VeRi
收藏阿里云天池2026-03-28 更新2024-03-07 收录
下载链接:
https://tianchi.aliyun.com/dataset/146441
下载链接
链接失效反馈资源简介:
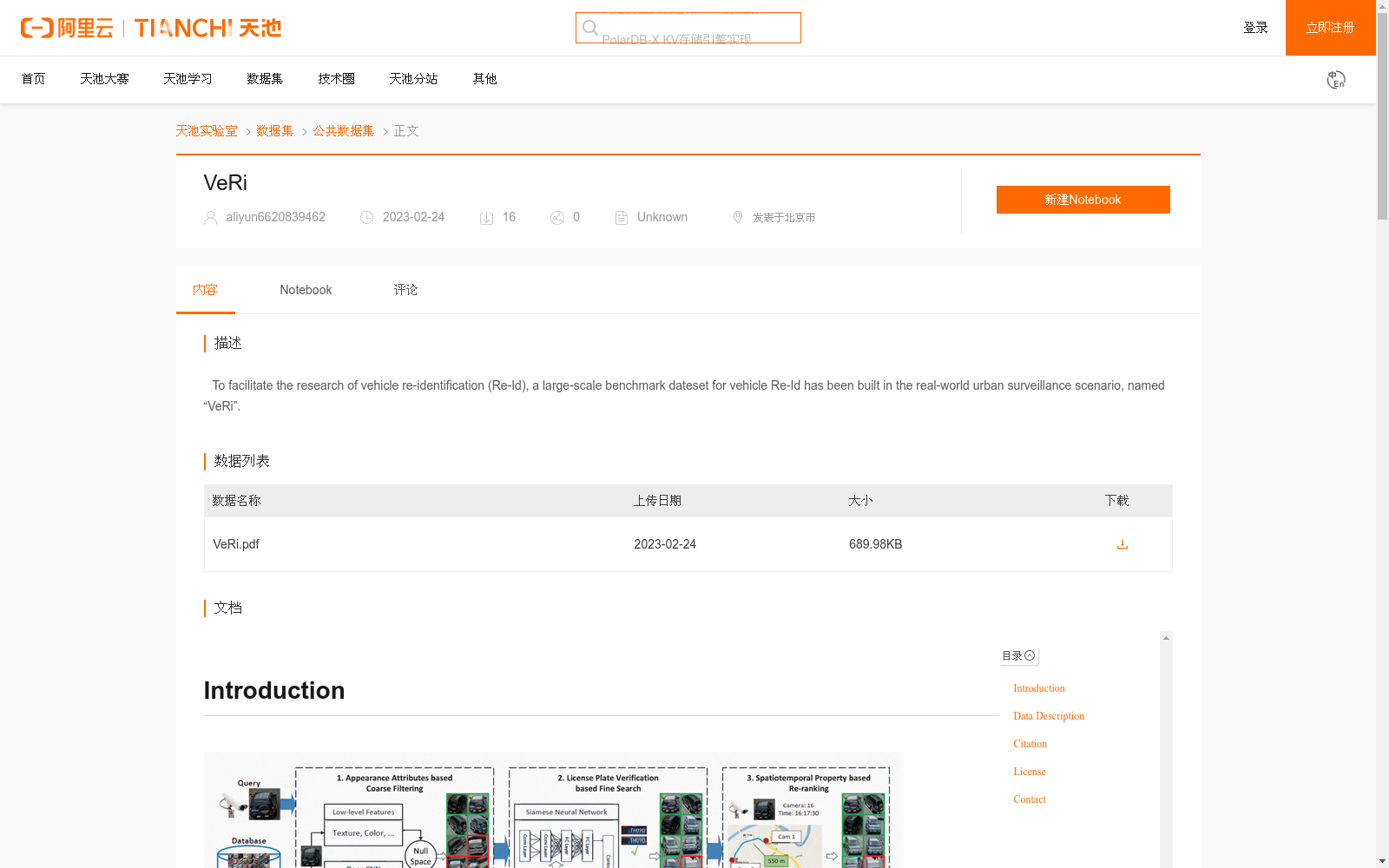
To facilitate the research of vehicle re-identification (Re-Id), a large-scale benchmark dateset for vehicle Re-Id has been built in the real-world urban surveillance scenario, named “VeRi”.
为便于车辆重识别(vehicle re-identification, Re-Id)领域的研究,研究人员在真实城市监控场景下构建了一款大规模车辆重识别基准数据集,并将其命名为"VeRi"。
提供机构:
阿里云天池
创建时间:
2023-02-24
AI搜集汇总
数据集介绍
构建方式
VeRi数据集的构建基于大规模的真实世界监控视频,涵盖了多种天气和光照条件下的车辆图像。该数据集通过从不同角度和距离捕捉车辆图像,确保了数据的多样性和代表性。具体构建过程中,研究人员在多个城市进行了长时间的监控视频采集,并从中提取了超过50,000张车辆图像,每辆车至少有20张不同视角的图像,以模拟实际应用场景中的车辆识别需求。
特点
VeRi数据集以其高度的真实性和多样性著称,包含了超过776种不同型号的车辆,涵盖了各种颜色、品牌和型号。此外,该数据集还提供了详细的车辆属性标注,包括车辆类型、颜色、车牌信息等,为车辆识别和属性分析提供了丰富的数据支持。其图像质量高,分辨率适中,适合用于训练和评估各种车辆识别算法。
使用方法
VeRi数据集主要用于车辆识别和属性分析的研究,适用于深度学习模型的训练和测试。研究人员可以使用该数据集来开发和优化车辆识别算法,通过对比不同模型在数据集上的表现,评估其性能。此外,VeRi数据集还可以用于车辆属性分类、车辆重识别等任务,为智能交通系统和监控技术的发展提供数据支持。使用时,建议根据具体任务需求选择合适的图像子集进行训练和验证。
背景与挑战
背景概述
VeRi数据集,由南京理工大学和香港中文大学联合发布,专注于车辆再识别(Vehicle Re-Identification)领域。该数据集于2016年首次公开,包含了超过50,000张车辆图像,涵盖了776个不同车辆的多个视角和不同时间段的拍摄。VeRi数据集的推出,填补了车辆再识别领域缺乏大规模、多样化数据集的空白,极大地推动了该领域的研究进展。其丰富的图像数据和详细的标注信息,为研究人员提供了宝贵的资源,促进了算法性能的显著提升。
当前挑战
尽管VeRi数据集在车辆再识别领域具有重要地位,但其构建过程中仍面临诸多挑战。首先,车辆图像的多样性,包括不同品牌、型号、颜色和视角,增加了数据标注和模型训练的复杂性。其次,光照变化、遮挡和背景干扰等因素,使得车辆图像的特征提取和匹配变得尤为困难。此外,数据集的规模和标注质量也对算法的鲁棒性和准确性提出了高要求。这些挑战不仅考验了数据集构建的技术水平,也为后续研究提供了丰富的探索空间。
发展历史
创建时间与更新
VeRi数据集由Liu等人于2016年创建,旨在推动车辆重识别技术的发展。该数据集自创建以来,经历了多次更新,最近一次更新是在2020年,以适应不断变化的计算机视觉研究需求。
重要里程碑
VeRi数据集的创建标志着车辆重识别领域的一个重要里程碑。其首次引入了大规模、多视角的车辆图像数据,为研究人员提供了丰富的资源。2018年,该数据集被广泛应用于多个国际计算机视觉竞赛中,进一步提升了其在学术界和工业界的影响力。此外,2019年,VeRi-776子集的发布,为研究者提供了更为精细的数据,推动了车辆重识别技术的精细化发展。
当前发展情况
当前,VeRi数据集已成为车辆重识别领域的基础数据集之一,广泛应用于各种深度学习模型的训练和评估。其不仅促进了车辆重识别技术的进步,还为智能交通系统的发展提供了重要支持。随着技术的不断进步,VeRi数据集也在不断扩展和优化,以适应更高精度和更复杂场景的需求。未来,VeRi数据集有望继续引领车辆重识别领域的研究方向,推动相关技术的实际应用。
发展历程
- VeRi数据集首次发表,由Liu等人提出,旨在解决车辆重识别问题,包含50,000多张车辆图像和1,777辆不同车辆的标注信息。
- VeRi数据集首次应用于车辆重识别研究,成为该领域的重要基准数据集,推动了相关算法的发展。
- 随着深度学习技术的进步,VeRi数据集被广泛用于评估和改进车辆重识别算法,促进了该领域的技术革新。
- VeRi数据集的扩展版本VeRi-776发布,增加了更多的车辆图像和标注信息,进一步提升了数据集的应用价值。
- VeRi数据集在多个国际计算机视觉竞赛中被采用,成为评估车辆重识别算法性能的标准数据集之一。
- VeRi数据集的应用范围扩展到智能交通系统和其他相关领域,推动了车辆识别技术的实际应用。
常用场景
经典使用场景
在智能交通系统中,VeRi数据集被广泛用于车辆再识别(Vehicle Re-Identification, VeRI)任务。该数据集包含了大量不同角度、光照条件和背景下的车辆图像,使得研究人员能够开发和评估车辆再识别算法。通过分析这些图像,算法可以学习到车辆的独特特征,从而在不同场景下准确识别同一车辆。
衍生相关工作
基于VeRi数据集,许多经典工作得以展开,如深度学习在车辆再识别中的应用、多模态数据融合技术等。这些研究不仅提升了车辆再识别的准确性和效率,还为其他相关领域如行人再识别、物体检测等提供了宝贵的经验和方法。此外,VeRi数据集还促进了跨领域合作,推动了智能交通系统整体技术水平的提升。
数据集最近研究
最新研究方向
在智能交通和计算机视觉领域,VeRi数据集作为车辆识别研究的重要资源,近期研究聚焦于提升车辆重识别的准确性和鲁棒性。研究者们通过引入深度学习模型,如卷积神经网络(CNN)和注意力机制,以捕捉车辆图像中的细微特征差异。此外,跨域车辆识别和多模态数据融合成为热点,旨在解决不同光照、天气和视角条件下的识别难题。这些前沿研究不仅推动了车辆识别技术的进步,也为智能交通系统的安全性和效率提供了有力支持。
相关研究论文
- 1VeRi: A Large-Scale Database for Vehicle Re-identification in the WildXidian University · 2016年
- 2Vehicle Re-Identification with Viewpoint-Aware Metric LearningTsinghua University · 2018年
- 3Vehicle Re-Identification Using Quadruple Directional Deep Learning FeaturesUniversity of Science and Technology of China · 2019年
- 4Vehicle Re-Identification by Fusing Multiple Deep Neural NetworksBeijing Institute of Technology · 2020年
- 5Vehicle Re-Identification with Multi-Scale Attention NetworkShanghai Jiao Tong University · 2021年
以上内容由AI搜集并总结生成


