ryanhe/VIP
收藏Hugging Face2023-12-23 更新2024-03-04 收录
下载链接:
https://hf-mirror.com/datasets/ryanhe/VIP
下载链接
链接失效反馈官方服务:
资源简介:
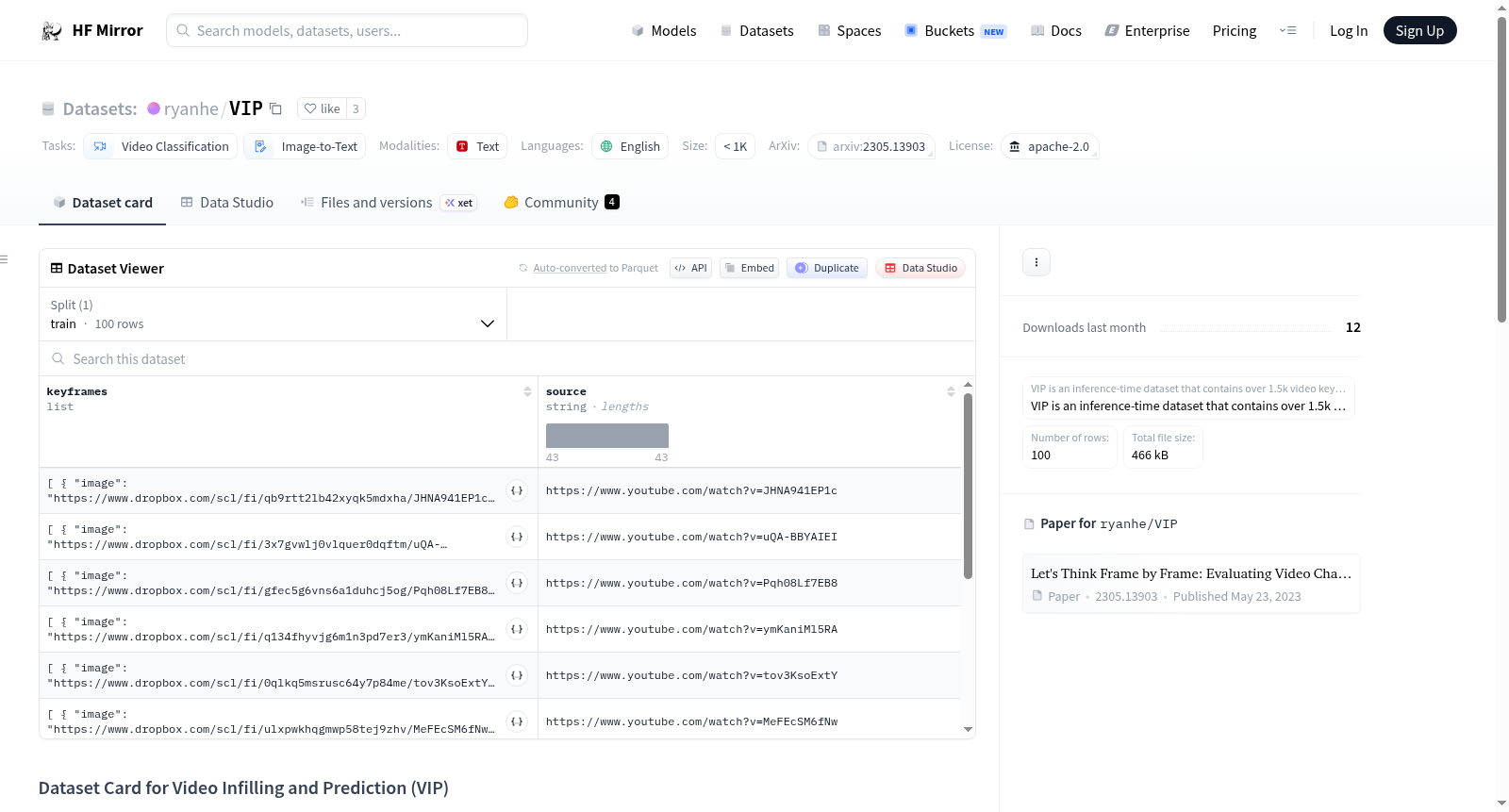
VIP(Video Infilling and Prediction)是一个用于评估视觉语言模型顺序常识推理能力的基准数据集,通过生成视频的解释来进行评估。该数据集包含超过1.5k的视频关键帧,并为每个关键帧提供了两种形式的文本描述:一种是非结构化的密集描述,另一种是结构化描述,明确定义了每个关键帧的焦点、动作、情绪、对象和设置(FAMOuS)。
VIP(Video Infilling and Prediction)是一个用于评估视觉语言模型顺序常识推理能力的基准数据集,通过生成视频的解释来进行评估。该数据集包含超过1.5k的视频关键帧,并为每个关键帧提供了两种形式的文本描述:一种是非结构化的密集描述,另一种是结构化描述,明确定义了每个关键帧的焦点、动作、情绪、对象和设置(FAMOuS)。
提供机构:
ryanhe
原始信息汇总
数据集卡片 - 视频填充与预测 (VIP)
数据集详情
数据集描述
- 名称: 视频填充与预测 (VIP)
- 目的: 评估视觉-语言模型在生成视频解释时的序列常识推理能力
- 语言: 英语
- 包含内容: 超过1.5k个视频关键帧,每个关键帧有两种形式的文本描述:非结构化密集标题和结构化描述(定义焦点、动作、情绪、物体和场景)
数据集来源与创建
- 数据来源: 使用Youtube-8M数据集收集视频
- 创建过程: 采用流水线方法提取关键帧和描述,每个描述都经过人工验证
任务定义
- 视频填充 (Video Infilling): 给定1、2或3个周围关键帧,预测中间的关键帧
- 视频预测 (Video Prediction): 给定1、2或3个先前关键帧,预测后续的关键帧
- 使用方式: 可以使用关键帧图像、关键帧描述或两者的组合来完成任务
引用信息
@inproceedings{
himakunthala2023lets,
title={Lets Think Frame by Frame with {VIP}: A Video Infilling and Prediction Dataset for Evaluating Video Chain-of-Thought},
author={Vaishnavi Himakunthala and Andy Ouyang and Daniel Philip Rose and Ryan He and Alex Mei and Yujie Lu and Chinmay Sonar and Michael Saxon and William Yang Wang},
booktitle={The 2023 Conference on Empirical Methods in Natural Language Processing},
year={2023},
url={https://openreview.net/forum?id=y6Ej5BZkrR}
}
搜集汇总
数据集介绍
构建方式
在视频理解与推理领域,VIP数据集通过系统化的流程构建而成。该数据集源自YouTube-8M视频库,采用管道化方法提取关键帧,并为每一帧生成两种文本描述:一种是无结构的密集字幕,另一种是结构化描述,明确界定焦点、动作、情绪、对象和场景(FAMOuS)。所有描述均经过人工标注验证,确保了内容的准确性与可靠性,为评估视觉语言模型的序列常识推理能力提供了坚实基础。
特点
VIP数据集的核心特点在于其双重描述体系与任务导向设计。数据集包含超过1500个视频关键帧,每帧均配有密集字幕和结构化FAMOuS描述,这种双重视角丰富了语义表达。数据集专门定义了视频填充与视频预测两项新颖任务,支持基于图像、文本或两者结合的多种评估模式,为模型在时序推理与跨模态理解方面的性能提供了多维度的评测基准。
使用方法
使用VIP数据集时,研究者可针对视频填充或视频预测任务展开实验。视频填充任务要求模型根据1至3个周围关键帧预测中间帧;视频预测任务则需基于先前关键帧预测后续帧。实验可灵活选择仅使用关键帧图像、仅使用文本描述或结合两者作为输入,以此评估不同视觉语言模型在序列推理中的表现。具体实施细节可参考相关学术论文,确保方法论的严谨性。
背景与挑战
背景概述
视频推理与预测数据集(VIP)由加州大学圣塔芭芭拉分校的研究团队于2023年创建,旨在评估视觉语言模型在视频序列中的常识推理能力。该数据集源自YouTube-8M,包含超过1500个视频关键帧,并为每帧提供非结构化密集字幕和结构化FAMOuS描述,聚焦于动作、对象、情绪等要素。其核心研究问题在于推动模型对视频时序逻辑的理解与生成,为视频链式思维研究提供了标准化基准,对多模态人工智能领域的发展具有显著影响力。
当前挑战
VIP数据集致力于解决视频序列中的常识推理挑战,特别是在视频填充与预测任务中,模型需依据不完整的关键帧信息推断缺失或未来内容,这对时序逻辑与跨模态对齐提出了较高要求。在构建过程中,研究团队面临从海量视频中提取代表性关键帧的筛选难题,同时确保结构化描述的准确性与一致性也依赖大量人工标注,这些因素共同构成了数据集可靠性与泛化能力的基础障碍。
常用场景
经典使用场景
在视频理解与推理领域,VIP数据集为评估视觉语言模型的序列常识推理能力提供了基准。其核心应用场景在于视频填充与预测任务,通过提供视频关键帧及其结构化描述,模型需基于给定的前后帧或历史帧,生成中间或未来帧的合理解释。这一过程不仅考验模型对视觉内容的感知,更强调其对时间逻辑与事件因果的深层推断,为视频链式思维研究奠定了数据基础。
实际应用
在实际应用中,VIP数据集可服务于智能视频分析、内容生成与辅助决策系统。例如,在安防监控中,模型能基于片段视频预测潜在事件发展;在教育或娱乐领域,可自动生成视频情节描述或补全缺失画面。其结构化描述亦有助于提升视频摘要的准确性与连贯性,为自动化内容创作、人机交互等场景提供时序推理支持,增强系统对复杂动态场景的语义理解能力。
衍生相关工作
围绕VIP数据集,已衍生出多项经典研究工作。例如,基于其视频填充与预测任务,研究者探索了多模态Transformer架构的时序扩展,以及结合链式思维提示的视频推理方法。部分工作进一步利用FAMOuS结构化描述,开发了细粒度视频语义解析模型。这些研究不仅深化了视频常识推理的理论框架,也为视觉语言预训练、跨模态生成等方向提供了新的实验基准与优化路径。
以上内容由遇见数据集搜集并总结生成


