EgoSPT
收藏arXiv2026-05-20 更新2026-05-21 收录
下载链接:
https://jackyfl.github.io/SP-VTP-project-page/
下载链接
链接失效反馈官方服务:
资源简介:
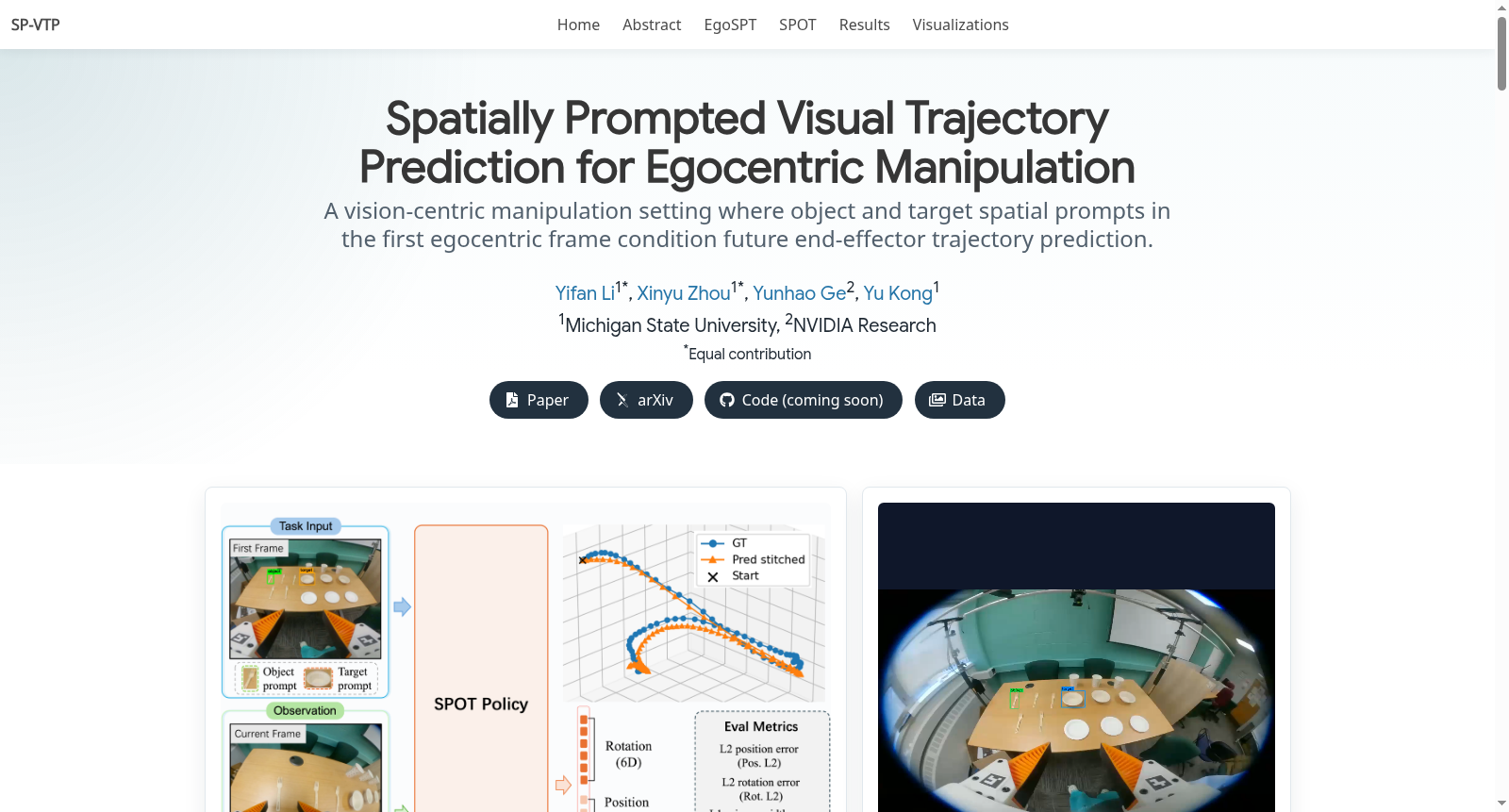
EgoSPT是由密歇根州立大学与英伟达研究院联合创建的具身智能空间提示操作数据集,旨在研究基于首帧空间提示的视觉轨迹预测问题。该数据集包含2841个抓放操作视频,每个视频约5秒时长并降采样至10fps,通过改进的通用操作接口采集,整合了GoPro鱼眼镜头视频与iPhone SLAM系统恢复的6自由度末端执行器轨迹数据。数据构建过程由九名专家完成,涵盖五个视觉相似叉子与九类目标容器的组合,并设计三个渐进式场景以评估模型分布内性能与跨场景泛化能力。该数据集主要应用于机器人操作策略学习领域,通过提供首帧物体与目标的空间标注、自我中心视觉观察和精确运动轨迹,解决在杂乱环境中基于稀疏空间意图生成时序运动规划的核心挑战。
提供机构:
密歇根州立大学; 英伟达研究院
创建时间:
2026-05-20
原始信息汇总
根据您提供的HTML内容,以下是该数据集详情页面的关键信息总结。
数据集概述
数据集名称:EgoSPT
所属项目:SP-VTP(Spatially Prompted Visual Trajectory Prediction)
发布时间:2026年(预印本)
发布机构:密歇根州立大学 & NVIDIA Research
核心任务
SP-VTP(空间提示的视觉轨迹预测):给定第一帧图像中的物体和目标空间提示(bounding box),模型从流式自我中心观察中预测未来的相对末端执行器轨迹。
数据集规模
- 总片段数:2,841 个自我中心操作片段
- 轨迹样本数:112,856 个
- 场景分割:3 个场景级划分(训练/验证/测试)
数据采集
- 采集设备:改进的 Universal Manipulation Interface (UMI)
- 数据内容:每个片段包含自我中心视频、初始帧中物体和目标的边界框标注、恢复的末端执行器姿态
- 验证协议:场景感知验证协议,将相关场景单元排除在训练集外,评估跨场景泛化能力
标注与处理
- 标注方式:轻量级标注流程,在第一帧中标注物体和目标边界框
- 提供工具:标注工具(记录两个边界框)和修改工具(支持人工检查和修正)
- 数据可视化:每个处理后的片段同步显示自我中心视频、恢复的姿态运动和夹爪宽度信号
使用说明
- 数据下载:页面提供数据下载链接(具体地址未在HTML中列出)
- 论文引用:提供 BibTeX 引用格式
- 代码:代码即将发布(链接标记为“coming soon”)
搜集汇总
数据集介绍
构建方式
EgoSPT数据集基于改进的通用操作界面(UMI)采集,集成了GoPro鱼眼相机与iPhone视觉惯性SLAM系统,由九名受训专家完成2,841段第一人称视角的抓取与放置视频录制。每段视频约5秒、30帧/秒,后处理下采样至10帧/秒。在首帧上标注操作物体与目标区域的边界框或点提示,并恢复三维末端执行器运动轨迹。数据覆盖五个视觉相似叉子与九个目标容器(三个杯子、碗和盘子各三个),构建成三个难度递增的场景:场景一为结构化布局,场景二为杂乱布局,场景三包含22个随机杂乱子场景,支持场景级泛化评估。
特点
EgoSPT的核心特点在于将静态空间提示与动态执行场景相结合。任务规格仅在第一帧通过点或边界框指定,但相机运动、末端执行器遮挡以及抓取后物体位置变化使执行过程实时演化。数据强调实例级区分,在存在同类别干扰物时要求策略保持目标身份识别。此外,同一物体-目标对在不同执行阶段需要不同运动模式,促使模型推断任务进度。数据集提供场景感知划分,避免随机分割带来的高估,并包含多维度评估指标(末端位移误差、轨迹位置误差、旋转误差和夹爪宽度误差)。
使用方法
EgoSPT适用于空间提示驱动的视觉轨迹预测任务。使用时,模型输入首帧图像及物体/目标空间提示(边界框或点),结合当前帧观测与近期轨迹历史,预测未来16帧的相对末端执行器运动(包含平移、六维旋转和夹爪宽度)。数据集采用滑动窗口训练,提供约110K个轨迹预测样本。评估需在场景感知划分下进行,要求模型在未见过的场景配置中利用首帧提示推测轨迹,而非记忆熟悉布局。推荐使用如SPOT等结合视觉渲染与坐标提示的策略,并采用流匹配生成轨迹。
背景与挑战
背景概述
EgoSPT数据集由密歇根州立大学与英伟达研究院的研究人员于2025年创建,旨在探索面向第一人称视角操作任务的空间提示式视觉轨迹预测问题。在机器人操作领域,传统任务规范依赖于语言指令或任务标识,但在包含同类视觉相似物体的杂乱场景中,语言描述往往无法精确指定目标实例和放置区域。EgoSPT通过提供首帧物体与目标的空间标注(如边界框或关键点),将操作目标从语言形式转化为直观的空间指示。数据集包含2841段拾放视频,涵盖五种视觉相似的叉子和九种目标容器(碗、杯、碟),并设计了三类难度递进的场景,系统评估模型在结构化布局、杂乱布局及多样杂乱子场景上的泛化能力。该数据集的核心研究问题在于,如何利用静态的首帧空间提示,从动态的第一人称视频流中预测连续的末端执行器轨迹,为机器人操作提供轻量级、低歧义的任务规范接口。EgoSPT的提出填补了空间提示与视觉轨迹预测交叉领域的空白,为后续研究建立了标准化的评估协议和基准。
当前挑战
EgoSPT所解决的核心领域挑战在于,如何在第一人称操作视频中仅凭首帧静态空间提示,预测后续动态变化的末端执行器轨迹。具体而言,任务规范是静态的(物体和目标仅在首帧被标注),而执行过程是动态的:相机随操作者移动,末端执行器会遮挡场景,物体在抓取后位置发生变化,且同类物体在杂乱环境中需要持续的实例级区分。此外,同一物体-目标对在不同执行阶段可能对应完全不同的运动模式,要求模型不仅能理解当前做什么,还需推断相关实体当前所在位置以及任务进展程度。在数据集构建过程中,挑战同样显著:采用改良版通用操作接口(UMI)设备,需精确同步iPhone的六自由度SLAM轨迹与GoPro的广角第一人称视频,并对九名训练有素的操作员的标注结果进行严格的质检与修正,确保首帧物体和目标边界框的精度。数据集还引入了场景感知的数据划分策略,将所有来自同一场景的片段归入同一数据子集,防止模型因记忆熟悉布局而高估跨场景泛化能力。
常用场景
经典使用场景
EgoSPT数据集专为空间提示的视觉轨迹预测(SP-VTP)任务设计,其核心应用场景是在第一人称视角的机器人操作视频中,根据首帧给定的物体和目标空间提示(如边界框或点),预测未来末端执行器的三维运动轨迹。该数据集包含2,841段拾放操作视频,覆盖结构化布局、杂乱布局和多样化子场景,提供了首帧标注、三维轨迹恢复和场景感知的数据划分,为评估模型在跨场景条件下的轨迹预测能力提供了标准化测试平台。
解决学术问题
EgoSPT数据集解决了传统语言指令在杂乱场景中因目标视觉相似而导致的歧义问题,首次将空间提示引入自我中心操作轨迹预测领域。它系统性地应对了静态任务规范与动态执行环境之间的矛盾,包括相机运动、末端遮挡、物体重定位以及同类干扰物下的实例级区分等挑战。通过提供场景感知的数据划分和多维度评估指标,该数据集推动了视觉中心化操作任务规范的学术研究,为探索空间提示作为轻量级、低歧义任务接口的有效性奠定了数据基础。
衍生相关工作
基于EgoSPT数据集,研究者提出了SPOT(Spatially Prompted Object-Target Policy)模型,该模型融合视觉渲染提示和坐标提示,结合冻结的DINOv2视觉编码器和流匹配轨迹生成头,实现了空间提示条件下的轨迹预测。该工作推动了后续研究,包括探索不同视觉基础模型(如SigLIP、EVA2)对轨迹预测的影响、分析提示形式(点、框、视觉渲染)的效果差异,以及研究历史轨迹长度对预测精度的影响。这些衍生工作共同构建了空间提示轨迹预测的研究框架和评测基准。
以上内容由遇见数据集搜集并总结生成


