFace上以标准格式提供,可通过datasets库直接加载。使用时需指定配置名'default',并选择'train'或'test'拆分。数据字段中包含'text'作为输入文本,'label'作为分类标签,可直接用于训练序列分类模型。由于样本长度较长,建议在预处理时采用动态填充或截断策略,以适应不同模型的最大输入限制。研究者亦可利用'question_title'、'question_content'等原始字段进行多模态或注意力机制相关的实验设计,探索长文本中的信息融合方法。
背景与挑战
背景概述
在自然语言处理领域,文本分类任务一直是研究热点,其核心在于从非结构化文本中精准提取语义信息并归入预定义类别。BEE-spoke-data/yahoo_answers_topics-long-text数据集应运而生,由BEE-spoke-data团队于近年创建,旨在解决长文本主题分类的细粒度挑战。该数据集源自经典的Yahoo Answers Topics语料,但创新性地筛选出文本长度超过1024个token的样本,聚焦于问答社区中复杂、信息密集的场景。数据集涵盖十大主题,如社会文化、科学与数学、健康等,训练集包含3352条样本,测试集133条,每条记录保留问题标题、内容、最佳答案及拼接后的长文本。其发布为长文本语义理解、主题建模及大规模分类模型提供了高价值基准,尤其推动了对冗长、多轮对话式文本的自动分析能力,在社区问答系统与知识图谱构建中具有显著影响力。
当前挑战
该数据集所面临的挑战首先体现在领域问题上:长文本分类需克服长度衰减效应,即传统模型在处理超过512或1024个token的序列时,因位置编码与注意力机制的限制,难以捕获远距离依赖关系,导致主题识别精度下降。此外,Yahoo Answers内容口语化、噪声多,存在拼写错误、语法不规范及多主题交织现象,加剧了分类歧义。构建过程中,数据筛选与清洗是另一重困难:从原始语料中提取长度达标的样本需平衡代表性与规模,而拼接问题标题、内容与最佳答案为单一文本时,可能引入语义冗余或矛盾信息,需设计合理的融合策略以保持主题一致性。标注质量也受限于原始社区标签的模糊性,部分样本的类别边界不清晰,增加了监督学习的噪声干扰。
常用场景
经典使用场景
在文本分类与自然语言理解的研究领域中,BEE-spoke-data/yahoo_answers_topics-long-text数据集以其长文本特性而独树一帜。该数据集源自雅虎问答平台,汇聚了用户提出的问题标题、详细内容以及最佳回答,并标注了涵盖社会文化、科学与数学、健康等十大主题类别。其经典使用场景在于训练和评估能够处理长序列文本的深度学习模型,例如基于Transformer架构的模型,以精准捕捉长距离语义依赖关系,从而提升主题分类的准确率与鲁棒性。
解决学术问题
该数据集有效解决了传统短文本数据集在长文本分类研究中面临的样本匮乏与信息截断问题。学术研究中,长文本常包含冗余信息与复杂逻辑,导致模型难以提取关键特征。通过提供超过1024个token的完整文本,该数据集助力研究者探索高效的长文本编码策略、注意力机制优化及上下文理解方法,推动了自然语言处理领域在长文档分类、信息检索与问答系统等方向的理论突破与方法创新。
实际应用
在实际应用中,该数据集为智能客服系统、在线教育平台及社交媒体内容审核等领域提供了坚实的数据支撑。基于该数据集训练的模型能够自动识别用户问题的主题领域,从而快速分配至对应的专家或知识库,显著提升服务效率与用户满意度。此外,其长文本特性使得模型能够深入理解复杂咨询内容,在金融、医疗等专业场景中实现精准的意图识别与知识推荐。
数据集最近研究
最新研究方向
长文本分类与语义理解的深度探索。在自然语言处理领域,随着预训练语言模型上下文窗口的不断扩展,对超长文档级文本的精细分类成为前沿热点。该数据集精选雅虎问答中令牌数超过1024的问答对,聚焦于社会文化、科学数学等十大主题,为研究长距离依赖建模、关键信息抽取及噪声文本中的主题判别提供了极具挑战的基准。其意义在于推动模型从短文本标签预测向复杂叙事理解演进,尤其契合当前对用户生成内容中隐含意图与细粒度语义剖析的迫切需求,为构建更鲁棒的在线内容理解系统奠定了数据基石。
以上内容由遇见数据集搜集并总结生成


