persian-gk
收藏Hugging Face2025-08-22 更新2025-08-23 收录
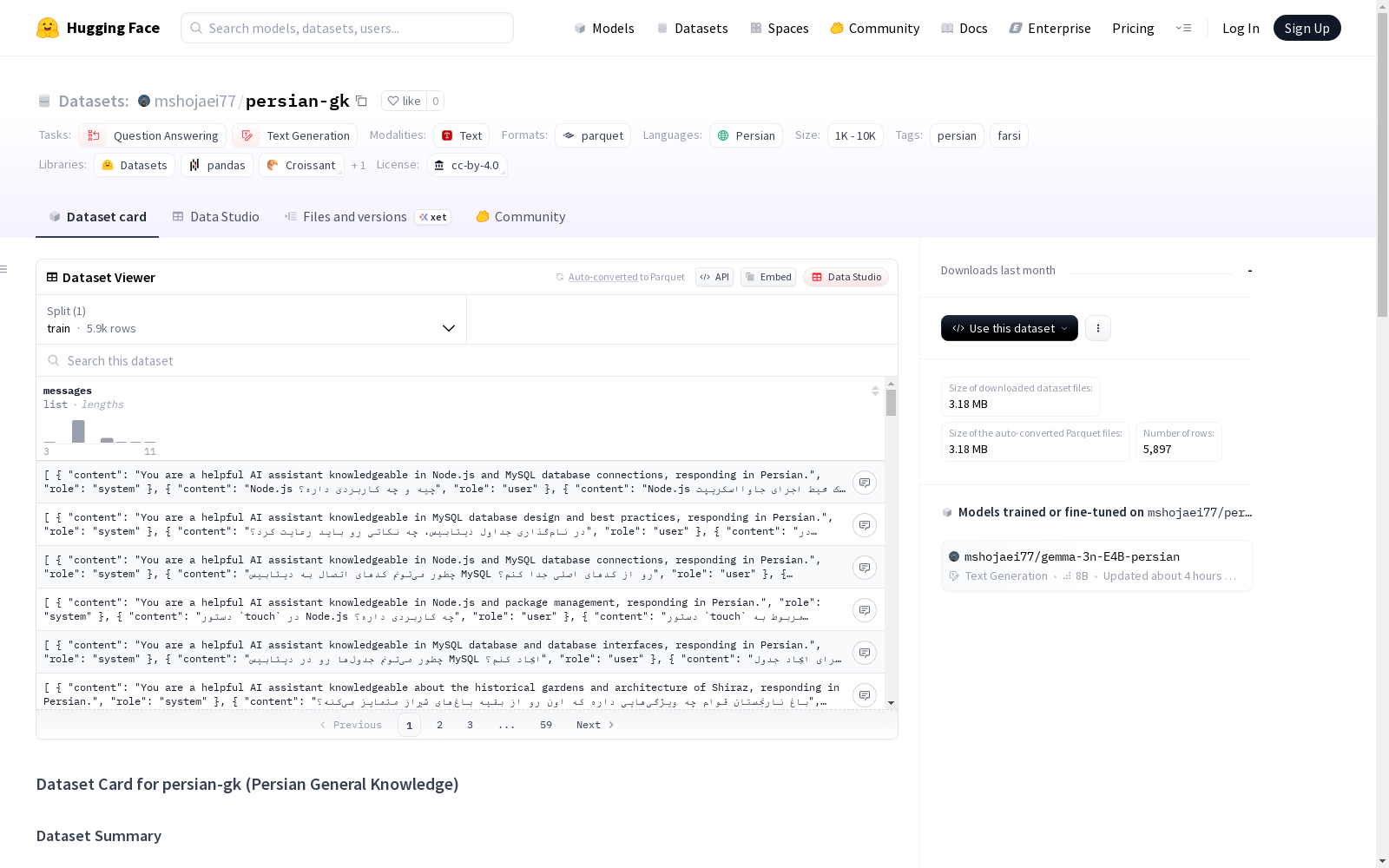
下载链接:
https://huggingface.co/datasets/mshojaei77/persian-gk
下载链接
链接失效反馈官方服务:
资源简介:
Persian General Knowledge是一个清洁且结构化的波斯语(波斯语)对话对集合,覆盖了广泛的一般知识主题。每个对话以ChatML风格格式化,具有明确的*系统*、*用户*和*助手*角色,使得它可以直接用于指令调整和聊天风格的语言模型训练。
Persian General Knowledge is a clean, structured collection of Persian (Farsi) conversational pairs covering a wide range of general knowledge topics. Each conversation is formatted in a ChatML style, with clear *system*, *user*, and *assistant* roles, enabling its direct use for instruction tuning and chat-style language model training.
创建时间:
2025-08-21
原始信息汇总
Persian General Knowledge (persian-gk) 数据集概述
数据集简介
persian-gk 是一个经过清理和结构化的波斯语(Farsi)对话对集合,涵盖广泛的一般知识主题。每个对话均采用 ChatML 风格格式化,具有明确的系统、用户和助理角色,便于直接用于指令微调和聊天式语言模型训练。
基本特征
- 语言:波斯语 (fa)
- 数据规模:5,897 个对话,每个对话 2-8 个轮次(约 150,000 条消息行)
- 领域:编程、波斯遗产、建筑、旅游和各种问答等
- 许可证:CC-BY-4.0
- 来源:从公共波斯语博客、问答资源和手动编写的系统提示中整理而来
技术规格
- 特征结构:
- messages:
- content: string
- role: string
- messages:
- 数据分割:
- train: 5,897 个样本(7,201,128 字节)
- 下载大小:2,969,604 字节
- 数据集大小:7,201,128 字节
支持任务
- 指令微调/聊天完成 - 为波斯语对话或问答微调模型
- 基于知识的生成 - 评估模型在波斯语中的事实一致性
- 领域适应 - 使多语言模型适应波斯语一般知识领域
使用方式
python from datasets import load_dataset
ds = load_dataset("mshojaei77/persian-gk", split="train") print(ds[0]["messages"])
引用信息
@misc{persian_gk_2024, title = {persian-gk: Persian General Knowledge Chat Dataset}, author = {Shojaei, M. and Contributors}, year = {2024}, url = {https://huggingface.co/datasets/mshojaei77/persian-gk} }
搜集汇总
数据集介绍
构建方式
在波斯语自然语言处理领域,数据稀缺性长期制约着模型性能的提升。persian-gk数据集通过系统化采集策略构建,从公开的波斯语博客、问答社区资源中精选高质量内容,并辅以人工编写的系统提示词。所有对话均采用ChatML结构化格式进行标准化处理,确保每条数据包含明确的系统角色、用户查询和助手回复三重语义层级,为模型训练提供精准的对话上下文框架。
特点
该数据集显著特征体现在其多维度知识覆盖与语言纯粹性。涵盖编程、文化遗产、建筑艺术及旅游等多元领域,5897组对话包含2-8轮动态交互,总计约15万条消息构成丰富的语义网络。采用纯波斯语语料保持语言一致性,ChatML格式天然支持指令微调与对话生成双训练范式,为波斯语大模型提供兼具广度与深度的知识基底。
使用方法
研究者可通过Hugging Face数据集库直接加载使用,内置的ChatML格式无需额外预处理即可适配主流对话模型架构。支持两种应用模式:直接调用messages字段获取结构化对话数据,或通过格式转换函数呈现为自然文本序列。该数据集特别适用于波斯语对话系统的指令微调、知识增强生成任务,以及多语言模型在波斯语领域的适应性训练。
背景与挑战
背景概述
波斯语通用知识数据集persian-gk诞生于2024年,由研究者Shojaei及其合作团队构建,致力于填补波斯语自然语言处理领域高质量对话数据的空白。该数据集聚焦于多领域知识对话生成任务,涵盖编程、文化遗产、建筑旅游等主题,采用标准化的ChatML格式进行结构化处理,为波斯语大语言模型的指令微调与知识增强提供了重要基础资源,显著推动了波斯语人工智能生态的发展。
当前挑战
该数据集核心挑战在于解决波斯语知识型对话系统中事实一致性弱与领域覆盖不足的问题,需确保模型生成内容的准确性与多样性。构建过程中面临多源数据融合的复杂性,包括从波斯语博客和问答平台提取知识时的噪声过滤、文化特定表达的标准化处理,以及对话回合结构的语义对齐,这些因素均对数据质量与模型泛化能力构成严峻考验。
常用场景
经典使用场景
在波斯语自然语言处理研究中,该数据集被广泛用于构建对话系统的指令微调场景。研究人员通过其ChatML结构化对话格式,能够有效训练模型理解多轮对话的上下文逻辑,特别适用于处理波斯文化遗产、编程指导与旅游咨询等领域的复杂问答任务。数据集包含的系统角色设定为用户与助手间的交互提供了清晰的语义边界,显著提升了对话生成任务的训练效率。
实际应用
实际应用中,该数据集成为开发波斯语智能助手的关键训练资源,被集成于客服机器人、教育问答平台及文化传播工具中。伊朗本土科技企业利用其多领域对话数据构建面向旅游导览和传统工艺讲解的交互系统,同时支持政府机构开发多语言公共服务助手,促进波斯语数字化服务的普及与优化。
衍生相关工作
基于该数据集衍生的经典工作包括PersianLLaMA多语言指令微调框架和ParsGPT对话生成模型。德黑兰大学团队利用其构建了波斯语事实核查评估基准PersFact,而Sharif理工大学则开发了面向文化遗产的领域自适应模型CultuReBot,这些成果显著推动了波斯语NLP社区在知识增强生成任务中的研究进展。
以上内容由遇见数据集搜集并总结生成


