电影实时票房与预售票房数据集
收藏北京市数据知识产权2023-12-11 更新2024-05-08 收录
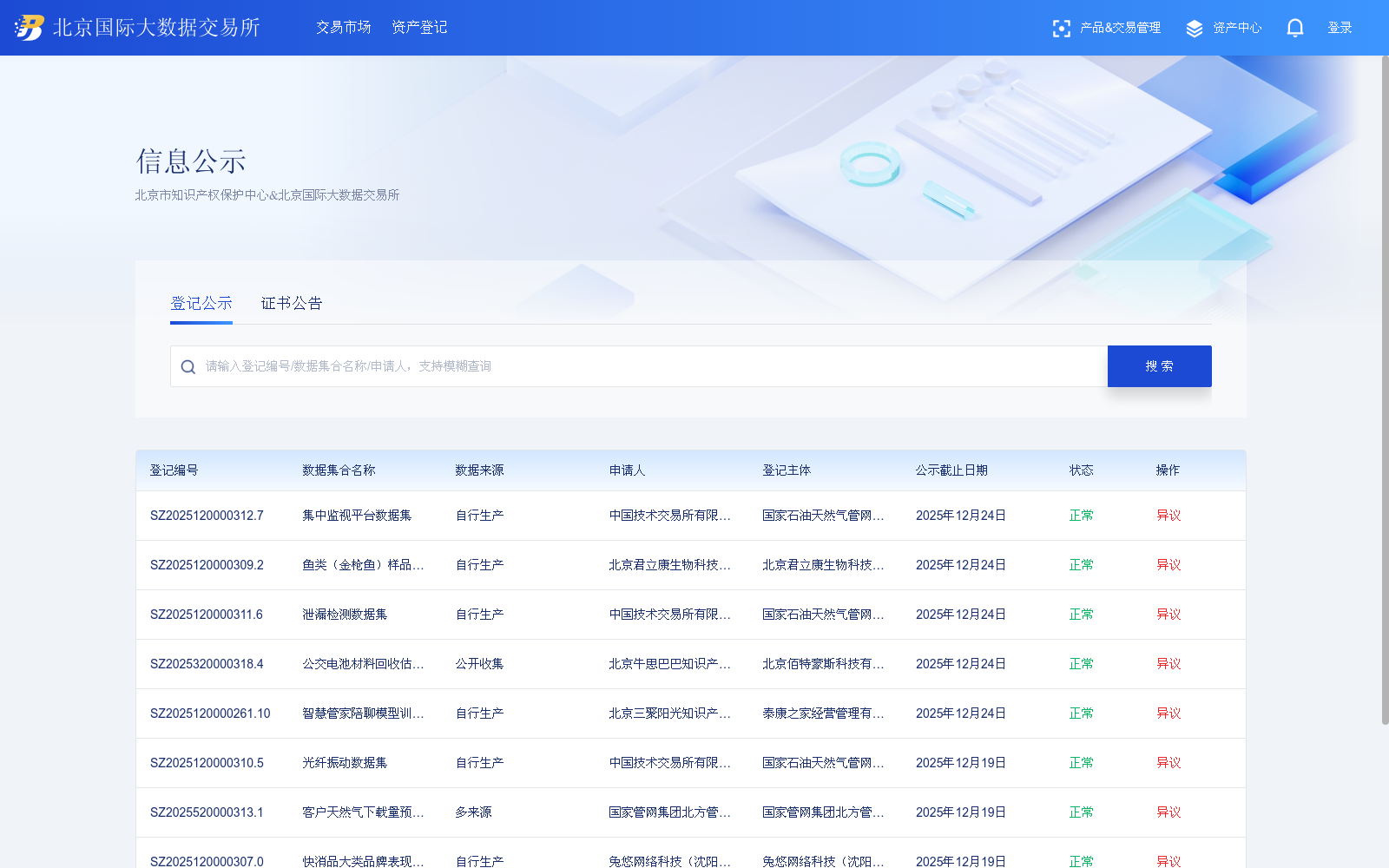
下载链接:
https://webs.bjidex.com/sys-bsc-home/#/bscConsole/intellectualProperty/infoPublicity?action=1
下载链接
链接失效反馈资源简介:
通过电影票售票平台的售票情况、平均票价信息,收集和估算当日实时及未来预售票房数据,数据维度覆盖全国、各省市自治区及个体影院,为电影出品方、宣发方、影院经营者、媒体等电影产业相关从业者提供实时数据参考,提高决策时效与准确度。
This dataset collects and estimates real-time same-day and future pre-sale box office data based on ticket sales status and average ticket price information from movie ticket booking platforms. Its data dimensions cover the entire country, all provinces, municipalities, autonomous regions and individual cinemas. It provides real-time data references for relevant practitioners in the film industry such as film producers, distribution and promotion parties, cinema operators and media, so as to improve the timeliness and accuracy of their decision-making.
提供机构:
北京阿里巴巴影业文化有限公司
AI搜集汇总
数据集介绍
以上内容由AI搜集并总结生成


