HiCUPID
收藏Hugging Face2025-05-28 更新2025-05-29 收录
下载链接:
https://huggingface.co/datasets/12kimih/HiCUPID
下载链接
链接失效反馈官方服务:
资源简介:
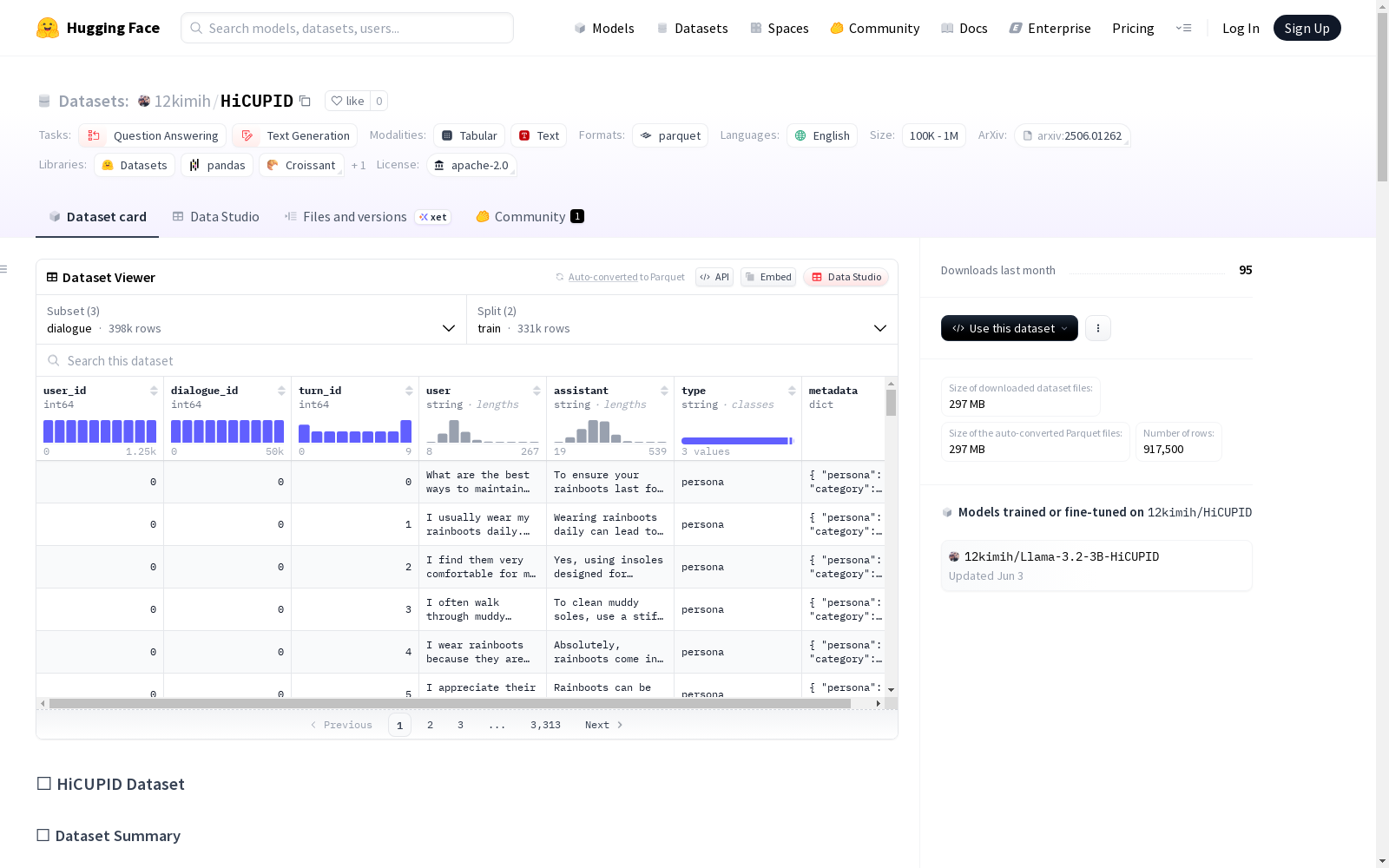
HiCUPID数据集是一个专门为训练和评估个性化AI助手而设计的大型语言模型(LLM)的数据集。它包括来自1500个独特用户的对话和问答对,这些数据被细分为个人资料对话、个人喜好对话、日程安排对话以及相应的问答对。数据集旨在帮助模型更好地适应不同用户的需求,提供个性化的对话体验。
The HiCUPID dataset is a large language model (LLM) dataset specifically curated for training and evaluating personalized AI assistants. It comprises dialogues and question-answer pairs sourced from 1500 unique users, with the data subdivided into profile-based dialogues, preference-based dialogues, schedule-related dialogues, and their corresponding question-answer pairs. The dataset aims to help models better adapt to the needs of different users and deliver personalized conversational experiences.
创建时间:
2025-05-28
搜集汇总
数据集介绍
构建方式
在个性化人工智能助手研究领域,HiCUPID数据集的构建采用了系统化的多维度数据采集策略。该数据集基于1500名虚拟用户的完整画像体系,通过结构化对话生成技术分别构建了人格特质、用户画像和日程安排三类对话场景。每名用户生成40组对话数据,其中人格对话25组采用多轮交互形式,画像与日程对话则采用单轮精简结构,最终形成包含331,250条对话记录的完整语料库。数据生成过程严格遵循预设的属性框架,确保用户元数据(如年龄、职业、情感倾向等)与对话内容的逻辑一致性。
使用方法
该数据集支持多层次的研究应用,主要面向个性化语言模型的训练与评估场景。在模型微调阶段,研究者可利用训练集进行监督微调(SFT)或直接偏好优化(DPO),通过人格对话与画像数据的联合学习提升模型个性化响应能力。评估阶段则需区分测试集1(已知用户新问题)与测试集2(新用户新问题)的不同场景,分别检验模型的适应性学习与零样本泛化性能。数据集配套的自动化评估模型基于Llama-3.2架构,可通过答案对比分析实现与人类偏好对齐的量化评估,具体操作流程详见项目GitHub仓库的完整代码实现。
背景与挑战
背景概述
在人工智能对话系统的发展历程中,个性化交互能力一直是提升用户体验的核心研究方向。HiCUPID数据集由Jisoo Mok等研究人员于2025年创建,旨在解决现有开源对话数据缺乏个性化适配的局限性。该数据集通过构建包含1,500名虚拟用户的对话与问答对,系统性地整合了人物设定、用户画像和日程安排等多维度个性化信息,为训练面向个性化助理场景的大语言模型提供了标准化基准。其创新性在于首次实现了从单一信息到复合信息的结构化个性特征建模,推动了对话系统从通用响应向个性化服务的范式转变。
当前挑战
个性化对话建模面临的核心挑战在于如何平衡用户隐私保护与个性特征表达的完整性。HiCUPID构建过程中需解决多源信息融合的复杂性:既要确保人物设定、社会属性与动态日程的逻辑一致性,又要避免生成式数据可能引入的语义偏差。在技术层面,该数据集针对个性化问答任务设计了三重评估机制,要求模型具备从稀疏对话历史中提取关键属性的能力。数据构造阶段还面临人工标注成本与自动化扩展之间的权衡,需要通过层次化元数据结构实现个性特征的标准化表征。
常用场景
经典使用场景
在个性化人工智能助手研究领域,HiCUPID数据集通过结构化对话和问答对的形式,为大语言模型的训练与评估提供了标准化框架。该数据集包含用户画像、个人资料和日程安排三类对话场景,每个场景配备不同轮次的交互数据,能够模拟真实环境中用户与助手的多轮对话过程。研究人员通常利用其对话子集进行监督微调,通过用户专属的元数据构建个性化响应模式,从而提升模型对用户特征的记忆与适应能力。
解决学术问题
该数据集有效解决了开放领域对话系统中个性化信息缺失的学术难题。通过提供包含用户画像、人口统计属性和行为模式的结构化元数据,它使模型能够学习如何将静态用户特征动态融入对话生成。这种设计突破了传统对话数据集仅关注通用语义匹配的局限,为研究个性化表征学习、长程上下文建模以及隐私保护下的用户建模提供了实验基础,推动了人机交互领域向更自然、更贴近用户需求的方向发展。
实际应用
在实际应用层面,HiCUPID为开发智能客服、个性化推荐系统和日程管理助手等场景提供了数据支撑。企业可利用其多维度用户画像训练专属助手,实现基于用户职业、性格偏好的服务定制;医疗健康领域可借鉴其隐私保护机制构建患者随访系统。数据集中的日程对话模块尤其适用于智能日历应用的开发,通过理解用户的时间安排习惯自动生成提醒与建议,显著提升生活效率类应用的智能化水平。
数据集最近研究
最新研究方向
在个性化人工智能助手领域,HiCUPID数据集正推动大语言模型从通用对话向深度个性化服务转型。该数据集通过结构化的人物画像、用户档案和日程信息,为模型提供了多维度的个性化学习基础。前沿研究聚焦于基于该数据集的评估模型蒸馏技术,利用GPT-4o生成的高质量标注训练轻量化评估模型,显著提升了个性化响应与人类偏好的对齐度。当前热点探索方向包括跨场景用户画像迁移、动态个性化策略优化以及隐私保护下的个性化建模,这些研究对构建可信赖的个性化AI助手具有重要实践意义。
以上内容由遇见数据集搜集并总结生成


