reczoo/Criteo_x4
收藏Hugging Face2023-12-24 更新2024-03-04 收录
下载链接:
https://hf-mirror.com/datasets/reczoo/Criteo_x4
下载链接
链接失效反馈官方服务:
资源简介:
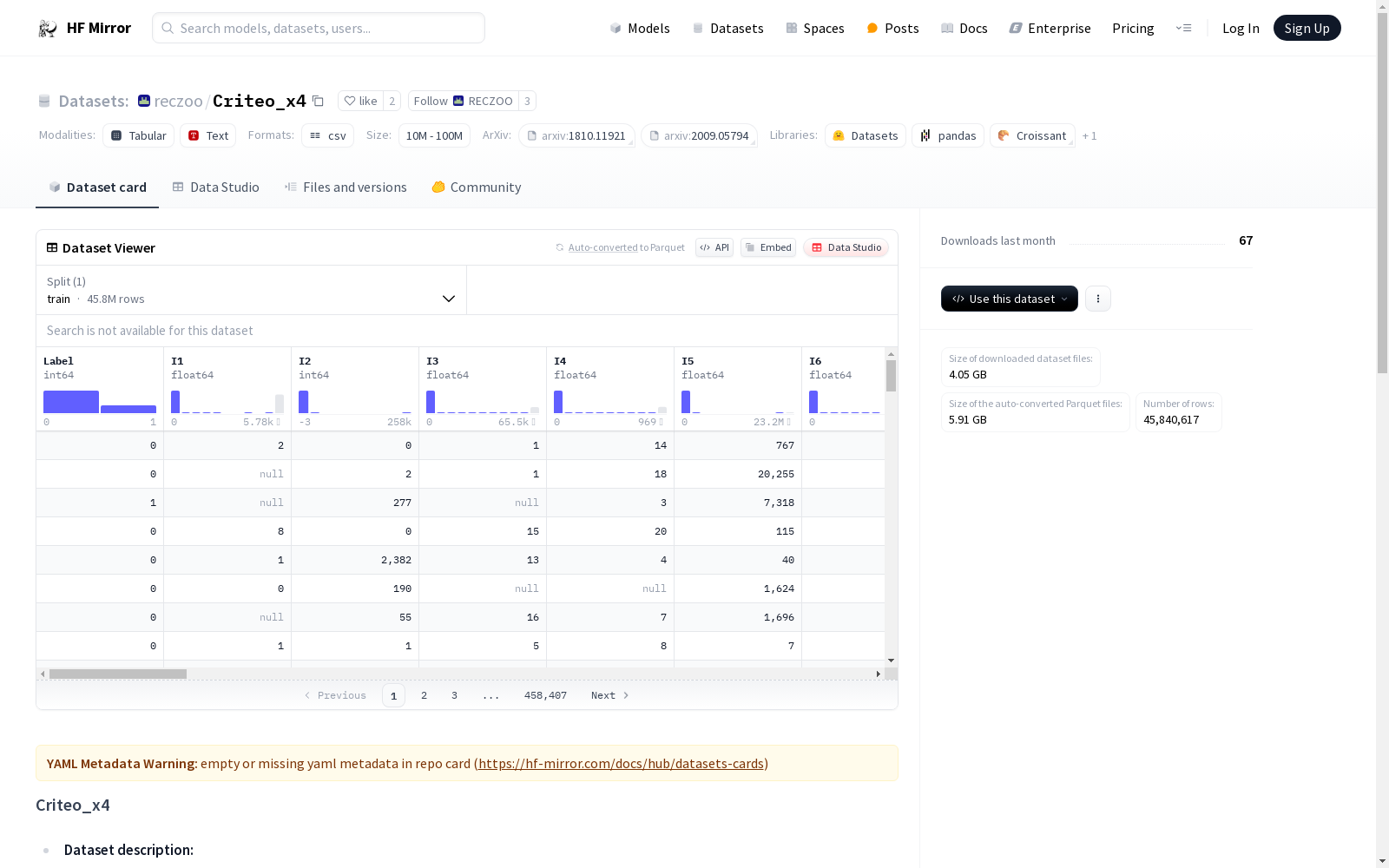
Criteo数据集是一个广泛用于点击率预测(CTR prediction)的基准数据集,包含大约一周的展示广告点击数据。该数据集包含13个数值特征字段和26个类别特征字段。按照AutoInt工作的设置,数据被随机分割为训练集、验证集和测试集,比例分别为8:1:1。数据集统计信息如下:Criteo_x4总共有45,840,617条数据,其中训练集36,672,493条,验证集4,584,062条,测试集4,584,062条。Criteo_x4_001和Criteo_x4_002是两种不同的预处理设置,分别采用了不同的离散化方法和类别特征处理方式。
Criteo数据集是一个广泛用于点击率预测(CTR prediction)的基准数据集,包含大约一周的展示广告点击数据。该数据集包含13个数值特征字段和26个类别特征字段。按照AutoInt工作的设置,数据被随机分割为训练集、验证集和测试集,比例分别为8:1:1。数据集统计信息如下:Criteo_x4总共有45,840,617条数据,其中训练集36,672,493条,验证集4,584,062条,测试集4,584,062条。Criteo_x4_001和Criteo_x4_002是两种不同的预处理设置,分别采用了不同的离散化方法和类别特征处理方式。
提供机构:
reczoo
原始信息汇总
Criteo_x4 数据集概述
数据集描述
Criteo_x4 数据集是一个广泛使用的点击率(CTR)预测基准数据集,包含约一周的展示广告点击数据。该数据集包含13个数值特征字段和26个分类特征字段。数据集按照8:1:1的比例随机分为训练集、验证集和测试集。
数据集统计信息
| 数据集划分 | 总数 | 训练集 | 验证集 | 测试集 |
|---|---|---|---|---|
| Criteo_x4 | 45,840,617 | 36,672,493 | 4,584,062 | 4,584,062 |
数据预处理设置
Criteo_x4_001
在此设置中,我们按照Criteo挑战赛获胜者的解决方案,将每个整数值x离散化为⌊log2(x)⌋(如果x > 2),否则x = 1。对于所有分类字段,我们将不频繁的特征替换为默认的<OOV>标记,阈值设置为min_category_count=10。我们固定embedding_dim=16,与AutoInt一致。
Criteo_x4_002
在此设置中,我们按照Criteo挑战赛获胜者的解决方案,将每个整数值x离散化为⌊log2(x)⌋(如果x > 2),否则x = 1。对于所有分类字段,我们将不频繁的特征替换为默认的<OOV>标记,阈值设置为min_category_count=2。我们固定embedding_dim=40。
数据完整性校验
数据文件的md5校验和如下:
bash $ md5sum train.csv valid.csv test.csv 4a53bb7cbc0e4ee25f9d6a73ed824b1a train.csv fba5428b22895016e790e2dec623cb56 valid.csv cfc37da0d75c4d2d8778e76997df2976 test.csv
搜集汇总
数据集介绍
构建方式
Criteo_x4数据集是一份面向点击率(CTR)预测的权威数据集,其数据来源于一周内的展示广告点击数据。该数据集包含了13个数值特征字段和26个分类特征字段。数据集的构建遵循了AutoInt工作中提出的设置,将数据随机划分为训练集、验证集和测试集,比例分别为8:1:1,确保了数据集的可用性和可靠性。
特点
Criteo_x4数据集的特点体现在其详尽的字段设置和严谨的数据划分上。数据集不仅包含了丰富的数值和分类特征,而且在处理分类字段时,对于不频繁出现的特征采用统一的<OOV>标记替代,这一做法提高了模型的泛化能力。此外,数据集的两种设置(Criteo_x4_001和Criteo_x4_002)在特征离散化和嵌入维度上有所不同,为研究者提供了多样化的实验条件。
使用方法
使用Criteo_x4数据集时,用户可以遵循数据集中的两种预设配置,根据不同的需求选择适合的设置。数据集的获取和验证通过HuggingFace的接口进行,确保了数据的完整性和一致性。用户在获取数据后,可以根据提供的md5sum值校验数据完整性,进而利用数据集进行模型训练、验证和测试,推动CTR预测领域的研究与应用。
背景与挑战
背景概述
Criteo_x4数据集是广告点击率(CTR)预测领域中广泛使用的一个基准数据集,其包含了大约一周的展示广告点击数据。该数据集由13个数值特征字段和26个分类特征字段组成。其创建时间是针对Criteo广告挑战赛,主要研究人员来自于多个学术机构和工业界,核心研究问题是如何准确预测广告的点击率。Criteo_x4数据集对广告投放优化、推荐系统等领域产生了深远的影响,被广泛应用于模型训练和性能评估。其影响力在相关学术文献中得以体现,如Song等人在2019年的CIKM会议上发表的AutoInt工作,以及Zhu等人在2021年的CIKM会议上提出的BARS-CTR开放基准。
当前挑战
Criteo_x4数据集在构建和应用过程中面临诸多挑战。首先,数据集的离散化处理需要合理设定阈值,以避免特征过多导致的计算复杂度和过拟合问题。其次,数据预处理中的特征嵌入维度选择对模型性能有显著影响,需要经过细致的实验来确定最佳值。此外,在数据集中,稀疏特征的处理是一个挑战,因为它们可能对模型的泛化能力产生重要影响。而对于研究领域问题,即点击率预测的挑战,主要在于如何准确捕捉用户意图和广告内容之间的复杂交互关系。
常用场景
经典使用场景
在计算广告领域,reczoo/Criteo_x4数据集被广泛用于点击率(CTR)预测的研究。该数据集包含约一周的展示广告点击数据,具备13个数值特征字段和26个分类特征字段。其经典的运用场景在于,通过训练模型预测用户对特定广告的点击概率,从而优化广告投放策略,提升广告效果。
解决学术问题
reczoo/Criteo_x4数据集解决了广告投放中如何精确预测用户点击行为的问题。通过该数据集,研究者能够探索并构建更为高效的CTR预测模型,进而提高广告系统的收益和投资回报率。此外,该数据集有助于推动广告算法领域的发展,提升算法的泛化能力和鲁棒性。
衍生相关工作
reczoo/Criteo_x4数据集衍生了诸多经典工作,如AutoInt模型,该模型通过自注意力机制自动学习特征交互,显著提升了CTR预测的准确性。此外,BARS-CTR作为开放性CTR预测基准,也是基于该数据集进行的一系列研究工作的成果之一。
以上内容由遇见数据集搜集并总结生成


