FACET
收藏arXiv2023-09-01 更新2024-07-30 收录
下载链接:
https://facet.metademolab.com/
下载链接
链接失效反馈官方服务:
资源简介:
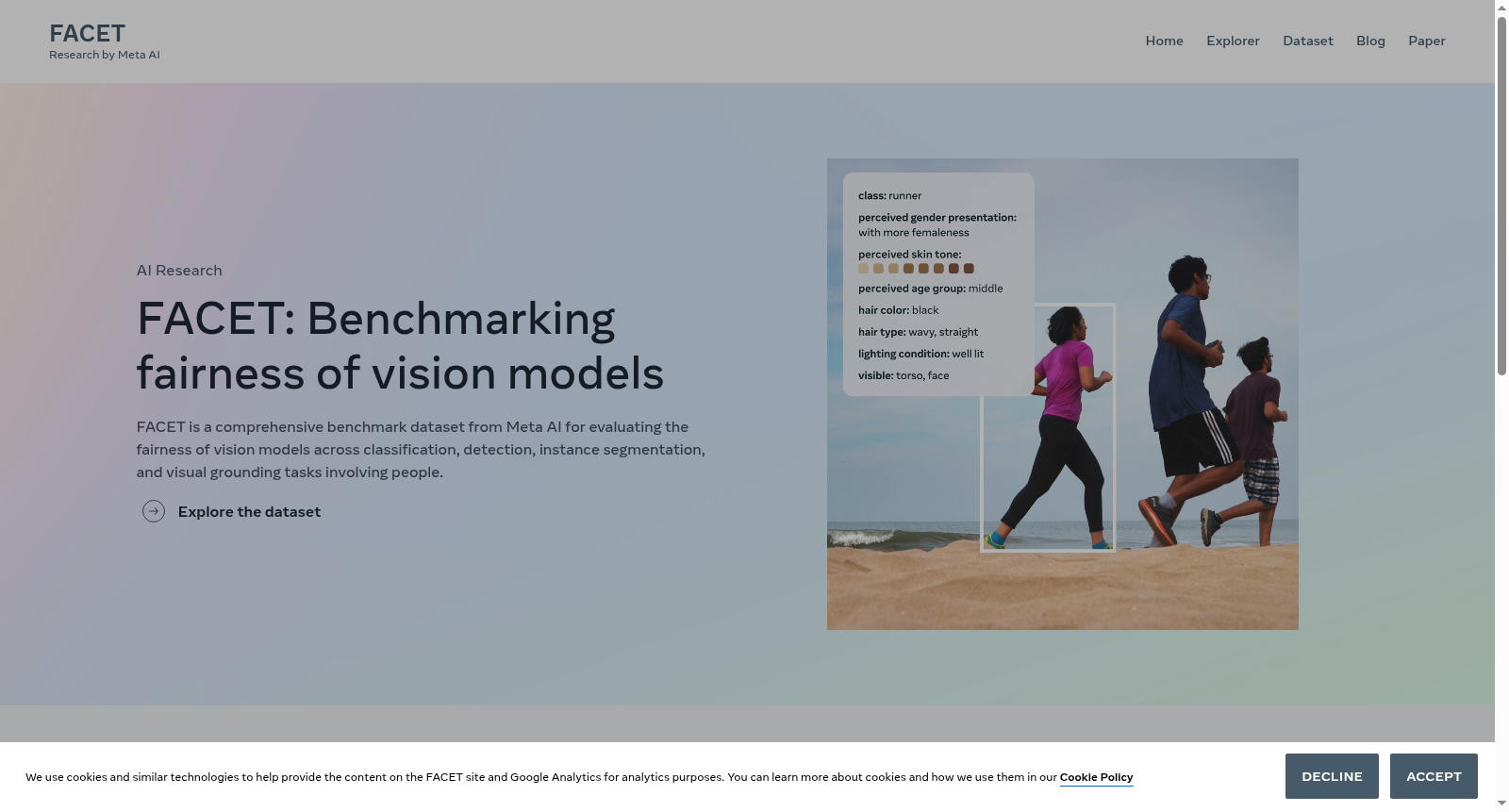
FACET是一个包含32,000张图像的大型公开评估数据集,用于计算机视觉中最常见的任务,如图像分类、目标检测和分割。每个图像都由专家评审员手动标注了与人物相关的属性,如感知肤色和发型,以及精细的人物相关类别,如DJ或吉他手。
FACET is a large-scale public evaluation dataset consisting of 32,000 images, designed for the most prevalent tasks in computer vision including image classification, object detection, and segmentation. Each image has been manually annotated by expert annotators with person-related attributes such as perceived skin tone and hairstyle, as well as fine-grained person-related categories like DJs or guitarists.
创建时间:
2023-09-01
搜集汇总
数据集介绍
构建方式
在计算机视觉模型日益普及的当下,公平性评估成为亟待解决的关键议题。FACET数据集从Segment Anything 1 Billion(SA-1B)中精选32,000张图像,涵盖52个与人物相关的细粒度类别(如吉他手、记者等)。构建过程严谨而细致:首先利用WordNet层级体系筛选类别,确保与ImageNet-21k词汇表兼容;随后通过专家标注员对每张图像中的人物进行边界框绘制、类别标注,并针对感知肤色、感知性别呈现、感知年龄组等13项人口统计与视觉属性进行多轮人工标注。标注员来自北美、拉丁美洲、中东、非洲、东南亚及东亚六个地理区域,以增强标注的多样性。感知肤色采用Monk肤色量表,由三位标注员分别选取至少两个相邻值,最终以分布形式呈现,从而捕捉肤色的连续性与主观差异。
特点
FACET数据集的独特之处在于其标注的全面性与交叉分析能力。它不仅包含52个人物类别和50,000个边界框,还提供了69,000个分割掩码的标签(人物、衣物、头发),支持分类、检测、分割及视觉定位等多种视觉任务。与现有公平性数据集相比,FACET的标注更为详尽:每个图像中符合类别的人物均被完整标注了所有13项属性,包括感知肤色、感知性别呈现、感知年龄组,以及发色、发型、纹身、面部毛发、光照条件、遮挡程度等附加视觉特征。这种穷举式标注使得研究者能够从单一属性(如肤色)和交叉属性(如肤色与发型的结合)两个维度深入探究模型性能差异,揭示模型在特定人口统计群体上的潜在偏见。
使用方法
FACET专为评估而设计,严禁用于模型训练。研究者可将其作为基准测试集,评估现有视觉模型在公平性方面的表现。使用方法灵活多样:对于图像分类任务,可选取仅含单人的图像,计算模型在特定类别与属性组合上的召回率;对于目标检测与分割任务,可利用边界框和掩码标注,计算不同感知肤色、性别或年龄组下的平均召回率;对于开放词汇检测与视觉定位,FACET的类别与ImageNet-21k词汇重叠,可直接评估零样本模型的性能。通过计算不同属性组之间的召回率差异,研究者能够量化模型的不公平程度,并识别出特定类别或属性组合下的性能短板,从而指导模型的改进与优化。
背景与挑战
背景概述
在计算机视觉领域,模型性能在不同人口属性(如性别和肤色)间存在显著差异,这一现象已在图像分类、目标检测等任务中被广泛证实。为系统评估和量化这些不公平性,Meta AI Research的FAIR团队于2023年发布了FACET(Fairness in Computer Vision Evaluation Benchmark)数据集。该数据集包含32,000张图像,覆盖52个人物相关类别(如吉他手、记者),并由来自六大洲的专家标注员手动标注了13种人口属性(包括感知肤色、发型、年龄组等)。FACET的核心研究问题在于:如何通过细粒度、交叉性的人口属性标注,揭示当前最先进视觉模型在分类、检测、分割及视觉定位任务中的性能偏差。该数据集不仅提供了50,000个边界框和69,000个分割掩码,还严格禁止用于训练,仅作为评估基准,推动了视觉公平性研究的标准化进程。
当前挑战
FACET数据集面临的核心挑战包括两方面。首先,在领域问题层面,现有视觉模型普遍存在基于人口属性的性能差异,例如:Faster R-CNN在检测深肤色人群时平均召回率(AR)较浅肤色人群低4个百分点,且这种差异在交叉属性(如卷发与深肤色组合)下进一步放大至近10个百分点;CLIP模型在分类任务中对不同性别呈现的职业类别(如护士与运动员)表现出系统性偏差。其次,在构建过程中,数据集面临标注主观性与多样性难题:感知肤色标注受光照条件和标注者自身背景影响,需采用Monk肤色量表并聚合三位标注者的分布结果;人物类别需从WordNet层级中筛选出52个与ImageNet-21k兼容的细粒度职业/休闲类目,同时排除歧义和冒犯性概念;此外,为保障地理多样性,标注团队需来自北美、拉丁美洲、中东等七个地区,但不同地区标注员的培训通过率存在显著差异,需设计多阶段质量校验流程(如边界框IoU阈值≥0.85、感知肤色多轮复审等)。
常用场景
经典使用场景
在计算机视觉领域,FACET数据集最经典的使用场景是作为公平性评估基准,用于度量图像分类、目标检测与实例分割等核心任务中模型在不同人口统计学属性上的性能差异。该数据集包含32,000张图像,覆盖52类人物相关类别(如医生、吉他手),并对每张图像中的人物进行了感知肤色、感知性别呈现和感知年龄组等13项属性的精细人工标注。研究者可借助FACET,系统性地评估模型在单一属性或交叉属性(如肤色与发型)上的表现偏差,从而揭示视觉系统中潜在的公平性缺陷。
衍生相关工作
FACET数据集的发布催生了一系列衍生研究工作。在评估方法上,研究者基于其交叉属性标注框架,发展了更细粒度的公平性度量指标,如联合考虑肤色与发型的性能差异分析。在模型改进方面,FACET启发了针对检测和分割任务的去偏训练策略,例如通过重采样或损失加权来缓解预测偏差。此外,该数据集还被用于验证开放词汇检测与视觉定位模型(如Detic、OFA)的公平性,推动了多模态模型在公平性评估领域的扩展。这些工作共同构建了从偏差诊断到模型矫正的完整研究链条。
数据集最近研究
最新研究方向
在计算机视觉领域,模型性能在不同人口属性(如性别和肤色)上的差异已成为一个关键的研究焦点。FACET基准数据集应运而生,它包含32,000张图像和50,000人的详尽标注,覆盖52个人物相关类别以及13种属性(如感知肤色、发型和年龄组),旨在系统评估分类、检测、分割和视觉定位等常见视觉任务中的公平性问题。前沿研究方向聚焦于利用FACET进行交叉性分析,例如探究模型在检测具有特定发型和肤色的个体时的性能差异,或评估开放词汇检测模型对不同年龄组人物的识别准确率。这一基准的发布与当前人工智能伦理和公平性热点事件紧密相连,推动了更公平、更鲁棒的视觉模型发展,其深远意义在于为研究社区提供了一个标准化工具,以揭示和缓解模型中的社会偏见,确保所有人群在视觉任务中得到平等对待。
相关研究论文
- 1FACET: Fairness in Computer Vision Evaluation Benchmark · 2023年
以上内容由遇见数据集搜集并总结生成


