Formal Logic Deduction Diverse (FLD×2)
收藏arXiv2024-12-23 更新2024-06-21 收录
下载链接:
https://github.com/hitachi-nlp/FLD
下载链接
链接失效反馈官方服务:
资源简介:
Formal Logic Deduction Diverse (FLD×2)是由日立先进AI创新中心和谢菲尔德大学联合创建的合成逻辑推理语料库。该数据集包含大量多步骤推理样本,涵盖未知事实、多样化的推理规则、多样的语言表达以及具有挑战性的干扰项。数据集通过程序生成,遵循符号逻辑理论和经验设计原则,旨在提升大语言模型(LLMs)的推理能力。FLD×2主要应用于增强LLMs在逻辑推理、数学和编程等任务中的表现,旨在解决LLMs在复杂推理任务中的不足。
Formal Logic Deduction Diverse (FLD×2) is a synthetic logical reasoning corpus jointly developed by the Hitachi Advanced AI Innovation Center and the University of Sheffield. This dataset contains a large number of multi-step reasoning samples, covering unknown facts, diverse reasoning rules, varied linguistic expressions, and challenging distractors. The dataset is programmatically generated, adhering to symbolic logic theories and empirical design principles, aiming to improve the reasoning capabilities of Large Language Models (LLMs). FLD×2 is primarily used to enhance the performance of LLMs on tasks such as logical reasoning, mathematics, and programming, with the goal of addressing the limitations of LLMs in complex reasoning tasks.
提供机构:
日立先进AI创新中心, 谢菲尔德大学
创建时间:
2024-11-19
搜集汇总
数据集介绍
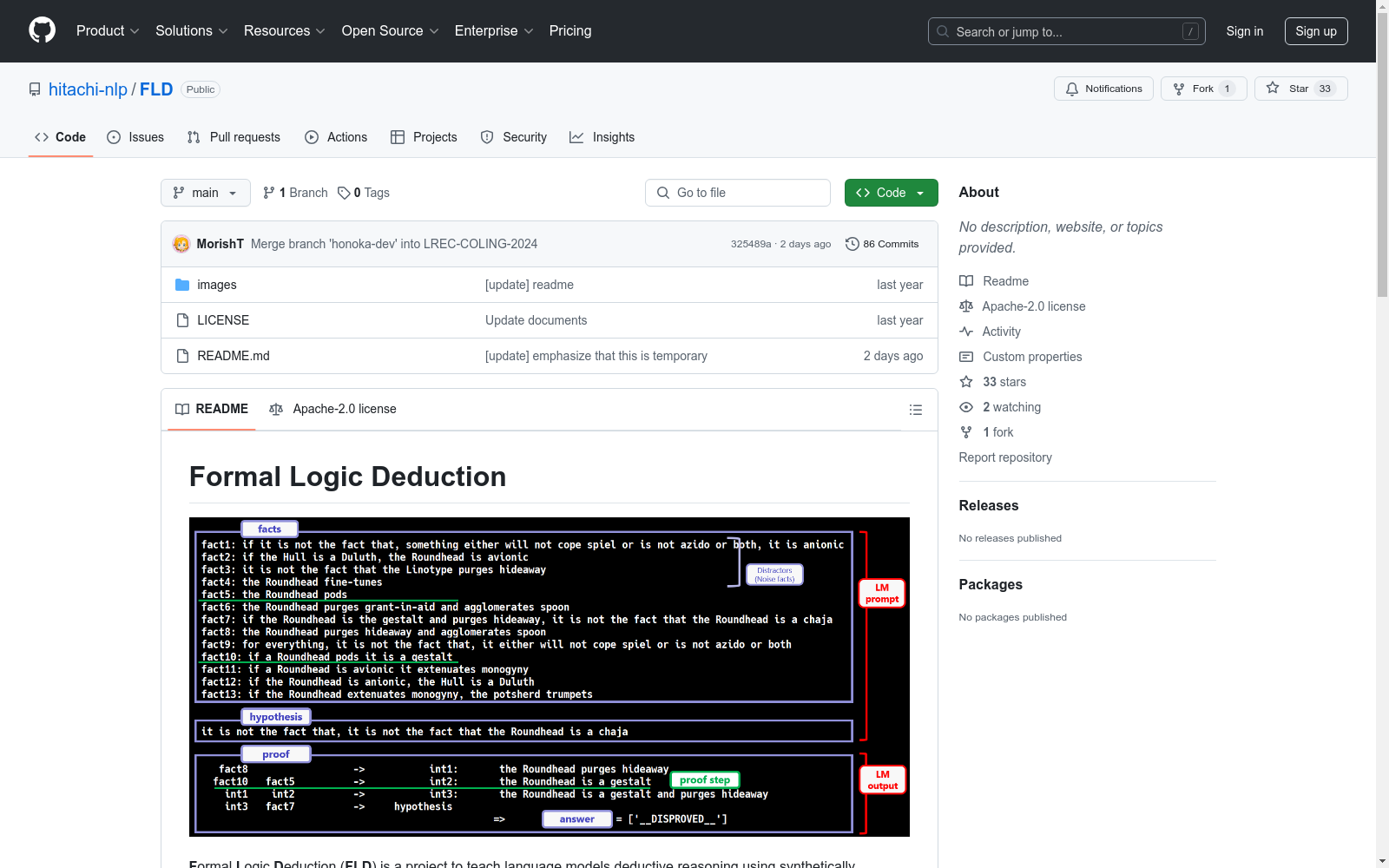
构建方式
Formal Logic Deduction Diverse (FLD×2)数据集的构建基于符号逻辑理论和先前的实证见解,通过计算机程序生成逻辑推理样本。该数据集包含大量多步骤推理样本,涉及未知事实、多样化的推理规则、多样化的语言表达以及具有挑战性的干扰项。构建过程中,首先确立了设计高质量样本的原则,然后根据这些原则生成合成语料库。
特点
FLD×2数据集的特点在于其包含了未知事实的推理样本,多样化的推理规则和语言表达,以及具有挑战性的干扰项。这些特点使得该数据集能够有效提升大语言模型(LLMs)的推理能力,特别是在处理未知和复杂推理任务时。
使用方法
FLD×2数据集主要用于训练大语言模型(LLMs),通过额外的逻辑训练(ALT)来增强其推理能力。使用该数据集时,模型需要根据提供的已知事实生成逻辑步骤,以推导出给定的假设。实验结果表明,经过ALT训练的LLMs在逻辑推理基准测试中显著提升了性能,包括在数学和编码基准测试中的表现。
背景与挑战
背景概述
Formal Logic Deduction Diverse (FLD×2) is a synthetic corpus designed to enhance the reasoning capabilities of large language models (LLMs). Developed by researchers from Hitachi and The University of Sheffield, this dataset was created to address the limitations of LLMs in handling reasoning tasks. The core research question revolves around improving LLMs' ability to perform multi-step logical deductions with unknown facts, diverse reasoning rules, and challenging distractors. The dataset's creation was guided by principles integrating symbolic logic theory and empirical insights, aiming to provide high-quality reasoning samples. The impact of FLD×2 is evidenced by its ability to substantially enhance the reasoning capabilities of state-of-the-art LLMs, including LLaMA-3.1-70B, as demonstrated through empirical results showing improvements in logical reasoning, math, and coding benchmarks.
当前挑战
The primary challenge addressed by FLD×2 is the limitation of LLMs in reasoning tasks, particularly in handling novel and unknown problems that require logical deduction. The construction of FLD×2 faced several challenges, including the need to design high-quality samples that integrate symbolic logic theory with empirical insights, and the requirement to generate diverse reasoning rules and linguistic expressions. Additionally, the dataset had to include challenging distractors to ensure that LLMs could distinguish between logical and illogical reasoning. The broader challenge is to ensure that the improvements in reasoning capabilities translate to various tasks beyond the original logical reasoning tasks, such as math and coding, and to evaluate the generalizability of these capabilities across different benchmarks.
常用场景
经典使用场景
Formal Logic Deduction Diverse (FLD×2) 数据集的经典使用场景在于通过合成生成的逻辑推理样本,增强大型语言模型(LLMs)的推理能力。该数据集包含了多步骤的演绎推理样本,涉及未知事实、多样化的推理规则和语言表达,以及具有挑战性的干扰项。通过在FLD×2上进行额外逻辑训练(ALT),可以显著提升LLMs在逻辑推理基准测试中的表现,如在逻辑推理任务中获得高达30分的提升。
衍生相关工作
FLD×2 数据集的提出催生了一系列相关研究工作,包括但不限于对合成逻辑样本设计原则的深入探讨、对不同逻辑系统(如模态逻辑和线性逻辑)的扩展研究,以及对其他推理类型(如溯因推理和归纳推理)的探索。此外,基于FLD×2的训练方法也被应用于其他领域,如数学和编程任务,进一步验证了其通用性和有效性。
数据集最近研究
最新研究方向
在形式逻辑推理领域,最新研究方向聚焦于通过合成逻辑语料库提升大型语言模型(LLMs)的推理能力。研究者提出了一种名为Additional Logic Training(ALT)的方法,通过程序生成的逻辑推理样本,旨在增强LLMs的推理能力。该方法首先确立了设计高质量样本的原则,结合符号逻辑理论和先前的实证见解,构建了一个名为Formal Logic Deduction Diverse(FLD×2)的合成语料库。该语料库包含多步骤推理样本,涉及未知事实、多样化的推理规则、多样化的语言表达和具有挑战性的干扰项。实证结果表明,基于FLD×2的ALT显著提升了最先进LLMs的推理能力,包括在逻辑推理基准测试中取得了高达30分的提升。
相关研究论文
- 1Enhancing Reasoning Capabilities of LLMs via Principled Synthetic Logic Corpus日立先进AI创新中心, 谢菲尔德大学 · 2024年
以上内容由遇见数据集搜集并总结生成


