TemporalBench
收藏魔搭社区2025-12-05 更新2025-07-26 收录
下载链接:
https://modelscope.cn/datasets/microsoft/TemporalBench
下载链接
链接失效反馈官方服务:
资源简介:
# Dataset Card
**Dataset is released now!**
<!-- insert an figure here -->
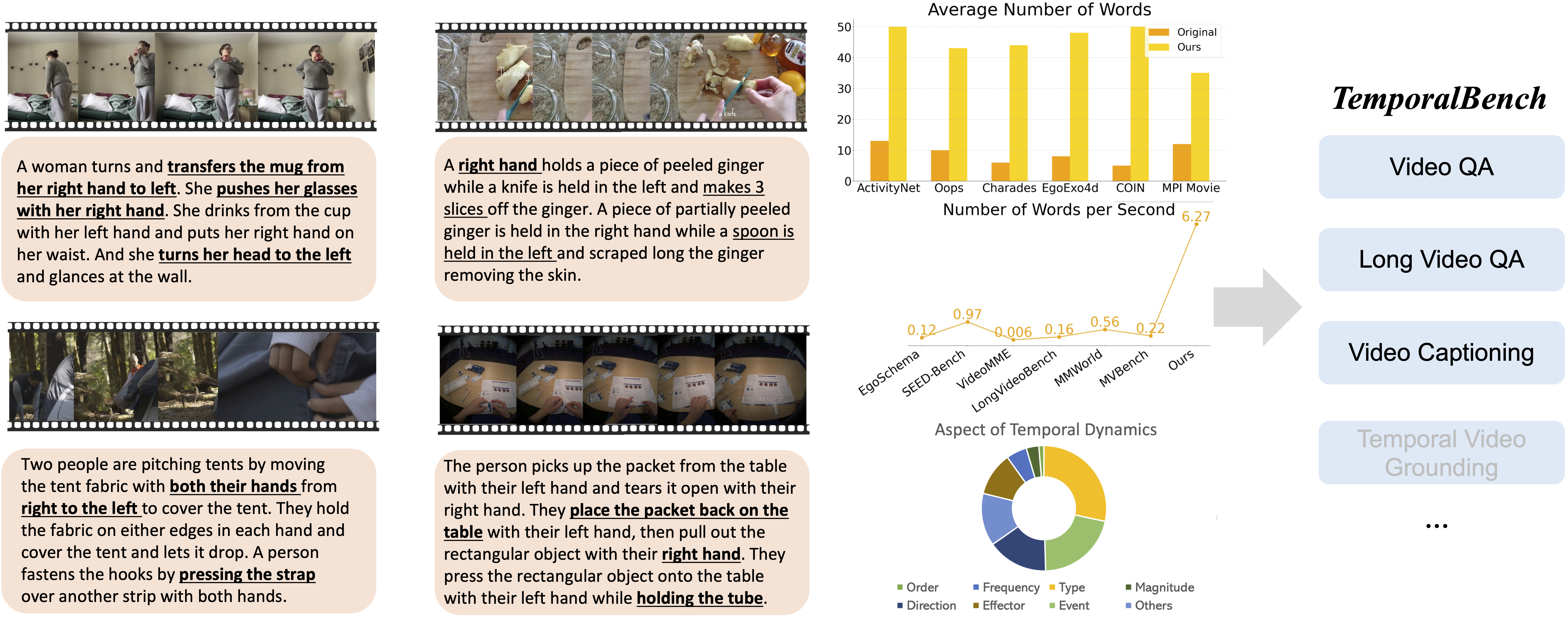
[[Project Page]](https://temporalbench.github.io/) [[arXiv]](https://arxiv.org/abs/2410.10818) [[code]](https://github.com/mu-cai/TemporalBench) [[Leaderboard]](https://temporalbench.github.io/#leaderboard)
**TemporalBench** is a video understanding benchmark designed to evaluate fine-grained temporal reasoning for multimodal video models. It consists of ∼10K video question-answer pairs sourced from ∼2K high-quality human-annotated video captions, capturing detailed temporal dynamics and actions.
### Dataset Description
- **Curated by:** Mu Cai, Reuben Tan, Jianfeng Gao, Yong Jae Lee, Jianwei Yang, etc.
- **Language(s):** English
- **License:** MIT
### Dataset Sources
<!-- Provide the basic links for the dataset. -->
- **Paper:** [TemporalBench: Benchmarking Fine-Grained Temporal Understanding for Multimodal Video Models](https://arxiv.org/abs/2410.10818)
### Direct Use
<!-- This section describes suitable use cases for the dataset. -->
The dataset is useful for assessing the temporal reasoning abilities of multimodal models, particularly fine-grained video understanding, long-term video understanding, and video captioning with rich details.
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the dataset will not work well for. -->
The dataset is not intended for use in non-temporal video tasks.
## Dataset Structure
### Data Instances
Each data instance in the dataset consists of a question-answer pair based on a video clip. Below is an example from the dataset:
```python
{
"idx": "short_video/Charades/EEVD3_start_11.4_end_16.9.mp4_0",
"video_name": "short_video/Charades/EEVD3_start_11.4_end_16.9.mp4",
"category": "Action Effector",
"source_dataset": "Charades",
"question": "Which caption best describes this video?\nA. A person closes the door of the fridge with his left hand while looking at the bowl of fruit he holds in his right hand. He transfers the bowl from his right hand to his left hand. He picks up a fruit from the bowl with his left hand. He tosses the fruit up with his left hand and catches it with the same hand while walking forward. \nB. A person closes the door of the fridge with his left hand while looking at the bowl of fruit he holds in his right hand. He transfers the bowl from his right hand to his left hand. He picks up a fruit from the bowl with his right hand. He tosses the fruit up with his right hand and catches it with the same hand while walking forward.\nAnswer with the option's letter from the given choices directly.",
"GT": "B"
}
```
### Data Fields
- `idx`: A string representing the video identifier.
- `video_name`: Video path
- `question`: A string containing the question related to the video.
- `GT`: A string containing the correct answer.
### Data Splits
The dataset is split into the following:
- `test`: 9867 rows
## Dataset Creation
This dataset was created from human annotators with fine-grained temporal annotations. The videos were sampled from various sources, including procedural videos and human activities.
### Source Data
- ActivityNet-Captions, COIN, Charades-STA, FineGym, Oops, Movei Description, EgoExo4d,
#### Data Collection and Processing
Refer to the main paper for detailed information about the data collection and curation process.
#### Personal and Sensitive Information
No personal or sensitive information is contained in this dataset.
## Bias, Risks, and Limitations
TemporalBench is made for academic research purposes only. Commercial use in any form is strictly prohibited.
The copyright of all videos belong to their respective owners. We do not own any of the videos.
Any form of unauthorized distribution, publication, copying, dissemination, or modifications made over TemporalBench in part or in whole is strictly prohibited.
You cannot access our dataset unless you comply to all the above restrictions and also provide your information for legal purposes.
This dataset is foucsing on fine-grained temporal tasks rather than coarse-grained video understanding.
## Citation
If you find this work useful, please cite:
```
@article{cai2024temporalbench,
title={TemporalBench: Towards Fine-grained Temporal Understanding for Multimodal Video Models},
author={Cai, Mu and Tan, Reuben and Zhang, Jianrui and Zou, Bocheng and Zhang, Kai and Yao, Feng and Zhu, Fangrui and Gu, Jing and Zhong, Yiwu and Shang, Yuzhang and Dou, Yao and Park, Jaden and Gao, Jianfeng and Lee, Yong Jae and Yang, Jianwei},
journal={arXiv preprint arXiv:2410.10818},
year={2024}
}
```
# 数据集卡片
**数据集现已正式发布!**

[[项目主页]](https://temporalbench.github.io/) [[arXiv预印本]](https://arxiv.org/abs/2410.10818) [[代码仓库]](https://github.com/mu-cai/TemporalBench) [[排行榜]](https://temporalbench.github.io/#leaderboard)
**TemporalBench** 是一款用于评估多模态视频模型(multimodal video models)细粒度时序推理能力的视频理解基准(video understanding benchmark)。该数据集包含约1万个问答对(question-answer pairs),源自约2000条高质量人工标注的视频字幕,涵盖了细致的时序动态与动作细节。
### 数据集描述
- **整理方:** Mu Cai、Reuben Tan、Jianfeng Gao、Yong Jae Lee、Jianwei Yang 等
- **语言:** 英语
- **许可证:** MIT许可证(MIT)
### 数据集来源
- **学术论文:** [TemporalBench: Benchmarking Fine-Grained Temporal Understanding for Multimodal Video Models](https://arxiv.org/abs/2410.10818)
### 直接适用场景
本数据集可用于评估多模态模型的时序推理能力,尤其适用于细粒度视频理解、长时序视频理解以及富含细节的视频字幕生成任务。
### 不适用场景
本数据集并非为非时序视频任务设计,不适用于此类场景。
## 数据集结构
### 数据实例
数据集中的每个实例均为基于一段视频片段的问答对。以下为数据集中的一个示例:
python
{
"idx": "short_video/Charades/EEVD3_start_11.4_end_16.9.mp4_0",
"video_name": "short_video/Charades/EEVD3_start_11.4_end_16.9.mp4",
"category": "Action Effector",
"source_dataset": "Charades",
"question": "Which caption best describes this video?
A. A person closes the door of the fridge with his left hand while looking at the bowl of fruit he holds in his right hand. He transfers the bowl from his right hand to his left hand. He picks up a fruit from the bowl with his left hand. He tosses the fruit up with his left hand and catches it with the same hand while walking forward.
B. A person closes the door of the fridge with his left hand while looking at the bowl of fruit he holds in his right hand. He transfers the bowl from his right hand to his left hand. He picks up a fruit from the bowl with his right hand. He tosses the fruit up with his right hand and catches it with the same hand while walking forward.
Answer with the option's letter from the given choices directly.",
"GT": "B"
}
### 数据字段说明
- `idx`:表示视频标识符的字符串
- `video_name`:视频路径
- `question`:包含与该视频相关问题的字符串
- `GT`:包含正确答案的字符串
### 数据拆分
数据集拆分如下:
- `test`(测试集):共9867条数据
## 数据集创建
本数据集由具备细粒度时序标注能力的人工标注人员构建,视频片段取自多种来源,包括流程类视频与人类活动视频。
### 源数据
- ActivityNet-Captions、COIN、Charades-STA、FineGym、Oops、Movie Description、EgoExo4d
#### 数据收集与处理流程
详细的数据收集与整理流程请参阅主论文。
#### 个人与敏感信息
本数据集未包含任何个人或敏感信息。
## 偏见、风险与局限性
TemporalBench仅用于学术研究目的,严格禁止任何形式的商业使用。
所有视频的版权归其各自所有者所有,本项目不拥有任何视频的版权。
严禁对TemporalBench的全部或部分内容进行任何形式的未经授权的分发、发布、复制、传播或修改。
除非您遵守上述所有限制并提供用于合规用途的个人信息,否则无法获取本数据集。
本数据集聚焦于细粒度时序任务,而非粗粒度视频理解。
## 引用信息
若您认为本工作对您有所帮助,请引用以下文献:
@article{cai2024temporalbench,
title={TemporalBench: Towards Fine-grained Temporal Understanding for Multimodal Video Models},
author={Cai, Mu and Tan, Reuben and Zhang, Jianrui and Zou, Bocheng and Zhang, Kai and Yao, Feng and Zhu, Fangrui and Gu, Jing and Zhong, Yiwu and Shang, Yuzhang and Dou, Yao and Park, Jaden and Gao, Jianfeng and Lee, Yong Jae and Yang, Jianwei},
journal={arXiv preprint arXiv:2410.10818},
year={2024}
}
提供机构:
maas
创建时间:
2025-07-22
搜集汇总
数据集介绍
背景与挑战
背景概述
TemporalBench是一个用于评估多模态视频模型细粒度时间推理能力的视频理解基准测试,包含约10K个视频问答对,源自约2K个高质量人工标注的视频字幕,专注于捕捉视频中的详细时间动态和动作。数据集仅用于学术研究,禁止商业用途,数据以英语为主,采用MIT许可证。
以上内容由遇见数据集搜集并总结生成


