TigerResearch/tigerbot-law-plugin
收藏Hugging Face2023-06-01 更新2024-03-04 收录
下载链接:
https://hf-mirror.com/datasets/TigerResearch/tigerbot-law-plugin
下载链接
链接失效反馈资源简介:
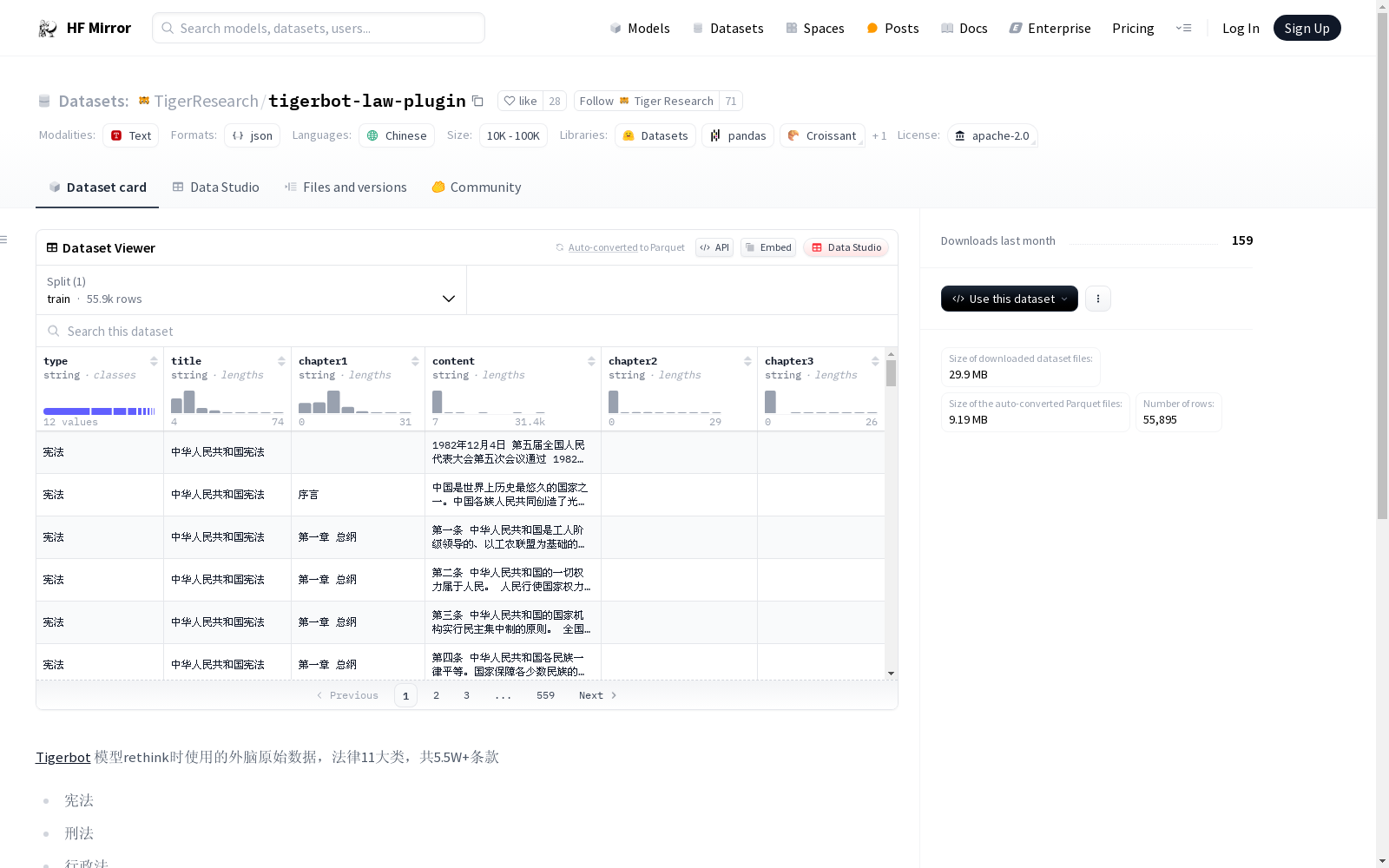
Tigerbot模型在rethink时使用的外脑原始数据,涉及法律11大类,共5.5W+条款。这些法律类别包括宪法、刑法、行政法、司法解释、民法商法、民法典、行政法规、社会法、部门规章、经济法、诉讼与非诉讼程序法。
The raw external auxiliary data used by the Tigerbot model during its rethink process covers 11 major categories of law, totaling over 55,000 clauses. These legal categories include Constitution, Criminal Law, Administrative Law, Judicial Interpretations, Civil and Commercial Law, Civil Code, Administrative Regulations, Social Law, Departmental Rules, Economic Law, and Procedural Law for Litigation and Non-litigation.
提供机构:
TigerResearch
原始信息汇总
数据集概述
数据集名称
- TigerResearch/tigerbot-law-plugin
数据集内容
- 包含法律领域的11大类条款,总计超过5.5万条。
- 具体分类包括:
- 宪法
- 刑法
- 行政法
- 司法解释
- 民法商法
- 民法典
- 行政法规
- 社会法
- 部门规章
- 经济法
- 诉讼与非诉讼程序法
数据集使用许可
- Apache-2.0
数据集语言
- 中文
搜集汇总
数据集介绍
构建方式
该数据集的构建基于我国现行的法律体系,涵盖了宪法、刑法、行政法等11大类,总计收录了5.5万以上的法律条款。这些数据是从法律文本中提取出来的,经过分类整理,形成了结构化数据,为法律领域的研究和应用提供了丰富的信息资源。
使用方法
使用该数据集非常简单,首先需要安装datasets库,然后通过调用load_dataset函数,并传入数据集名称即可加载。加载后的数据集可以直接用于法律文本的分析、模型训练等任务,为法律领域的人工智能研究提供了便捷的数据支持。
背景与挑战
背景概述
在法律文本智能化处理领域,TigerResearch团队致力于通过先进的人工智能技术,提升法律信息检索与解析的效率。Tigerbot法律插件数据集,创建于近年,是由TigerResearch团队精心整理的原始数据集。该数据集涵盖了我国法律体系的11大类,包括宪法、刑法、行政法等,共计5.5万条以上的法律条款,为法律文本的智能化研究提供了丰富而全面的文本资源。该数据集的构建,不仅体现了团队在法律信息化领域的深耕细作,也为相关研究提供了强有力的数据支撑,对推动法律人工智能发展产生了积极影响。
当前挑战
尽管Tigerbot法律插件数据集为法律文本分析提供了宝贵的资源,但在实际应用中仍面临诸多挑战。首先,法律文本的专业性和复杂性使得数据标注和处理的准确性至关重要,如何确保数据质量成为一大挑战。其次,数据集在构建过程中,需要克服法律法规的获取限制和隐私保护等问题。此外,面对不断更新的法律法规,数据集的时效性和动态更新也是亟需解决的问题。这些挑战对于提升数据集的实际应用价值提出了更高的要求。
常用场景
经典使用场景
在法学的知识图谱构建与智能问答系统中,TigerResearch/tigerbot-law-plugin数据集提供了不可或缺的原始素材。该数据集涵盖了法律领域的11大类,包括宪法、刑法、行政法等,总计超过五万五千条法律条款。其经典使用场景在于,通过深度学习模型对数据集进行训练,进而实现对法律问题的自动化解答,极大地提升了法律咨询的效率与准确性。
解决学术问题
该数据集解决了学术研究中关于法律文本处理与分析的核心问题。通过这一数据集,研究者能够对法律语言进行深入的挖掘与分析,探索法律文本的结构与语义特征,为法律信息检索、法律文本自动摘要以及法律知识图谱的构建提供了坚实的基础。这对于提高法律研究的自动化水平与智能化程度具有重要的学术意义和影响。
实际应用
在实际应用中,TigerResearch/tigerbot-law-plugin数据集被广泛运用于智能法律助手和法律信息平台的开发。这些应用能够为法律专业人士提供快速准确的法律信息查询服务,同时为公众提供便捷的法律咨询服务,有效地推动了法律服务行业的数字化转型。
数据集最近研究
最新研究方向
在法律文本处理领域,基于TigerResearch/tigerbot-law-plugin数据集的研究方兴未艾。该数据集涵盖了法律11大类,共5.5万条款,为自然语言处理技术在法律领域的应用提供了坚实基础。近期研究主要聚焦于深度学习模型对法律文本的自动分类、信息抽取和智能问答等前沿方向,旨在提高法律服务的效率和准确性。此外,该数据集还促进了法律文本语义理解的研究,助力于构建更加智能化的法律辅助系统,对法律信息化建设具有深远影响。
以上内容由遇见数据集搜集并总结生成


