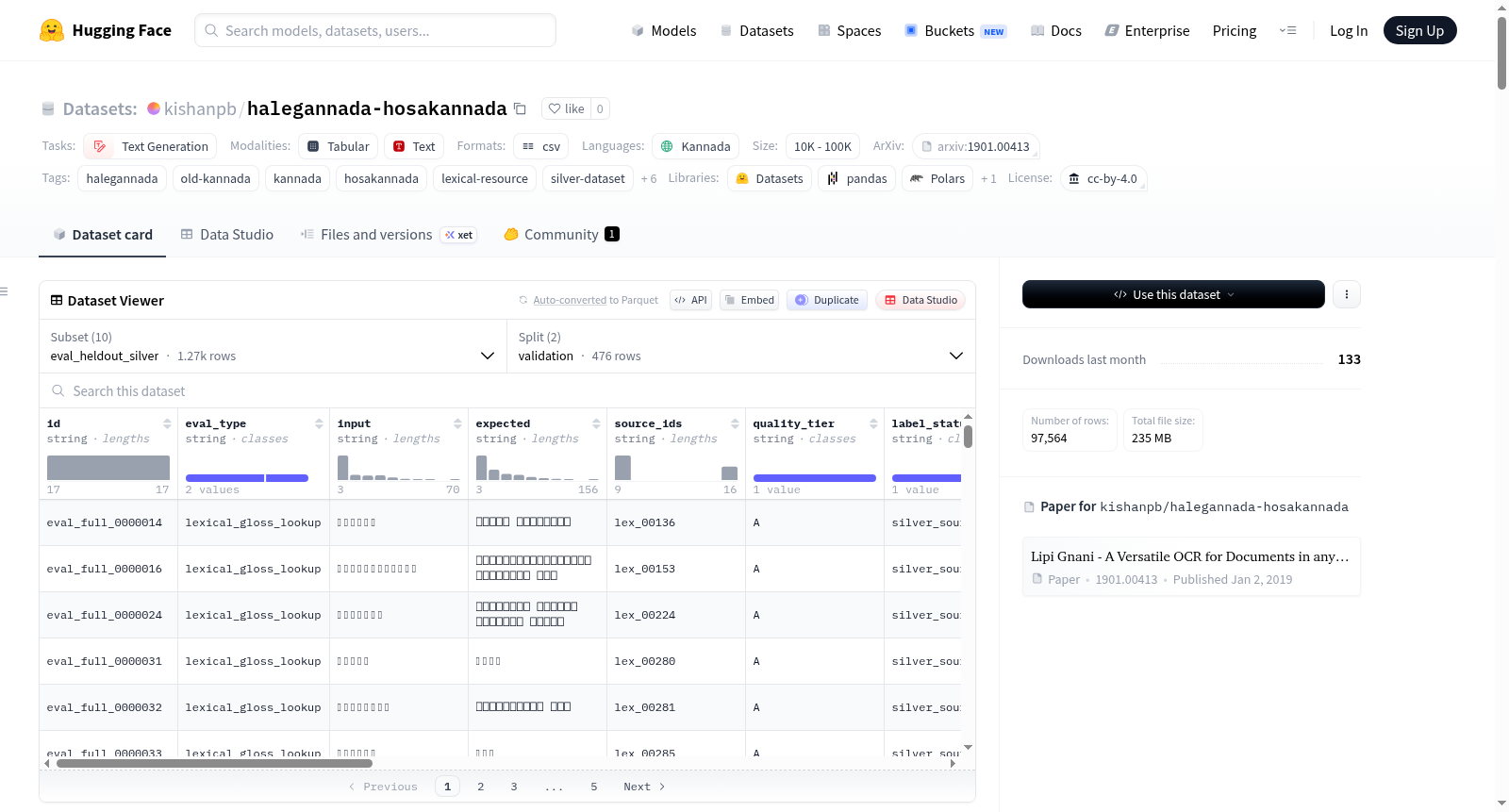
kishanpb/halegannada-hosakannada
收藏Hugging Face2026-05-01 更新2026-05-03 收录
下载链接:
https://hf-mirror.com/datasets/kishanpb/halegannada-hosakannada
下载链接
链接失效反馈官方服务:
资源简介:
Halegannada-Hosakannada数据集是一个专注于古卡纳达语(Halegannada/Old Kannada)到现代卡纳达语(Hosakannada/Modern Kannada)词汇现代化、源行注释、监督微调(SFT)和偏好训练的银标准语料库。数据集包含多种配置,如字典支持的词汇对、CHOCR衍生的源行段、模型就绪的SFT行、偏好对行和源独立的银评估行。数据集强调源支持的银标签,而非黄金标准翻译,适用于小型卡纳达语模型的微调、词汇现代化、源基础的诗行解释和偏好训练。数据集包含500行人工源质量审查样本,用于校准部分配置。主要数据来源包括Kaggle的Halegannada到Hosagannada词典和Internet Archive的CHOCR源段。数据集采用CC BY 4.0许可,但上游源权利需单独考虑。
The Halegannada-Hosakannada dataset is a silver-only corpus focused on lexical modernization from Halegannada/Old Kannada to Hosakannada/Modern Kannada, source-line glossing, supervised fine-tuning (SFT), and preference training. It includes various configurations such as dictionary-backed lexical pairs, CHOCR-derived source-line segments, model-ready SFT rows, preference-pair rows, and source-disjoint silver evaluation rows. The dataset emphasizes source-backed silver labels rather than gold-standard translations, making it suitable for fine-tuning small Kannada-capable models, lexical modernization, source-grounded poem/source-line explanation, and preference training. It includes a 500-row human source-quality review sample for calibrating certain configurations. Primary data sources include the Halegannada to Hosagannada Dictionary from Kaggle and CHOCR-derived source segments from the Internet Archive. The dataset is licensed under CC BY 4.0, but upstream source rights require separate consideration.
提供机构:
kishanpb
搜集汇总
数据集介绍
构建方式
该数据集的构建基于两大核心来源:Kaggle上的Halegannada至Hosakannada词典,以及Archive.org上通过CHOCR技术提取的古卡纳达语手稿源文本片段。研究团队首先从词典中抽取约25,088条词汇对,并利用CHOCR从160份档案文件中获取源文本行,结合词典提示进行注释。在此基础上,通过Adaptive Data by Adaption方法对数据进行迭代式检查与质量提升,生成了一系列用于指令微调、偏好训练的银标准数据集。为了校准数据质量,团队还完成了500行的人工源文本质量审查,并基于源ID追踪机制,筛选出与人工审查样本对应的校准子集,确保数据的可信度与实用性。
特点
该数据集以‘银标准’为核心标签策略,所有行均明确标注其标签来源类型(如词典支持、模型辅助或策略偏好),避免过度声称金标准准确性。其设计涵盖多样化配置,包括词汇对、源文本片段、偏好对等,满足从词汇现代化到模型偏好对齐的多层次需求。特别地,数据集保留了古卡纳达语中的稀有字符(如ಱ和ೞ),强制模型学习识别而非抹除历史形式。偏好对通过控制型负样本设计(如包含幻觉翻译或罕见形式消歧的错误答案),强化模型对源文本证据的依赖,提升鲁棒性。
使用方法
用户可通过Hugging Face的datasets库加载指定配置进行模型训练。例如,指令微调推荐使用`sft_training_silver_high_precision`配置,偏好训练首选`preference_pairs_hard_balanced_v2`,词汇查询可采用`lexical_pairs_silver`。每个配置均已预设训练、验证、测试划分,便于直接用于监督学习或DPO/ORPO算法。对于需要更高数据质量的场景,可优先使用含人工校准元数据的校准配置,如`sft_training_human_calibrated_source_quality`。使用时需注意数据集整体为银标准,不应作为金标准翻译基准,最终模型输出应经专业卡纳达语读者审阅后再用于文化或教育场景。
背景与挑战
背景概述
Halegannada-Hosakannada数据集由研究人员Kishan Panaganti与其父亲Badrinath Gopal于2026年合作创建,旨在为低资源语言——古卡纳达语(Halegannada)向现代卡纳达语(Hosakannada)的词汇现代化与语言处理提供核心资源。该数据集以银标准(Silver Dataset)形式发布,融合了词典词汇对、CHOCR源文本片段、监督微调(SFT)样本及偏好训练对,专为小规模卡纳达语模型设计,支持从古语词汇解析、源文注释到偏好训练(如DPO、ORPO)等多重任务。其独特之处在于强调源证据驱动的标签策略,并通过500行人工源质量审核校准数据,为低资源语言领域的自然语言处理研究提供了可靠的起始基准,对保护语言遗产与推动文化技术发展具有重要意义。
当前挑战
该数据集所面临的挑战首先源于其核心领域问题:古卡纳达语作为低资源语言,缺乏大规模、高质量的平行语料库,传统机器翻译和语言模型常面临词汇歧义、罕见字形(如ಱ和ೞ)丢失以及OCR错误导致的噪声干扰。构建过程中,研究者需应对CHOCR源文本质量不一、词典释义对上下文敏感、以及银标准标签无法替代专家验证的局限。此外,偏好标签依赖确定性策略而非人工判断,可能遗漏细微语义差异;人工审核仅覆盖源质量而非目标翻译正确性,限制了数据作为金标准基准的可靠性。这些挑战要求模型在训练中需保持对罕见形式的敏感性与抗噪声能力。
常用场景
经典使用场景
在低资源语言处理领域,尤其是面向达罗毗荼语系古老书面文本的现代化任务中,Halegannada-Hosakannada 数据集被广泛用于构建和微调小型卡纳达语模型。其核心应用场景包括古卡纳达语至现代卡纳达语的词汇现代化映射、基于原文来源的诗行与段落释义生成,以及结合词典证据与 OCR 产出进行受控的序列到序列转换。数据集提供的银标准标注与分场景配置,使其成为在缺乏大规模金标基准时,探索古典语言向现代形式迁移学习的理想实验平台。
衍生相关工作
基于该数据集衍生的经典工作包括:利用其高精度 SFT 配置训练的小型卡纳达语模型实现了低资源环境下的可控文本生成;基于硬平衡偏好对的 DPO 与 ORPO 训练策略被后续研究扩展至其他历史语言的现代化任务;人工校准源质量种子集为面向低资源语言的元评估提供了可追溯的审查标杆。此外,数据集中针对罕见字符与 OCR 伪影的显式保留方法,启发了一系列关于罕见字形感知的跨语言保真度评估工作,并推动了从银标准向金标迭代的半自动建设路径在民族语言非营利项目中的实际应用。
数据集最近研究
最新研究方向
该数据集聚焦于低资源语言卡纳达语的古代到现代词汇现代化任务,通过构建银标准语料库(silver corpus),融合词典支持的词汇对、CHOCR衍生的源文段、SFT与偏好训练数据,并结合人类源质量校准,为小规模模型微调、源文段解释及偏好训练提供支撑。其设计强调反幻觉、源文证据优先与罕见形式留存,呼应了低资源语言处理中数据稀缺与质量控制的紧迫挑战。该工作通过Adaptive Data by Adaption方法优化数据集设计,揭示了在资源受限条件下,精细化元数据、清晰标签策略与硬负样本平衡对于提升模型可解释性与鲁棒性的关键作用,为卡纳达语数字化保护与NLP资源建设树立了实用范式。
以上内容由遇见数据集搜集并总结生成


