AlekseyCalvin/Formal_Poetry_Periodized
收藏Hugging Face2026-04-10 更新2026-04-12 收录
下载链接:
https://hf-mirror.com/datasets/AlekseyCalvin/Formal_Poetry_Periodized
下载链接
链接失效反馈官方服务:
资源简介:
---
license: gpl-3.0
tags:
- poetry
- rhyme
- NLP
- Text
- English
- pairs
- corpus
---
The selection of English-language poems used in the dataset/research linked below (and initially drawn from the Chadwyck-Healey corpus). <br>
[Link to the full source data](https://dataverse.harvard.edu/dataset.xhtml?persistentId=doi:10.7910/DVN/BEQAYG)
##### SOURCE:
```
Dataset for "Generative Aesthetics: On the formal stuckness of AI verse"
(Journal of Cultural Analytics_, vol. 10, no. 3, Sept. 2025)
https://culturalanalytics.org/article/id/1036/
https://doi.org/10.7910/DVN/BEQAYG
```
许可证:GPL-3.0
标签:
- 诗歌
- 韵律
- 自然语言处理(Natural Language Processing)
- 文本
- 英语
- 语对
- 语料库
本数据集及下述关联研究中所使用的英文诗歌选集,最初源自Chadwyck-Healey语料库。
[完整源数据链接](https://dataverse.harvard.edu/dataset.xhtml?persistentId=doi:10.7910/DVN/BEQAYG)
##### 来源:
本数据集为论文《生成美学:论AI诗歌的形式僵化》(Generative Aesthetics: On the formal stuckness of AI verse)的配套数据,该论文发表于《文化分析期刊》(Journal of Cultural Analytics)第10卷第3期,2025年9月。
相关链接:https://culturalanalytics.org/article/id/1036/
DOI: 10.7910/DVN/BEQAYG
提供机构:
AlekseyCalvin
搜集汇总
数据集介绍
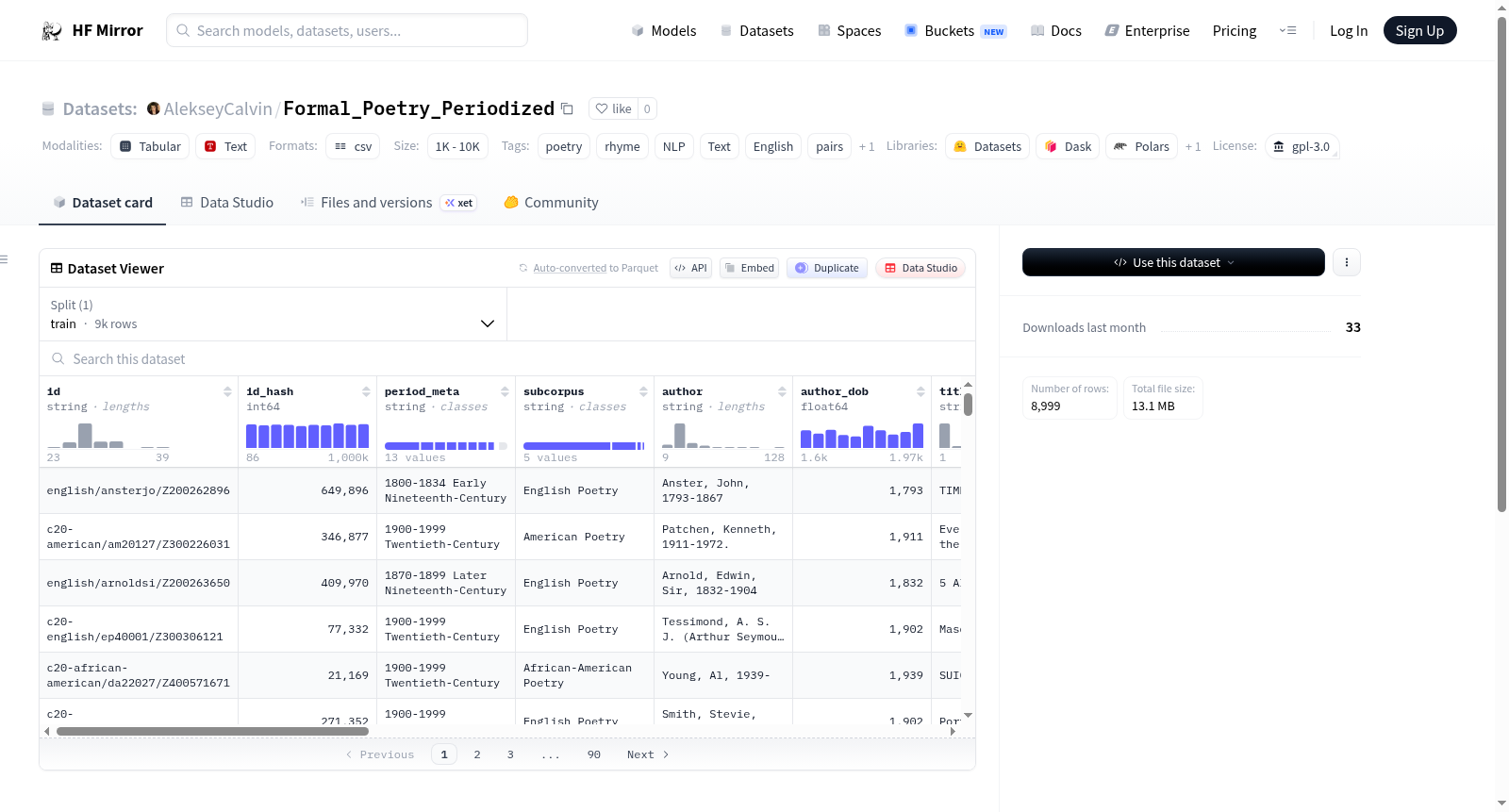
构建方式
该数据集源自《Generative Aesthetics: On the formal stuckness of AI verse》研究项目中所使用的英语诗歌语料,其原始素材取自Chadwyck-Healey语料库,一个广泛收录英语诗歌经典作品的权威资源库。构建过程中,研究者对原始诗歌进行了系统性的筛选与整理,依据诗歌的创作时期进行分期归类,从而形成了具备时间维度的结构化诗歌语料集。数据集以配对形式呈现,旨在服务于诗歌韵律与形式特征的分析,为自然语言处理领域中的诗歌生成与风格迁移任务提供基础数据支撑。
特点
该数据集的核心特色在于其鲜明的历史分期属性,将英语诗歌按创作年代进行划分,有助于研究人员捕捉不同历史时期的诗歌风格演变与韵律结构差异。数据以句子对(pairs)的形式组织,便于直接用于文本匹配、风格对比及韵律模式学习等任务。作为专门针对诗歌形式与格律研究的高质量语料,它不仅具备丰富的文本内容,更包含了隐性的韵律信息,为AI诗歌生成的形式美学探索提供了宝贵的训练与评估基准。
使用方法
用户可通过Hugging Face平台直接加载该数据集,利用其提供的句子对结构进行多种自然语言处理任务。典型的使用路径包括将其作为训练语料,训练面向诗歌风格迁移的序列到序列模型;或通过分析不同时期的诗歌配对,研究英语诗歌格律与韵律的历时性演变规律。此外,该数据集亦适用于诗歌生成模型的评估环节,通过对比生成诗歌与历史诗歌在形式特征上的吻合度,量化模型的韵律掌握水平。
背景与挑战
背景概述
该数据集名为Formal_Poetry_Periodized,创建于2025年,由哈佛大学相关研究人员基于Chadwyck-Healey语料库构建,核心研究问题聚焦于英语诗歌的形式特征及其在人工智能诗歌生成中的表现。该数据集收录了按历史时期划分的英语诗歌,旨在为计算诗学与自然语言处理领域提供结构化的韵律训练资源。其发布依托于《Generative Aesthetics: On the formal stuckness of AI verse》一文,该研究探讨了AI生成诗歌在形式上的僵化问题,对理解机器创作中的文学形式局限具有重要学术影响力。数据集的推出,为评估与改进AI诗歌的形式多样性提供了基准,推动了人机协作在文学创新中的前沿探索。
当前挑战
当前数据集面临双重挑战。首先,在领域问题层面,诗歌形式如韵律、节奏等难以被模型精准捕捉,传统NLP方法对诗歌形式特征的建模不足,导致AI生成诗歌常陷入形式死板或语义断裂的困境,亟需更细致的韵律标注与多模态学习方法。其次,在构建过程中,从Chadwyck-Healey语料库中筛选并按时期划分诗歌时,需确保时间分期的科学性和诗歌代表性,避免数据偏差;同时,跨时期的风格演变增加了标注一致性难度,而版权限制也影响了数据集的公开可及性与扩展潜力。
常用场景
经典使用场景
在计算诗学与数字人文研究的交汇处,Formal_Poetry_Periodized数据集为英语诗歌的形式特征分析提供了珍贵的结构化资源。该数据集精选自Chadwyck-Healey语料库,按历史时期对诗歌进行划分,使研究者能够系统考察韵律模式、格律结构及押韵手法等诗歌形式要素的演变轨迹。经典应用场景涵盖基于时间维度的诗体形态计量分析、诗歌韵律自动分类器的训练与评估,以及跨时期的诗歌形式风格迁移研究,为理解英语诗歌的文学形式变迁提供了可量化的数据基础。
实际应用
在实际应用层面,该数据集为人工智能诗歌生成系统的形式可控性改进提供了关键训练素材。研究者利用其按时期划分的特性,开发能够模仿特定历史阶段诗歌韵律风格的生成模型,例如维多利亚时期的严谨格律或自由诗体的非传统结构。此外,该数据集还支撑了诗歌自动评鉴系统的开发,帮助文学教育平台实现学生对经典诗作形式辨识能力的智能训练,以及在数字图书馆中构建基于时代风格的诗歌检索与推荐功能。
衍生相关工作
围绕该数据集衍生的经典工作包括基于时期标注的诗歌韵律演化追踪研究,其中学者通过统计对比不同年代的押韵密度与格律复杂性,揭示了英语诗歌形式从规范到解构的宏观趋势。另一项代表性工作是开发面向历史诗歌的韵律模式无监督聚类算法,成功识别出隐藏的核心形式变迁节点。此外,该数据集还被用于验证深度学习模型在捕捉诗歌跨世纪形式DNA时的能力边界,促成了文化分析学中生成式美学框架的理论构建,将数据驱动的方法论正式引入传统诗学研究领域。
以上内容由遇见数据集搜集并总结生成


