pilotgpt-test
收藏Hugging Face2026-01-30 更新2026-02-02 收录
下载链接:
https://huggingface.co/datasets/Trelis/pilotgpt-test
下载链接
链接失效反馈官方服务:
资源简介:
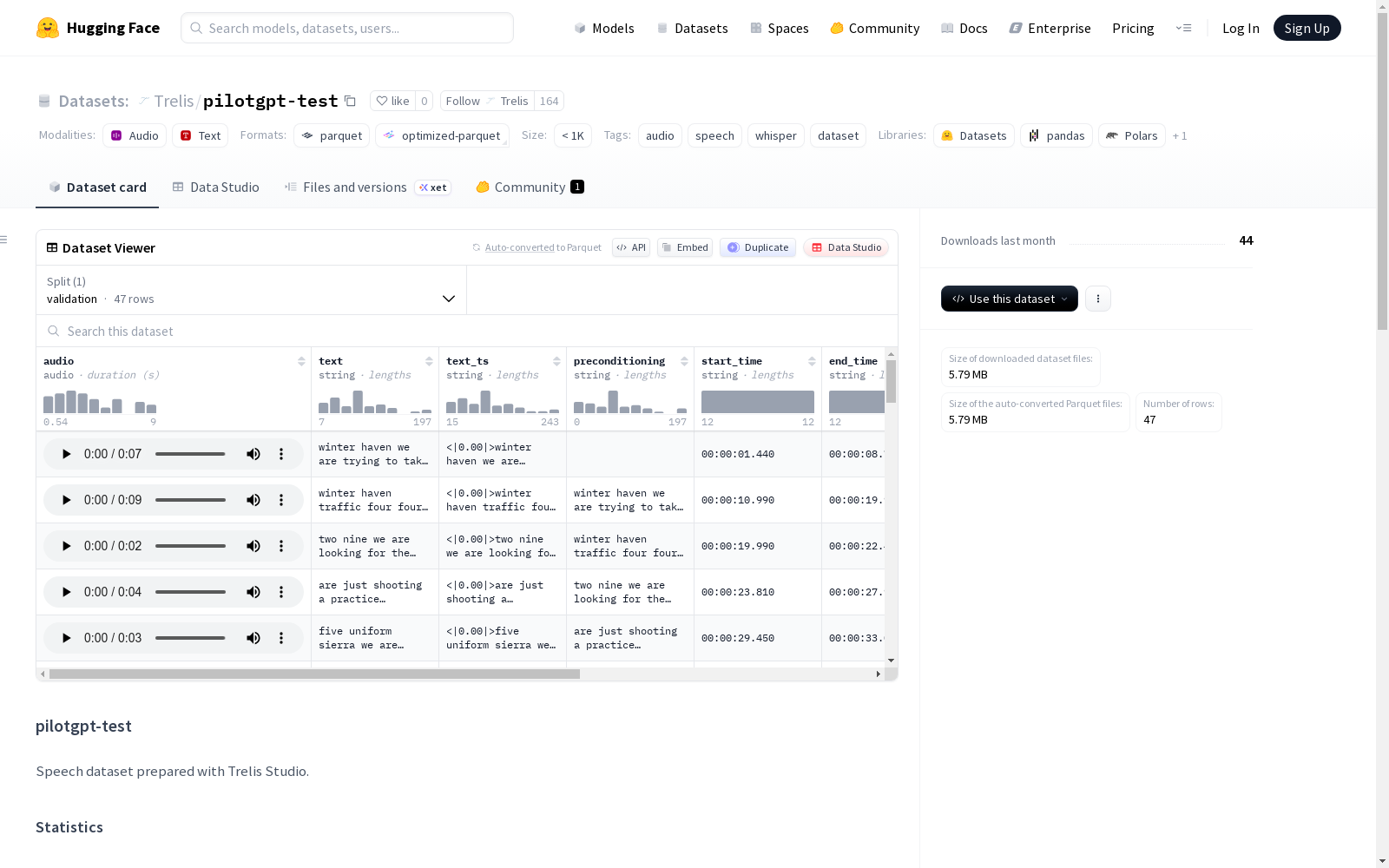
pilotgpt-test 是一个为语音相关任务准备的音频数据集,特别适用于训练如 Whisper 等模型。数据集包含 2 个源文件,22 个验证样本,总时长为 4.6 分钟。数据字段包括音频片段(16kHz,经过 VAD 处理去除静音)、纯文本转录、带有 Whisper 时间戳标记的转录、片段在原音频中的起止时间、语音持续时间、词级时间戳以及源文件名。音频片段经过 Silero VAD 处理,仅保留语音区域,时间戳相对于拼接后的语音音频。训练时建议采用两桶方法:50% 使用纯文本转录,50% 使用带时间戳标记的转录。
Pilotgpt-test is an audio dataset tailored for speech-related tasks, specifically intended for training models such as Whisper. The dataset comprises 2 source files and 22 validation samples, with a total duration of 4.6 minutes. Its data fields include audio clips (16kHz, with silences removed via VAD processing), raw text transcriptions, transcriptions with Whisper timestamps, the start and end timestamps of the clip within the original audio, speech duration, word-level timestamps, and source file names. All audio clips are processed using Silero VAD to retain only speech segments, and the timestamps are relative to the concatenated speech audio. For training, the two-bucket approach is recommended: 50% of the training data uses raw text transcriptions, while the other 50% uses transcriptions with timestamp annotations.
提供机构:
Trelis创建时间:
2026-01-30
搜集汇总
数据集介绍
构建方式
在语音处理领域,高质量数据集的构建对于模型训练至关重要。pilotgpt-test数据集通过Trelis Studio精心制备,其构建过程体现了严谨的工程化流程。原始音频文件首先经过Silero VAD(语音活动检测)处理,自动剥离静音部分,仅保留纯净的语音区域。随后,利用Whisper模型生成带有精确时间戳的文本转录,形成包含普通文本(text)和带时间戳文本(text_ts)的双版本标注。每个语音片段均记录了起始时间、结束时间、语音持续时间及词级时间戳,确保了数据的时间对齐精度与完整性。
特点
该数据集的核心特点在于其专为Whisper时间戳训练而设计的多模态标注结构。它不仅提供标准的语音-文本配对,更创新性地引入了包含Whisper时间戳令牌的转录文本,如“<|0.00|>Hello<|0.50|>”格式,为时间敏感型任务提供了直接支持。数据列设计全面,涵盖音频片段、纯文本转录、带时间戳转录、片段起止时间、语音时长、词级时间戳及源文件信息,形成了层次化的元数据体系。所有音频均统一为16kHz采样率,且经过VAD预处理,确保了与推理环境的一致性,提升了模型的实用性与泛化能力。
使用方法
在实际应用场景中,该数据集支持灵活的训练策略以优化模型性能。推荐采用双桶训练法:将50%的数据用于普通转录文本训练,另外50%用于带时间戳的转录文本训练,以此平衡模型的语言理解能力与时间定位精度。用户可通过Hugging Face的datasets库直接加载数据集,便捷地访问结构化数据。数据集的标准化格式使其能够无缝集成到现有的Whisper模型训练流程中,为语音识别、音频对齐及时间戳预测等任务提供高质量、即用型的训练资源。
背景与挑战
背景概述
在语音识别与音频处理领域,高质量标注数据集的构建对于推动自动语音识别(ASR)及时间戳预测等前沿技术的发展至关重要。pilotgpt-test数据集由Trelis机构利用其开发的Trelis Studio工具精心制备,专注于为Whisper等先进语音模型提供训练与验证资源。该数据集的核心研究问题在于提升语音识别系统在时间戳标注与语音活动检测(VAD)方面的精度与鲁棒性,通过提供包含精细时间信息的转录文本,支持模型学习语音与文本之间的时序对齐关系。自创建以来,该数据集为语音处理社区贡献了宝贵的基准数据,尤其在促进端到端语音识别模型的优化与评估方面展现出显著影响力。
当前挑战
pilotgpt-test数据集旨在应对语音识别领域中时间戳预测与语音活动检测的复杂挑战,具体包括模型在嘈杂环境下准确分割语音与非语音区域、以及实现单词级别的时间对齐精度。在构建过程中,数据集面临多重技术难题:首先,利用Silero VAD进行静音剥离时,需确保处理后的音频与推理环境行为一致,以避免训练与部署间的偏差;其次,生成包含Whisper时间戳标记的转录文本要求精确的时序标注,这对标注工具的可靠性与自动化流程提出了较高要求;此外,维持数据集的规模与多样性平衡也是一项挑战,当前版本仅包含有限样本与时长,可能限制其在广泛场景下的泛化能力。
常用场景
经典使用场景
在语音处理领域,pilotgpt-test数据集专为Whisper模型的训练与评估而设计,其核心应用场景在于支持语音识别与时间戳标注任务。该数据集通过Silero VAD技术剥离静音部分,保留纯语音片段,并提供了带时间戳的转录文本,使得模型能够学习语音内容与时间对齐的映射关系。这种设计使得数据集特别适用于训练端到端的语音识别系统,尤其是在需要精确时间标注的应用中,如音频字幕生成或语音分析工具的开发。
解决学术问题
该数据集主要解决了语音识别研究中时间戳预测的学术难题,通过提供带Whisper时间戳标记的转录文本,促进了模型在语音分段与内容对齐方面的性能提升。它支持两桶训练策略,平衡了纯文本转录与时间戳标注的数据分布,有助于模型在保持识别准确性的同时,增强时间定位能力。这一贡献推动了语音处理领域对细粒度时序建模的研究,为多模态音频分析提供了可靠的数据基础。
衍生相关工作
基于pilotgpt-test数据集,衍生了一系列经典研究工作,主要集中在Whisper模型的扩展与优化上。例如,研究者利用其时间戳标注特性,开发了改进的语音分段算法和端到端时序预测模型。这些工作进一步推动了语音识别技术在多语言环境、低资源场景下的应用,并为开源社区提供了可复现的实验基准,促进了语音处理领域的协作与创新。
以上内容由遇见数据集搜集并总结生成


