endpointing-audio
收藏Hugging Face2025-02-11 更新2025-02-12 收录
下载链接:
https://huggingface.co/datasets/fixie-ai/endpointing-audio
下载链接
链接失效反馈官方服务:
资源简介:
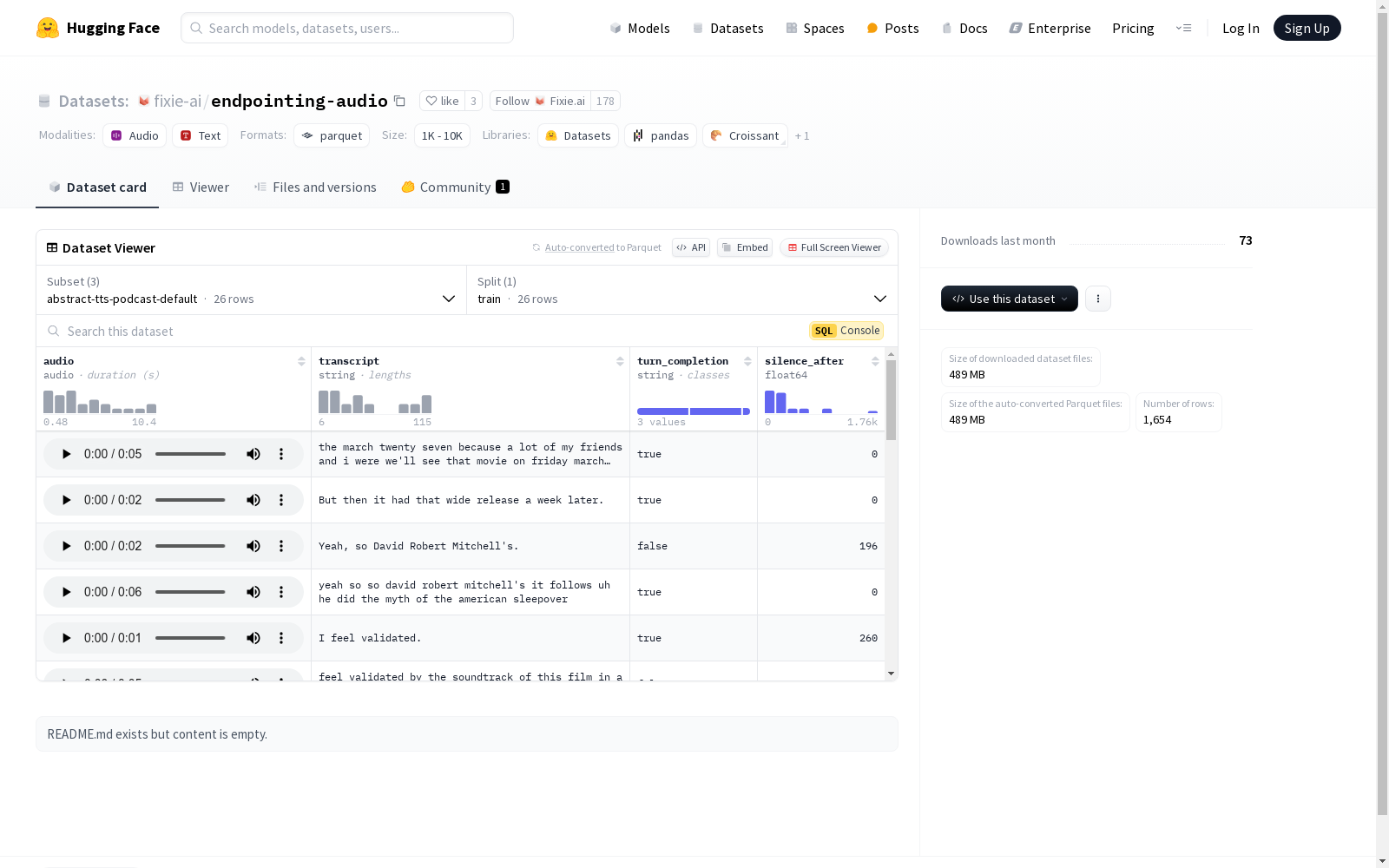
该数据集包含了多个配置的音频及其对应的转录文本,用于语音识别和文本到语音(TTS)任务。每个配置都有训练数据,部分配置还包括测试数据。音频采样率为16000Hz,转录文本为字符串类型,话轮完成标志为布尔类型或字符串类型,静音后的时间为浮点类型。
This dataset contains audios across multiple configurations and their corresponding transcriptions, tailored for speech recognition and text-to-speech (TTS) tasks. Each configuration has training data, and some configurations additionally include test data. The audio sampling rate is 16000 Hz, the transcription text is of string data type, the turn completion flag supports both boolean and string types, and the post-silence time is of floating-point data type.
提供机构:
Fixie.ai创建时间:
2025-02-08
原始信息汇总
数据集概述
数据集名称
- fixie-ai/endpointing-audio
数据集配置
-
abstract-tts-podcast-default
- 采样率:16000 Hz
- 特征:音频,文本,话音完成状态,静音后时长
- 训练集大小:3,357,311 字节,26 个样本
- 下载大小:3,304,057 字节
- 数据集大小:3,357,311 字节
-
common_voice_17_0-en
- 采样率:16000 Hz
- 特征:音频,文本,话音完成状态,静音后时长
- 训练集大小:49,865,671 字节,131 个样本
- 测试集大小:428,243,416.875 字节,1,361 个样本
- 下载大小:468,639,357 字节
- 数据集大小:478,109,087.875 字节
-
default
- 采样率:16000 Hz
- 特征:音频,文本,话音完成状态,静音后时长
- 测试集大小:167,372,994.75 字节,1,306 个样本
- 下载大小:166,429,807 字节
- 数据集大小:167,372,994.75 字节
-
gigaspeech-xl-empty-audio-removed
- 采样率:16000 Hz
- 特征:音频,文本,话音完成状态,静音后时长
- 训练集大小:17,390,693 字节,136 个样本
- 下载大小:17,294,941 字节
- 数据集大小:17,390,693 字节
数据文件路径
-
abstract-tts-podcast-default
- 训练集路径:abstract-tts-podcast-default/train-*
-
common_voice_17_0-en
- 训练集路径:common_voice_17_0-en/train-*
- 测试集路径:common_voice_17_0-en/test-*
-
gigaspeech-xl-empty-audio-removed
- 训练集路径:gigaspeech-xl-empty-audio-removed/train-*
搜集汇总
数据集介绍
构建方式
endpointing-audio数据集的构建,涉及多个配置名称,包括abstract-tts-podcast-default、common_voice_17_0-en、default及gigaspeech-xl-empty-audio-removed。该数据集以音频采样率为16000Hz的音频文件为主,辅以对应的文字转录、对话结束标识以及静音时长等信息。各配置下,数据集被划分为训练集和测试集,音频与转录的对应关系为数据集的核心结构。
特点
该数据集的特点在于,提供了丰富的音频转录对,涵盖不同场景下的语音数据,对于语音识别、语音合成及语音端点检测等研究领域具有重要价值。其转录文本的准确性、音频质量的一致性以及端点检测的相关标注,均为该数据集的显著优势。此外,数据集的多样配置支持不同研究需求的灵活选择。
使用方法
使用endpointing-audio数据集,首先需根据具体配置下载相应数据集。研究者可根据数据集提供的音频和转录文本进行语音识别或语音合成等实验。数据集的turn_completion和silence_after字段,可用于语音端点检测的研究。针对不同的应用场景,研究者可选择适当的配置进行实验,以优化模型的性能表现。
背景与挑战
背景概述
endpointing-audio数据集是一项专注于音频处理和语音识别领域的研究成果,其创建旨在提升自动语音识别系统的准确性,特别是在音频端点的检测上。该数据集的创建时间为近期,由多个配置组成,包括abstract-tts-podcast-default、common_voice_17_0-en和default等,涵盖了不同场景下的音频样本。数据集的主要研究人员或机构尚未明确,但其在语音识别领域的影响力逐渐显现,为相关研究提供了宝贵的资源。
当前挑战
endpointing-audio数据集面临的挑战主要体现在两个方面:一是领域问题上的挑战,即如何准确识别音频中的端点,以区分语音与静默,这对于语音识别系统的性能至关重要;二是构建过程中的挑战,包括音频样本的质量控制、标注一致性保证以及大规模数据集的处理和存储问题。此外,数据集的多样性和覆盖性也是构建过程中必须考虑的关键因素。
常用场景
经典使用场景
endpointing-audio数据集在语音处理领域中被广泛用于研究如何准确判断语音段落的结束点。其包含的音频片段和对应的文字转录,使得研究者能够训练模型以识别语音中的停顿和结束,进而优化语音识别系统的自动分段功能。
实际应用
在实际应用中,endpointing-audio数据集被应用于提升语音助手、自动字幕生成系统以及语音分析工具的性能。通过对该数据集的学习,系统能够更好地理解人类语音的自然停顿,从而提供更加流畅和自然的交互体验。
衍生相关工作
基于endpointing-audio数据集的研究,衍生出了众多相关的经典工作,包括但不限于改进的语音端点检测算法、语音识别的增强模型,以及针对不同语言和口音的适应性研究,推动了语音处理技术的全面发展。
以上内容由遇见数据集搜集并总结生成


