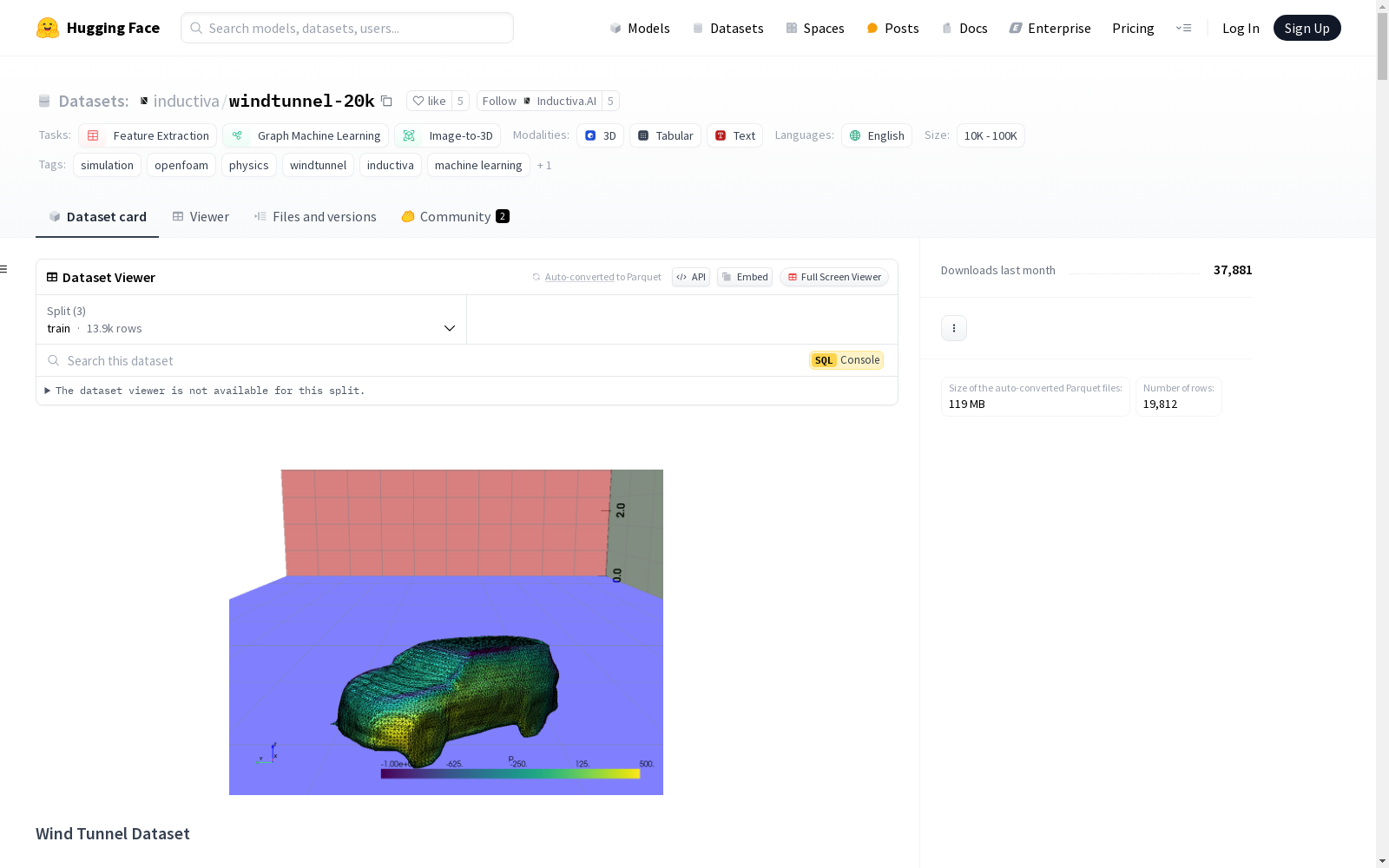
windtunnel
收藏Wind Tunnel Dataset
概述
- 数据集名称: Wind Tunnel dataset
- 数据量: 20,000个OpenFOAM模拟
- 对象数量: 1,000个独特的类似汽车的对象
- 模拟条件:
- 4种随机风速(10到50 m/s)
- 5种旋转角度(0°, 180°和3个随机角度)
- 模拟迭代次数: 300次
- 数据集划分:
- 训练集: 70%
- 验证集: 20%
- 测试集: 10%
数据生成
- 工具: Inductiva API
- 网格生成: Instant Mesh model
- 对象来源: Stanford Cars Dataset
数据结构
data ├── train │ ├── <SIMULATION_ID> │ │ ├── input_mesh.obj │ │ ├── openfoam_mesh.obj │ │ ├── pressure_field_mesh.vtk │ │ ├── simulation_metadata.json │ │ └── streamlines_mesh.ply │ └── ... ├── validation │ └── ... └── test └── ...
文件说明
- input_mesh.obj: 输入网格的OBJ文件
- openfoam_mesh.obj: OpenFOAM网格的OBJ文件
- pressure_field_mesh.vtk: 压力场数据的VTK文件
- streamlines_mesh.ply: 流线的PLY文件
- metadata.json: 包含输入参数和输出结果(如力系数)的JSON文件
下载方式
1. 使用snapshot_download()
python from huggingface_hub import snapshot_download
dataset_name = "inductiva/windtunnel"
下载整个数据集
snapshot_download(repo_id=dataset_name, repo_type="dataset")
下载到指定本地目录
snapshot_download(repo_id=dataset_name, repo_type="dataset", local_dir="local_folder")
仅下载所有模拟的元数据
snapshot_download( repo_id=dataset_name, repo_type="dataset", local_dir="local_folder", allow_patterns=["//*/simulation_metadata.json"] )
2. 使用load_dataset()
python from datasets import load_dataset
加载数据集(支持流式加载)
dataset = load_dataset("inductiva/windtunnel", streaming=False)
显示数据集信息
print(dataset)
访问训练集中的样本
sample = dataset["train"][0] print("训练集样本:", sample)