Image-Caption Children in the Wild Dataset (ICCWD)
收藏arXiv2025-06-12 更新2025-06-14 收录
下载链接:
https://huggingface.co/datasets/amcretu/iccwd
下载链接
链接失效反馈官方服务:
资源简介:
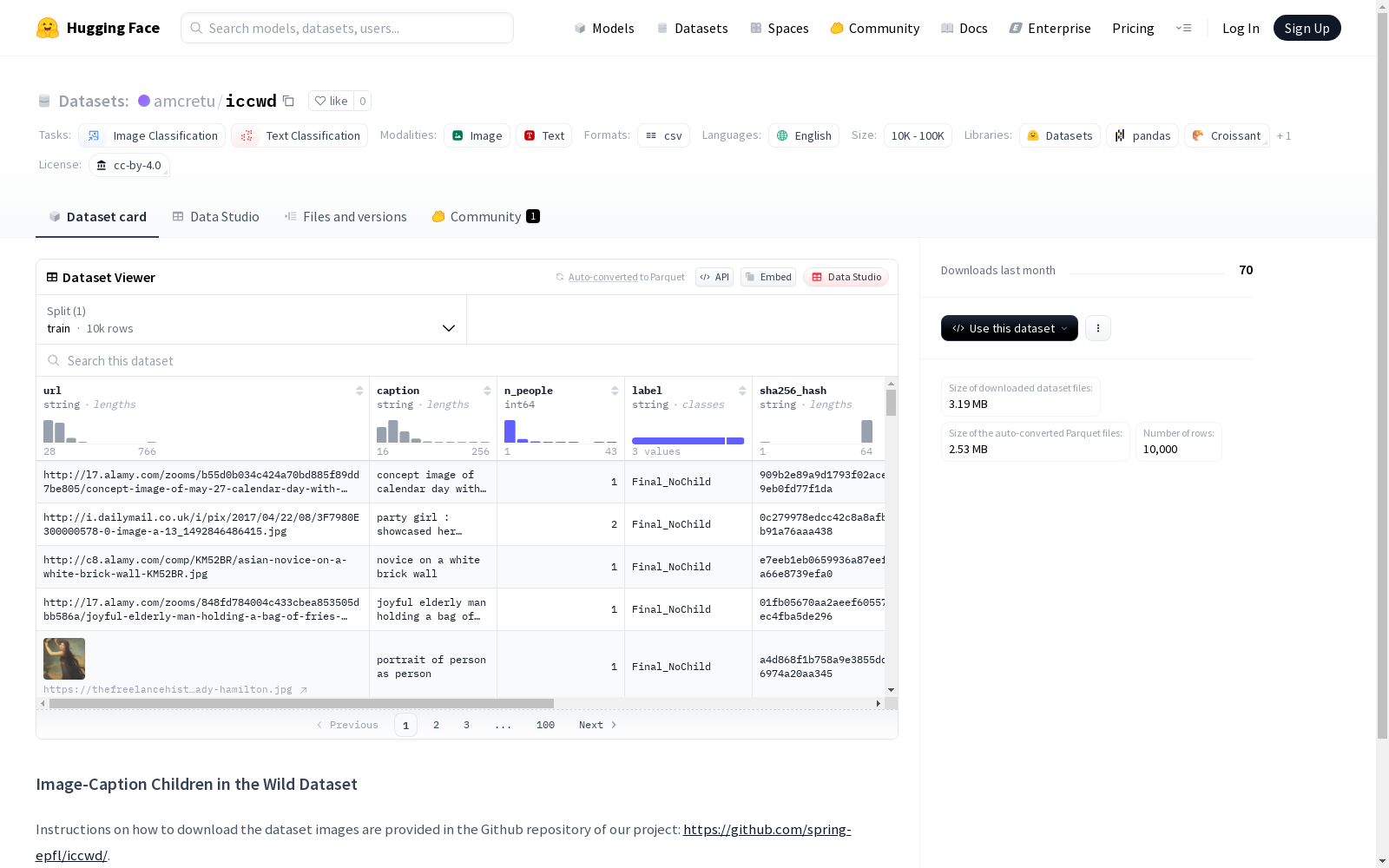
ICCWD是一个包含10,000个图像-标题对的手工标注数据集,用于评估在多模态环境中检测未成年人图像的工具。该数据集比之前的儿童图像数据集更为丰富,包含了各种场景下的儿童图像,包括虚构的描绘和部分可见的身体。数据集旨在帮助设计和评估更好的未成年人检测方法,以应用于各种场景。
ICCWD is a manually annotated dataset consisting of 10,000 image-caption pairs, developed to evaluate tools for detecting images involving minors in multimodal scenarios. Compared with previous child image datasets, this dataset is more comprehensive, covering child images across various scenarios including fictional depictions and partially visible body parts. The dataset is designed to assist in designing and evaluating more advanced minor detection methods for application across diverse scenarios.
提供机构:
MPI-SP & EPFL Bochum, Germany; EPFL Lausanne, Switzerland; Cyber-Defence Campus armasuisse S+T Thun, Switzerland; Georgetown University Washington, D.C., USA
创建时间:
2025-06-12
搜集汇总
数据集介绍
构建方式
Image-Caption Children in the Wild Dataset (ICCWD) 是一个多模态数据集,旨在评估检测未成年人内容的方法。数据集的构建基于Google的Conceptual Captions-3M (CC3M)数据集,从中筛选出包含人物的图像,并通过YOLO-11目标检测器进一步过滤。最终,10,000张图像经过人工标注,标注规则包括对未成年人的定义(18岁以下)、基于视觉年龄的判断以及对虚构人物的涵盖。标注过程中,两位标注者通过讨论解决分歧,确保标注的一致性和准确性。
特点
ICCWD数据集的特点在于其多样性和全面性。它不仅包含真实照片中的未成年人图像,还涵盖了部分可见的身体部位、虚构人物(如卡通和雕像)以及不同背景下的未成年人图像。此外,数据集还提供了图像和文本描述(caption)的配对,使其适用于多模态检测方法的评估。数据集的标注质量高,标注者间的一致性(Cohen-Kappa分数约为0.98)表明任务定义明确,标注结果可靠。
使用方法
ICCWD数据集的使用方法包括评估基于图像、文本或多模态的未成年人检测方法。用户可以通过下载数据集并利用提供的图像和文本描述进行模型训练或测试。数据集还支持验证检测方法在不同场景下的性能,例如面部不可见或虚构人物的检测。此外,数据集提供了图像的哈希值(PDQ和SHA256),以确保数据的完整性和可验证性。用户可以参考论文中的基准测试方法,结合商业或开源工具(如Amazon Rekognition Image和DeepSeek-V3)进行实验。
背景与挑战
背景概述
Image-Caption Children in the Wild Dataset (ICCWD) 是由MPI-SP、EPFL、Cyber-Defence Campus armasuisse S+T以及乔治城大学的研究人员于2025年联合发布的多模态数据集,旨在为检测未成年人内容的算法提供基准测试。该数据集包含10,000个经过人工标注的图像-标题对,覆盖了真实照片、虚构描绘(如卡通、雕像)以及部分可见身体的复杂场景。ICCWD的发布填补了现有数据集中缺乏多模态信息和多样化未成年人描绘的空白,对数字平台内容审核、AI生成内容过滤等应用场景具有重要价值。
当前挑战
ICCWD面临的挑战主要体现在两个方面:领域问题层面,未成年人检测在非面部可见场景(如部分身体、虚构形象)中准确率较低,最佳方法仅达到75.3%的召回率;数据构建层面,标注过程需处理图像质量差异、虚构与现实描绘的年龄判断模糊性等问题,且原始数据中未成年人图像占比仅5.3%,需通过预筛选(如YOLO-11人体检测)提升标注效率。多模态信息利用不充分(如标题与图像语义割裂)也制约了检测性能的提升。
常用场景
经典使用场景
Image-Caption Children in the Wild Dataset (ICCWD) 主要用于评估多模态环境中未成年人检测方法的性能。该数据集包含10,000个图像-标题对,涵盖了各种情境下的儿童图像,包括虚构描绘和部分可见的身体。这使得ICCWD成为评估基于图像和文本信息的未成年人检测方法的理想选择。
解决学术问题
ICCWD填补了当前缺乏多模态未成年人检测数据集的空白。它不仅解决了基于面部图像的年龄估计方法的局限性,还支持评估基于身体部分和虚构图像的检测方法。此外,该数据集为研究如何利用图像和文本信息联合检测未成年人提供了重要资源,推动了相关领域的技术进步。
衍生相关工作
ICCWD的发布促进了多项相关研究,特别是在多模态未成年人检测领域。基于该数据集的研究工作包括开发更鲁棒的图像和文本联合分类器,以及改进现有的年龄估计方法。此外,ICCWD还被用于评估商业年龄估计系统(如Amazon Rekognition)的性能,进一步推动了该领域的技术发展。
以上内容由遇见数据集搜集并总结生成


