THINKEDIT-140k
收藏arXiv2025-12-06 更新2025-12-09 收录
下载链接:
https://appletea233.github.io/think-while-edit
下载链接
链接失效反馈官方服务:
资源简介:
THINKEDIT-140k是由美团、港中文MMLab等机构联合构建的大规模多轮指令精修数据集,旨在提升图像编辑模型的指令遵循能力。该数据集包含14万条高质量数据样本,涵盖源图像、多样化编辑请求及多轮推理轨迹,通过自动化流水线整合GPT-4.1专家演示生成。其核心价值在于为迭代式图像编辑提供统一的监督信号,支持强化学习训练,可广泛应用于数字内容创作、虚拟形象设计等需要精细化视觉修改的领域。
THINKEDIT-140k is a large-scale multi-turn instruction refinement dataset jointly constructed by Meituan, CUHK MMLab and other institutions, aiming to enhance the instruction-following capability of image editing models. This dataset contains 140,000 high-quality data samples, covering source images, diverse editing requests and multi-turn reasoning trajectories, and is generated through an automated pipeline that integrates expert demonstrations from GPT-4.1. Its core value lies in providing a unified supervision signal for iterative image editing, supporting reinforcement learning training, and can be widely applied in fields requiring fine-grained visual modification such as digital content creation and virtual avatar design.
提供机构:
美团, 香港中文大学MM实验室, 清华大学, 北京航空航天大学
创建时间:
2025-12-06
搜集汇总
数据集介绍
构建方式
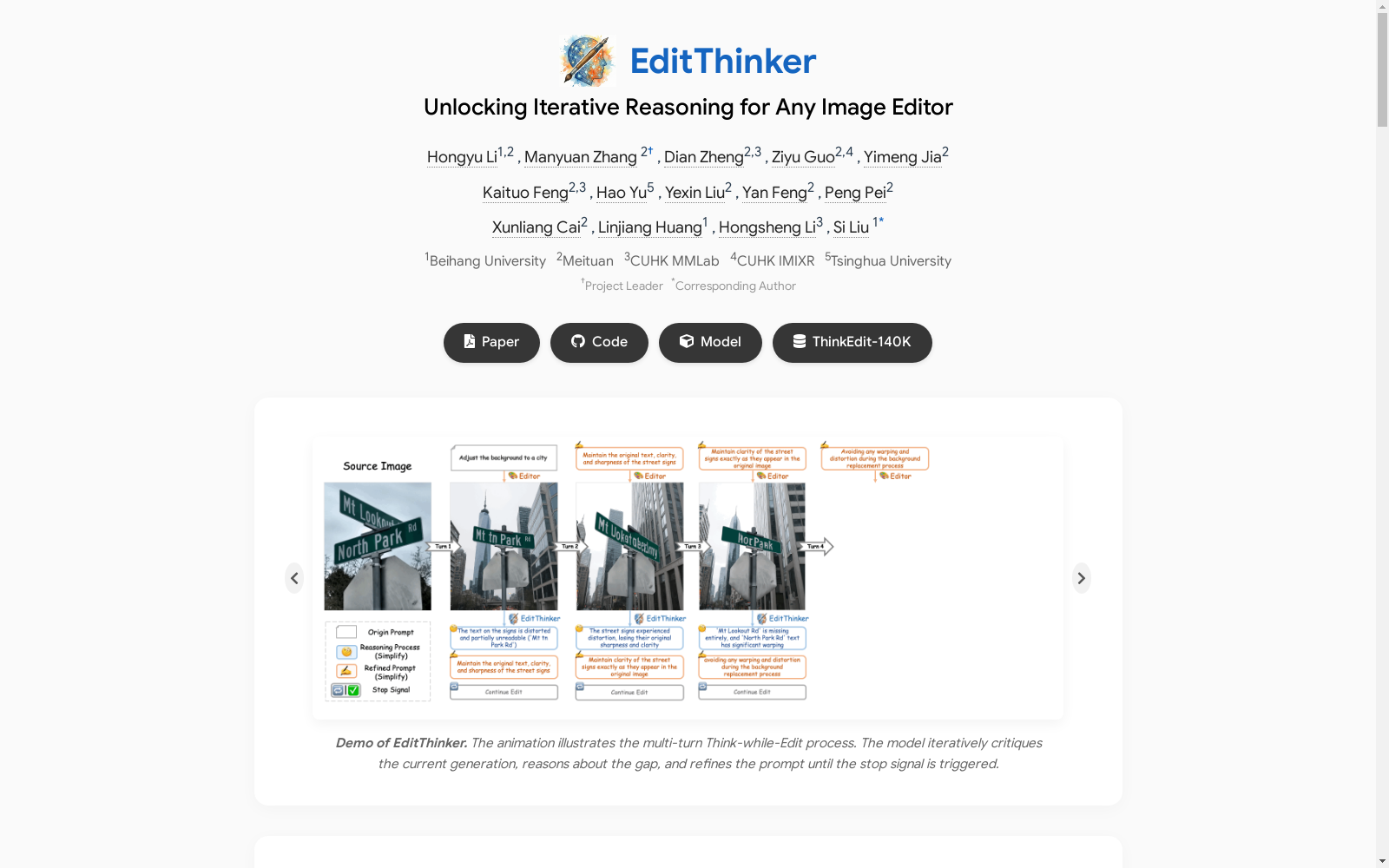
在指令引导的图像编辑领域,为了克服单轮编辑模型在指令遵循能力上的固有随机性与缺乏深思的局限,THINKEDIT-140k数据集通过一个自动化的多轮指令迭代框架构建而成。该构建流程模拟了人类“边思考边编辑”的认知循环,首先利用GPT-4.1作为专家思考者,与多种前沿图像编辑模型协同工作,对原始图像和编辑指令进行多轮迭代。在每一轮中,专家评估当前编辑结果,生成包含推理过程和细化指令的轨迹,并决定是否终止迭代。随后,通过轨迹过滤机制,仅保留那些后续编辑轮次得分不低于初始轮次的轨迹,并截取至得分最高的步骤,确保数据质量。最后,经过步骤级过滤与任务、得分分布的平衡处理,形成了包含14万高质量样本的监督微调数据集,以及一个专门用于强化学习的高波动性轨迹子集。
特点
THINKEDIT-140k的核心特点在于其深度嵌入了迭代推理的结构化信息。数据集不仅提供了源图像、原始指令和编辑结果,更重要的是包含了由专家模型生成的多轮“批判-细化”循环的完整轨迹,其中涵盖了详细的推理过程、指令改进的演变路径以及每一步的语义与质量评分。这种结构使得数据集能够为模型训练提供丰富的因果信号,引导模型学习如何诊断编辑失败的原因,并生成更具针对性的改进指令。此外,数据集覆盖了多样化的编辑任务类型,如对象替换、风格转换、背景调整等,并确保了不同难度与质量层级的样本均衡,为训练具备通用迭代推理能力的多模态大语言模型奠定了坚实基础。
使用方法
该数据集主要用于训练和评估具备迭代推理能力的图像编辑辅助模型,例如论文中提出的EditThinker。在使用时,数据集被划分为监督微调与强化学习两个部分。监督微调部分直接利用数据集中专家生成的(输入,输出)配对样本,训练模型掌握批判性评估、结构化推理与指令细化的基本能力。强化学习部分则利用数据集中那些编辑得分波动较大的轨迹,通过将模型生成的细化指令输入到实际编辑器中执行,并根据执行结果与专家评分的差异来设计奖励函数,从而对齐模型的“思考”与“执行”过程,优化其指令改进策略。最终,训练完成的模型可以作为一个通用的“思考者”模块,与任何现有的图像编辑器结合,通过多轮迭代显著提升其指令遵循的准确性与编辑结果的质量。
背景与挑战
背景概述
指令驱动的图像编辑作为多模态人工智能领域的前沿方向,旨在通过自然语言指令精确操控图像内容,其应用涵盖数字内容创作、虚拟世界仿真等广泛场景。THINKEDIT-140k数据集由美团、北京航空航天大学及香港中文大学多媒体实验室等机构的研究团队于2025年构建,核心目标在于解决现有图像编辑模型在单轮交互中因缺乏深思熟虑而导致的指令跟随能力不足问题。该数据集通过模拟人类‘批判-反思-编辑’的认知循环,为训练具备迭代推理能力的多模态大语言模型提供了大规模、高质量的监督信号,显著推动了图像编辑系统从被动执行向主动思考的范式转变。
当前挑战
THINKEDIT-140k数据集旨在应对指令跟随图像编辑任务中的核心挑战,即模型需在单次生成中同时完成指令理解、视觉规划与内容合成,这常导致属性遗漏、语义偏差及长程一致性破坏等问题。其构建过程亦面临多重挑战:首先,自动化生成高质量的多轮迭代轨迹需协调图像编辑模型与专家评判器,确保指令迭代的逻辑连贯性与视觉合理性;其次,数据过滤与平衡要求设计精细的轨迹评分与截断机制,以筛选出体现真实改进过程的样本,并需在任务类型与质量分布上进行均衡,避免模型过拟合于特定编辑模式。
常用场景
经典使用场景
在指令引导的图像编辑领域,THINKEDIT-140k数据集为多轮迭代推理范式提供了核心训练支撑。该数据集通过模拟人类“批判-反思-编辑”的认知循环,构建了包含源图像、原始指令、中间编辑结果、专家推理轨迹及精炼指令的完整数据链。其经典应用场景在于训练多模态大语言模型(MLLM)作为“思考者”,使其能够对任意图像编辑器的输出进行自动化评估、缺陷诊断与指令优化,从而将单次编辑扩展为可自我修正的迭代过程。
解决学术问题
该数据集旨在解决指令式图像编辑中长期存在的单次成功率瓶颈问题。传统方法受限于模型固有的随机性与缺乏深思熟虑的缺陷,难以在单轮编辑中同时满足指令遵循、细节保持与视觉一致性的多重约束。THINKEDIT-140k通过提供大规模、高质量的多轮推理轨迹,使得模型能够学习如何识别编辑失败的具体原因(如属性缺失、空间错位、风格不一致),并生成具有针对性的指令改进方案,从而显著提升了编辑系统在复杂场景下的鲁棒性与精确性。
衍生相关工作
基于THINKEDIT-140k数据集所倡导的“边思考边编辑”范式,学术界衍生出一系列探索迭代推理与编辑协同的经典工作。例如,EditThinker模型利用该数据集进行监督微调与强化学习训练,实现了对多种底层编辑器(如Qwen-Image-Edit、FLUX-Kontext)的通用性能提升。后续研究进一步将该范式扩展至视频编辑、3D场景生成等跨模态任务,并催生了专注于编辑质量评估的专项奖励模型(如EditScore),推动了指令跟随能力从静态评估向动态交互优化的范式转变。
以上内容由遇见数据集搜集并总结生成


