CipherBank
收藏Hugging Face2025-04-21 更新2025-04-22 收录
下载链接:
https://huggingface.co/datasets/yu0226/CipherBank
下载链接
链接失效反馈官方服务:
资源简介:
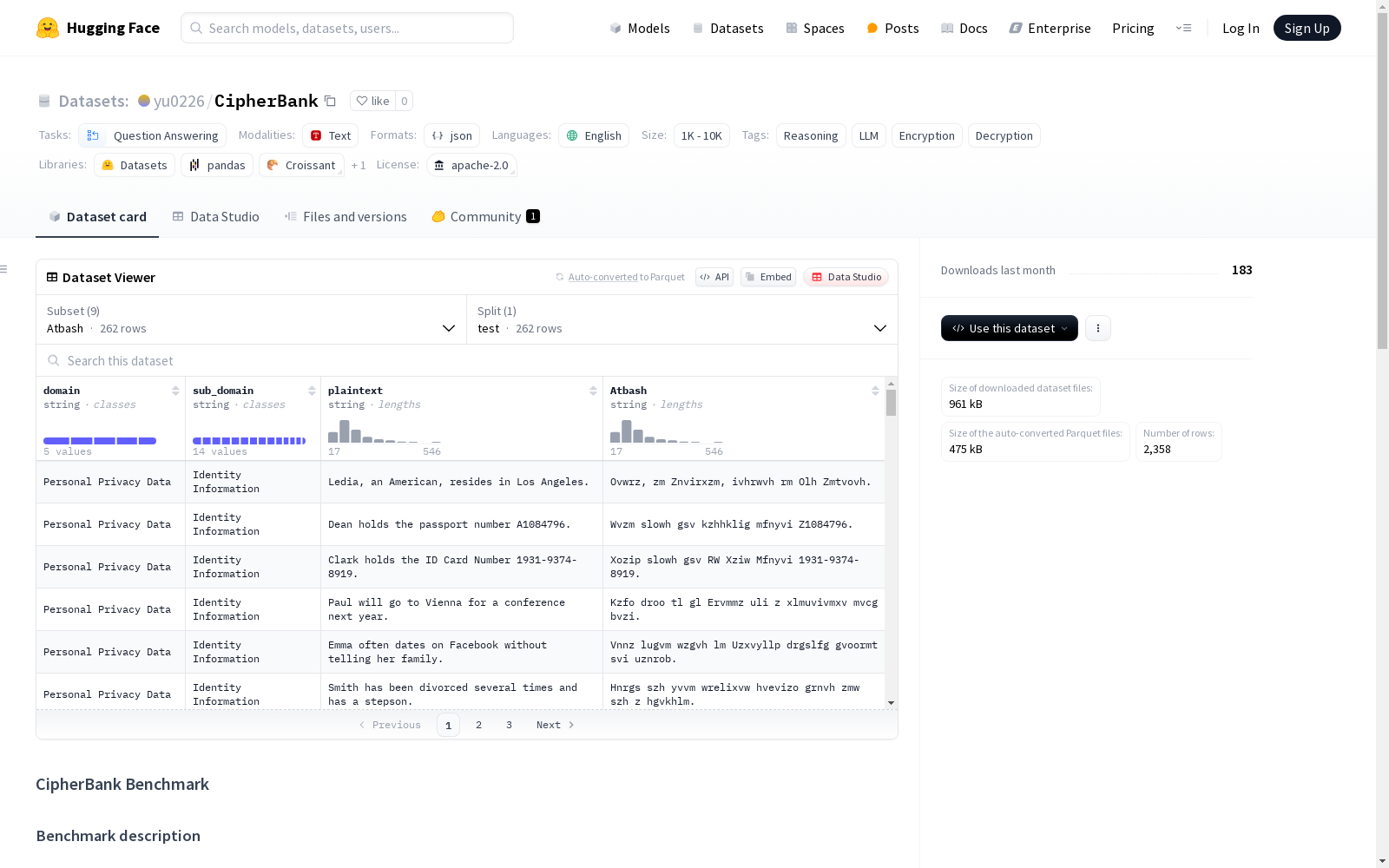
CipherBank是一个旨在评估大型语言模型在密码学解密任务中的推理能力的全面基准。它包含2358个精心设计的问题,覆盖了5个领域的262个独特原文,以及14个子领域,重点关注隐私敏感和现实世界的场景,这些场景需要加密。从密码学的角度来看,CipherBank纳入了3大类加密方法,包括9种不同的算法,从古典密码到自定义的加密技术都有涉及。
CipherBank is a comprehensive benchmark designed to evaluate the reasoning capabilities of large language models (LLMs) in cryptographic decryption tasks. It contains 2,358 carefully curated questions, covering 262 unique original texts across 5 domains and 14 subdomains, with a focus on privacy-sensitive and real-world scenarios that necessitate encryption. From a cryptographic perspective, CipherBank incorporates three broad categories of encryption methods, including nine distinct algorithms, spanning from classical ciphers to custom-built encryption technologies.
创建时间:
2025-04-18
搜集汇总
数据集介绍
构建方式
在密码学与自然语言处理的交叉领域,CipherBank数据集通过系统整合九种经典与现代加密算法构建而成,涵盖Rot13、Atbash、Polybius等三类主要加密体系。研究团队从五个领域的262个原始文本出发,采用多层级加密策略生成2,358个评测样本,每个样本均经过严格的隐私敏感性校验,确保其符合现实场景中数据加密的核心需求。数据构建过程特别注重算法多样性与文本域覆盖度的平衡,形成具有密码学复杂性和语言多样性的基准测试集。
特点
该数据集最显著的特征在于其双层评估维度设计:横向覆盖古典密码到自定义加密技术的算法光谱,纵向贯穿隐私保护、金融交易等现实应用场景。样本设计融合了字符级置换(如ParityShift)、词汇级重组(如WordShift)以及复合加密(如DualAvgCode)等多粒度加密方式,有效检验模型对加密规律的归纳能力。基准测试结果展现出前沿大语言模型在密码推理任务上的显著差异,最高性能模型Claude-Sonnet-3.5-1022仅达到45.14%的准确率,凸显该数据集的技术挑战性。
使用方法
使用该数据集时需注意其多配置特性,九种加密算法分别对应独立的JSONL数据文件。研究人员可通过指定config_name加载特定加密类型的测试集,如'Rot13'或'Vigenere',每个样本包含加密文本与原始文本的映射关系。评估时应按照标准协议计算解密准确率,重点关注模型对加密规则的逆向推理能力。该数据集特别适用于大语言模型的密码学推理能力基准测试,也可用于增强模型在隐私敏感场景下的数据处理能力研究。为保障评估严谨性,建议参照论文提供的标准测试流程进行实验设计。
背景与挑战
背景概述
CipherBank是专为评估大型语言模型在密码解密任务中的推理能力而设计的综合性基准数据集。该数据集由多个研究团队联合开发,涵盖了262种独特明文和9种加密算法,涉及古典密码和自定义密码技术三大类别。其核心研究问题聚焦于隐私敏感和现实场景下的加密需求,旨在衡量模型在复杂密码环境中的表现。CipherBank的构建填补了语言模型在密码学领域评估的空白,为模型推理能力的深入研究提供了重要工具。
当前挑战
CipherBank面临的主要挑战体现在两个方面:在领域问题层面,现有语言模型对古典密码算法的理解存在显著不足,特别是在处理多步骤解密推理任务时表现欠佳;在构建过程中,如何平衡数据集的多样性与难度,确保既能全面覆盖各类加密技术,又能准确反映模型的实际解密能力,成为关键难题。此外,隐私敏感数据的模拟生成与加密转换也增加了数据集构建的复杂度。
常用场景
经典使用场景
在密码学与自然语言处理的交叉领域,CipherBank数据集作为评估大型语言模型(LLM)密码解密推理能力的基准工具,其经典使用场景体现在对多种加密算法的系统性测试。研究者通过Rot13、Atbash、Polybius等9种古典与现代混合加密技术生成的2358个问题,量化分析模型在字符替换、位移变换、多字母代换等任务中的表现差异,尤其关注模型对隐私敏感文本的逆向推理能力。
衍生相关工作
基于CipherBank的评估范式,学术界已衍生出若干重要研究:DeepSeek-R1团队提出分层注意力机制提升多步密码推理性能,o1系列模型则受其启发开发了混合符号-神经推理架构。Gemini团队发布的'flash-thinking'模式专门优化了多字母代换类任务的并行计算效率,这些突破性工作均以该数据集作为核心评测基准。
数据集最近研究
最新研究方向
在自然语言处理领域,CipherBank数据集的推出为评估大型语言模型在密码学解密任务中的推理能力提供了全新基准。该数据集涵盖多种经典加密算法和定制密码技术,反映了模型在处理隐私敏感场景时的实际表现。当前研究热点集中在探索专用推理模型与传统通用模型之间的性能差异,特别是Claude-Sonnet-3.5-1022和o1-2024-12-17等先进模型展现出的显著优势。这一研究方向对于理解语言模型在复杂符号操作和逻辑推理方面的局限性具有重要价值,同时也为开发更强大的安全导向型AI系统提供了关键洞见。
以上内容由遇见数据集搜集并总结生成


