1aurent/ADE20K
收藏Hugging Face2024-05-19 更新2024-05-25 收录
下载链接:
https://hf-mirror.com/datasets/1aurent/ADE20K
下载链接
链接失效反馈官方服务:
资源简介:
ADE20K数据集由来自SUN和Places数据库的超过27,000张图像组成。这些图像完全标注了超过3,000个对象类别,并且许多图像还包含对象的部分和部分的部分。数据集提供了原始标注的多边形以及用于非模态分割的对象实例。图像经过匿名化处理,模糊了面部和车牌。数据集的使用受限于非商业研究和教育目的,并且需要遵守特定的条款和条件。
The ADE20K dataset comprises over 27,000 images sourced from the SUN and Places databases. All images are fully annotated with more than 3,000 object categories, and many of them additionally contain annotations for object parts and their sub-parts. The dataset provides both the original polygonal annotations and object instance-level annotations for panoptic segmentation. All images have been anonymized, with faces and license plates blurred to safeguard personal information. Usage of the dataset is restricted solely to non-commercial research and educational purposes, and users must comply with its specified terms and conditions.
提供机构:
1aurent
原始信息汇总
ADE20K Dataset Summary
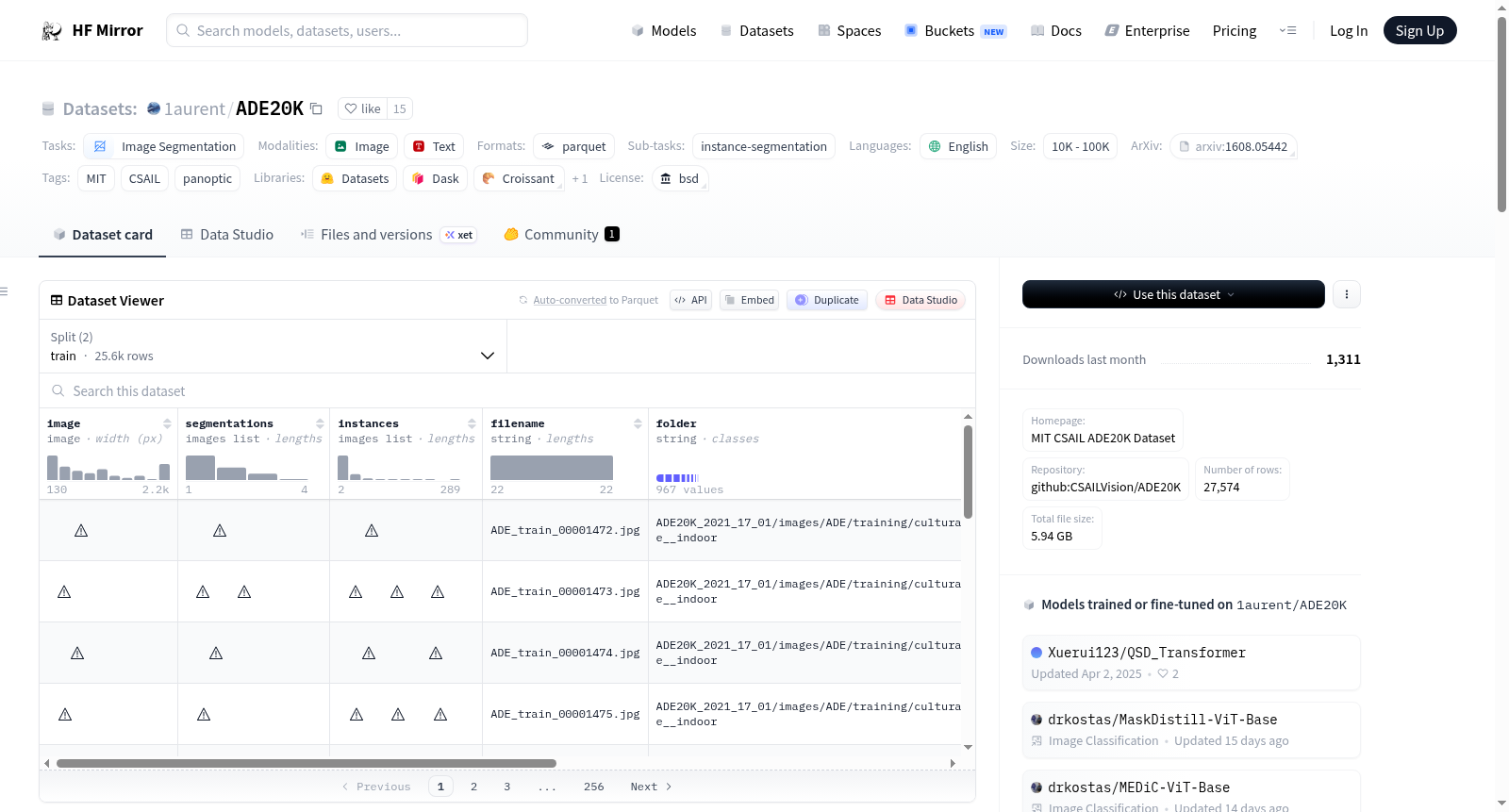
Dataset Features
- image: RGB image data.
- segmentations: RGB image data.
- instances: Grayscale image data.
- filename: String data type.
- folder: String data type.
- source: Structured data including
folder,filename, andorigin, all of string data type. - scene: Sequence of string data.
- objects: List of structured data including:
id: UInt16 data type.name: String data type.name_ndx: UInt16 data type.hypernym: Sequence of string data.raw_name: String data type.attributes: String data type.depth_ordering_rank: UInt16 data type.occluded: Boolean data type.crop: Boolean data type.parts: Structured data includingis_part_of(UInt16),part_level(UInt8), andhas_parts(Sequence of UInt16).polygon: Structured data includingxandy(Sequences of UInt16), andclick_date(Sequence of timestamp in microseconds).saved_date: Timestamp in microseconds.
Dataset Splits
- train: 25574 examples, total size 4812448179.314 bytes.
- validation: 2000 examples, total size 464280715 bytes.
Dataset Size
- Download size: 5935251309 bytes.
- Dataset size: 5276728894.314 bytes.
License
- BSD License.
Task Categories
- Image-segmentation.
Task IDs
- Instance-segmentation.
Language
- English.
Tags
- MIT
- CSAIL
- panoptic
Size Categories
- 10K<n<100K
Multilinguality
- Monolingual.
Annotations Creators
- Crowdsourced
- Expert-generated
搜集汇总
数据集介绍
构建方式
在计算机视觉领域,场景解析数据集对于推动语义分割研究至关重要。ADE20K数据集构建于SUN和Places数据库之上,汇聚了超过27,000张图像,通过专家与群体协作的方式进行了精细标注。每张图像不仅标注了超过3,000个对象类别,还深入标注了对象的部分及子部分结构,同时提供了原始多边形注释和对象实例信息,以支持非模态分割任务。为确保隐私合规,数据集对图像中的人脸和车牌信息进行了匿名化处理,体现了数据构建的严谨性与伦理考量。
使用方法
研究人员可通过HuggingFace平台便捷访问ADE20K数据集,利用其标准化的数据分割,其中训练集包含25,574个样本,验证集包含2,000个样本。数据集以图像、分割掩码、实例标注及元数据的结构化格式提供,支持直接加载至主流深度学习框架进行模型训练与评估。在非商业研究及教育用途下,用户可依据BSD-3许可协议使用标注与软件,并通过指定流程申请原始图像访问权限,以开展场景解析、语义分割等视觉任务研究。
背景与挑战
背景概述
ADE20K数据集由麻省理工学院计算机科学与人工智能实验室(MIT CSAIL)于2017年推出,旨在推动场景解析与语义分割领域的研究。该数据集汇集了超过27,000张源自SUN和Places数据库的图像,并提供了超过3,000个对象类别的精细标注,涵盖对象、对象部件乃至部件之部件的多层次注释。其核心研究问题聚焦于复杂场景的全面语义理解,通过丰富的实例分割与模态分割标注,为计算机视觉模型在真实世界环境中的感知能力奠定了重要基础,对场景理解、图像分割及视觉推理等研究方向产生了深远影响。
当前挑战
ADE20K数据集致力于解决场景解析中语义分割与实例分割的复杂挑战,其核心问题在于如何准确识别并分割图像中密集、多样且可能相互遮挡的物体。构建过程中面临多重困难:数据标注需处理超过3,000个类别,涵盖对象及其部件的层次化结构,标注一致性难以保证;图像来源多样,场景复杂,物体尺度、姿态及光照变化显著,增加了标注难度;同时,为保护隐私而对人脸和车牌进行模糊处理,可能影响部分视觉任务的完整性。这些因素共同构成了数据集构建与应用中的关键挑战。
常用场景
经典使用场景
在计算机视觉领域,ADE20K数据集作为场景解析任务的核心基准,其经典应用体现在为语义分割和实例分割模型提供训练与评估平台。该数据集包含超过27,000张图像,涵盖3,000余个对象类别,并附有精细的像素级标注,包括对象、对象部分乃至部分的部分,为模型理解复杂场景的层次结构提供了丰富信息。研究人员常利用其训练深度神经网络,以提升模型在多样化环境下的分割精度和泛化能力,推动了场景理解技术的进步。
解决学术问题
ADE20K数据集有效解决了场景解析中对象类别繁多、标注粒度不足的学术挑战。通过提供大规模、多层次的标注数据,它支持了模态分割研究,使模型能够推断被遮挡对象的完整形状,从而深化对场景语义的理解。该数据集促进了计算机视觉领域在细粒度识别、场景层次建模等方面的突破,为后续研究奠定了坚实的数据基础,显著提升了算法在真实世界复杂环境中的鲁棒性和准确性。
实际应用
在实际应用中,ADE20K数据集为自动驾驶、智能监控和增强现实系统提供了关键支持。其丰富的场景标注帮助训练视觉模型准确识别道路元素、行人及障碍物,提升自动驾驶车辆的环境感知能力。在智能监控中,模型可基于该数据集实现精细的对象检测与跟踪,增强安防效率。此外,增强现实应用利用其场景解析结果,实现虚拟对象与真实环境的无缝融合,优化用户体验。
数据集最近研究
最新研究方向
在计算机视觉领域,ADE20K数据集作为场景解析与语义分割的重要基准,持续推动着前沿研究的发展。当前研究聚焦于提升模型在复杂场景下的细粒度理解能力,尤其是结合全景分割与实例分割的联合优化方法,以应对数据集中丰富的物体类别与层级结构。随着视觉Transformer架构的兴起,基于注意力机制的模型在该数据集上展现出卓越的性能,促进了开放词汇分割与零样本学习等热点方向的探索。这些进展不仅深化了对场景语义的理解,还为自动驾驶、增强现实等实际应用提供了坚实的技术支撑,彰显了该数据集在推动视觉智能进步中的核心价值。
以上内容由遇见数据集搜集并总结生成


