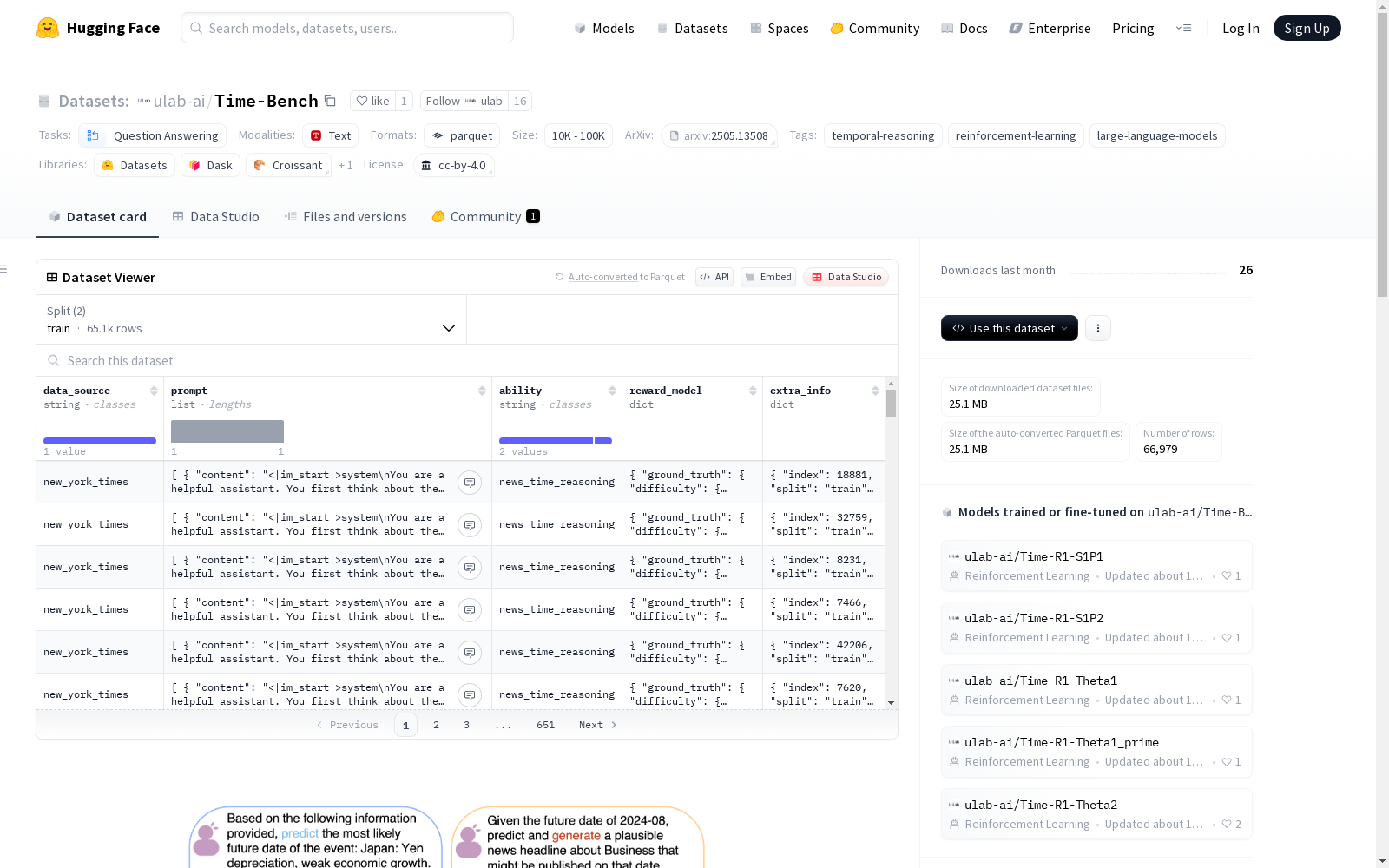
Time-Bench
收藏Hugging Face2025-05-24 更新2025-05-25 收录
下载链接:
https://huggingface.co/datasets/ulab-ai/Time-Bench
下载链接
链接失效反馈官方服务:
资源简介:
Time-Bench数据集是用于训练和评估Time-R1模型的数据集,包含三个阶段的文件:第一阶段是时间理解,包括时间推断、时间差估计、事件排序和时间实体掩码完成等任务;第二阶段是未来事件时间预测;第三阶段是创造性未来情景生成,使用现实世界新闻文章进行比较和分析。
The Time-Bench dataset is designed for training and evaluating the Time-R1 model. It includes files for three distinct phases: Phase 1 focuses on temporal understanding, encompassing tasks such as temporal inference, time difference estimation, event ordering, and temporal entity masking and completion; Phase 2 centers on future event temporal prediction; and Phase 3 involves creative future scenario generation, which uses real-world news articles for comparison and analysis.
创建时间:
2025-05-24
原始信息汇总
Time-Bench 数据集概述
基本信息
- 许可证: CC-BY-4.0
- 相关论文: Time-R1: Towards Comprehensive Temporal Reasoning in LLMs
- 任务类别: 问答
- 标签: 时序推理、强化学习、大语言模型
数据集文件
阶段1: 时序理解
train_inference_easy.parquet: 用于阶段1的初始训练,关注简单时序推理任务。train_comprehension_combined.parquet: 综合训练集,涵盖更广泛的时序理解任务,包括时间戳推断、时间差估计、事件排序和掩码时间实体补全。test_comprehension_combined.parquet: 验证集,用于评估各种时序理解任务的性能。
阶段2: 未来事件时间预测
train_prediction_combined.parquet: 阶段2的训练集,用于训练模型预测未来事件时间。test_prediction.parquet: 阶段2的验证集,用于评估模型预测未来事件时间的准确性。
阶段3: 创意未来场景生成
nyt_years/2024.jsonl: 包含2024年纽约时报文章,用于比较和分析生成的未来新闻。nyt_years/2025.jsonl: 包含2025年纽约时报文章,用途同上。
数据格式
.parquet文件: 包含与特定时序推理任务相关的列,如提示、真实答案和元数据。.jsonl文件: 包含JSON Lines格式的新闻文章。
引用
bibtex @article{liu2025time, title={Time-R1: Towards Comprehensive Temporal Reasoning in LLMs}, author={Liu, Zijia and Han, Peixuan and Yu, Haofei and Li, Haoru and You, Jiaxuan}, journal={arXiv preprint arXiv:2505.13508}, year={2025} }
搜集汇总
数据集介绍
构建方式
Time-Bench数据集采用分阶段构建策略,针对时间推理能力的不同维度进行系统化设计。其构建过程严格遵循Time-R1模型的课程学习框架,通过三个阶段逐步深化:基础时间理解阶段采用易于解析的Parquet格式文件,包含时间戳推断、时差估算等标注数据;未来事件预测阶段则整合了带有明确时间锚点的序列数据;创意场景生成阶段创新性地引入《纽约时报》2024-2025年的真实新闻档案作为基准参照。数据集通过自动化标注与专家验证相结合的方式,确保时间标注的精确性和逻辑一致性。
特点
该数据集最显著的特征是其层次化的任务架构设计,从基础时间概念理解到复杂未来事件推演形成完整能力谱系。数据内容涵盖时间实体识别、事件时序推理等七类核心任务,特别在跨文档时间推理方面提供丰富的标注维度。新闻档案部分采用原生JSONL格式保留完整的元数据,为时间敏感的文本生成任务提供真实世界参照。数据集通过标准化时间表达式(如ISO 8601)和事件因果链标注,支持细粒度的时间推理能力评估。
使用方法
使用该数据集时建议遵循其预设的三阶段流程:首先通过comprehension_combined文件训练基础时间解析能力,继而利用prediction_combined文件开发事件时间预测模型,最终结合NYT新闻档案进行生成质量评估。各阶段数据均采用列式存储的Parquet格式,可通过Pandas或PyArrow高效加载。对于创意生成任务,建议将2024-2025年的新闻数据作为生成结果的真实性校验基准,通过对比分析评估模型的时间一致性表现。具体实现细节可参考配套的Time-R1训练脚本和论文中的课程学习策略。
背景与挑战
背景概述
Time-Bench数据集由伊利诺伊大学厄巴纳-香槟分校的ULab研究团队于2025年构建,旨在推动大语言模型在时间推理领域的深入研究。该数据集作为Time-R1模型训练的核心资源,聚焦于时间理解、未来事件预测和创造性未来场景生成三大核心任务。通过整合时间戳推断、时间差计算、事件排序等多样化任务,该数据集填补了现有时间推理基准测试的空白,为评估模型在复杂时间逻辑处理能力方面提供了标准化工具。其创新性的三阶段课程学习框架,显著提升了模型对时间概念的层次化理解能力,对时序问答系统和预测性文本生成等应用具有重要指导价值。
当前挑战
Time-Bench数据集面临双重技术挑战:在领域问题层面,时间推理任务需处理模糊时间表达(如"下月初")的精确量化问题,解决跨时区事件的时间对齐难题,以及长周期事件链的因果关联建模。数据集构建过程中,研究人员需平衡人工标注的时序逻辑严谨性与自动生成数据的规模效益,确保时间表达式标注的颗粒度一致性,同时处理新闻语料中隐含时间信息的提取与标准化问题。多阶段任务设计还要求严格验证各阶段数据间的知识迁移有效性,避免模型出现阶段性的过拟合现象。
常用场景
经典使用场景
在时序推理与自然语言处理交叉领域,Time-Bench数据集通过分阶段训练框架为大型语言模型提供系统性评估基准。其经典应用场景体现在三阶段递进式训练中:从基础时间概念理解到未来事件时间预测,最终实现创造性未来场景生成。研究人员可借助该数据集验证模型在时间戳推断、事件排序等任务上的表现,特别适合评估大语言模型对复杂时间关系的建模能力。
解决学术问题
该数据集有效解决了时序推理领域三个关键学术问题:传统模型对隐式时间表达理解不足的问题通过时间实体补全任务得到改善;针对事件时序混乱的挑战设计了专门的事件排序评估模块;对未来事件预测缺乏可靠基准的现状,通过结合真实新闻数据构建了验证体系。这种结构化设计推动了时序推理研究从基础认知到高级预测的系统性突破。
衍生相关工作
围绕该数据集已衍生出多项创新研究,包括时序知识增强的预训练方法Time-LLM、基于强化学习的时间推理框架TempRL等。其分阶段训练范式被Adaptive Temporal Reasoning体系借鉴改进,而数据集构建方法论更启发了后续TemporalCompass等基准的创建。相关成果在ACL、EMNLP等顶会上形成时序推理研究的子领域。
以上内容由遇见数据集搜集并总结生成


