prophet-mosque-library-compressed-cont
收藏Hugging Face2025-05-05 更新2025-05-06 收录
下载链接:
https://huggingface.co/datasets/ieasybooks-org/prophet-mosque-library-compressed-cont
下载链接
链接失效反馈官方服务:
资源简介:
Prophet's Mosque Library - Compressed - Continue数据集是从Prophet’s Mosque Library伊斯兰书籍资源中处理得到的。该数据集包含了超过48,000本经过Google Document AI APIs转换的PDF书籍,支持TXT和DOCX格式,涵盖70多个类别。这个数据集是原始数据集的延续,包含了因大小超过300GB而未能上传到原始仓库的PDF文件。
The Prophet's Mosque Library - Compressed - Continue dataset is curated from the Islamic book resources of the Prophet’s Mosque Library. This dataset includes over 48,000 PDF books converted via Google Document AI APIs, which are available in TXT and DOCX formats, and covers more than 70 categories. As a continuation of the original dataset, it contains the PDF files that failed to be uploaded to the original repository due to their total size exceeding 300GB.
创建时间:
2025-05-05
原始信息汇总
数据集概述:Prophets Mosque Library - Compressed - Continue
📜 数据集基本信息
- 许可证: MIT
- 任务类别: 图像到文本 (image-to-text)
- 语言: 阿拉伯语 (ar)
- 数据集名称: Prophets Mosque Library - Compressed - Continue
- 规模分类: 10K<n<100K
📂 数据集配置
- 配置名称: index
- 数据文件:
- 分割: index
- 路径: index.tsv
🌍 数据集背景
- 来源: Prophet’s Mosque Library 是伊斯兰书籍的主要资源之一,拥有超过48,000本PDF书籍,涵盖70多个类别。
- 处理方式: 使用Google Document AI APIs处理原始PDF文件,并将其内容提取为TXT和DOCX格式。
📦 数据集内容
- 内容描述: 该数据集包含原始数据集仓库中无法上传的剩余PDF文件(原始数据集大小超过300GB)。
- 原始数据集链接: https://huggingface.co/datasets/ieasybooks-org/prophet-mosque-library-compressed
搜集汇总
数据集介绍
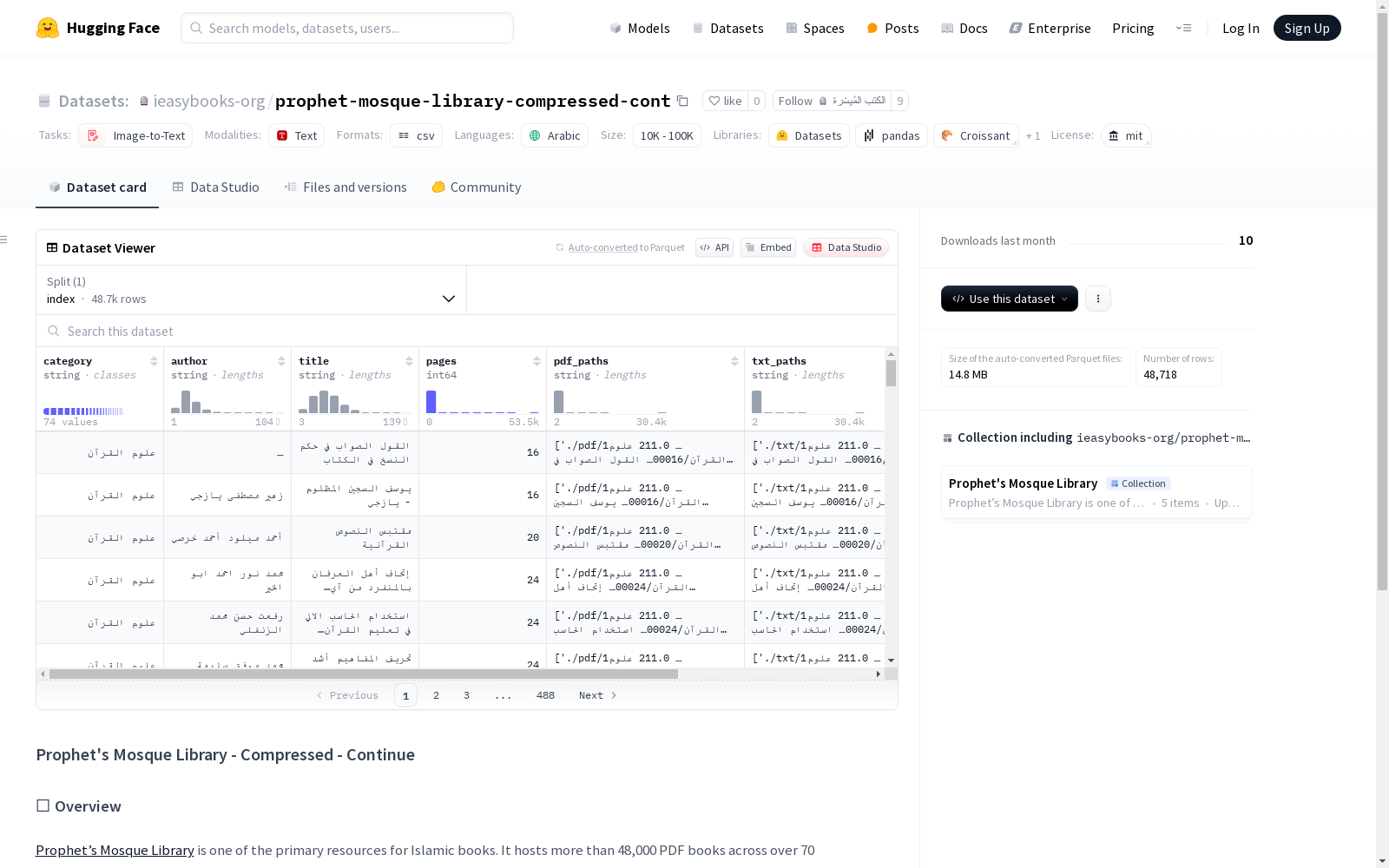
构建方式
该数据集源自先知清真寺图书馆的丰富伊斯兰文献资源,原始数据包含超过48,000册PDF格式的书籍,涵盖70余个学科类别。研究团队运用Google Document AI API对原始PDF文件进行智能化处理,将其内容提取为TXT和DOCX两种通用格式。由于原始数据体积超过300GB,本数据集专门收录了未能完整上传至初始仓库的剩余文献内容。
特点
作为伊斯兰学术文献的数字化代表,该数据集最显著的特点是涵盖领域专精且内容体量庞大。所有文本均经过标准化处理,支持阿拉伯语原典研究。多格式并存的特性为不同应用场景提供便利,TXT格式适合文本分析,DOCX格式则保留原始排版信息。数据集的压缩处理方案有效解决了海量宗教文献的存储与传输难题。
使用方法
研究者可通过索引文件快速定位目标文献,TSV格式的元数据表包含书籍的分册信息。对于文本挖掘任务,建议优先使用TXT格式的标准化文本;若需研究文献原始版式,DOCX文件能提供更完整的视觉信息。该数据集特别适合用于伊斯兰教义分析、阿拉伯语自然语言处理等学术领域,使用时需注意遵守MIT许可协议的相关规定。
背景与挑战
背景概述
先知清真寺图书馆数据集(Prophet's Mosque Library - Compressed - Continue)作为伊斯兰文献数字化工程的重要组成部分,由沙特阿拉伯政府主导的alharamain.gov.sa平台于近年推出,旨在系统性地收录与整理伊斯兰教经典文献。该数据集囊括超过48,000册PDF格式的宗教典籍,涵盖70余个学科门类,通过Google Document AI技术实现了文本内容的结构化提取,衍生出TXT与DOCX两种可计算形态。其核心价值在于为伊斯兰文化研究、阿拉伯语自然语言处理等跨学科领域提供了规模化的高质量语料,尤其对中东地区数字人文研究的推进具有里程碑意义。
当前挑战
该数据集构建过程中面临双重挑战:在领域问题层面,伊斯兰典籍特有的阿拉伯语古体变体、复杂书法字体以及跨世纪文本的语义演变,对OCR识别准确率与跨格式文本对齐提出了极高要求;技术实现层面,原始PDF文件总量超过300GB导致的存储瓶颈,迫使研究团队采用分布式压缩策略,且在文档结构解析时需克服阿拉伯语右向书写、连字符规则等特殊排版特性对自动化处理的干扰。这些挑战使得数据清洗与格式转换过程需要结合语言学规则与工程优化进行反复迭代。
常用场景
经典使用场景
在伊斯兰文献数字化研究领域,Prophet's Mosque Library数据集为学者提供了丰富的原始文本资源。该数据集通过将48,000余册阿拉伯语PDF书籍转化为可机读的TXT和DOCX格式,极大便利了文本挖掘与分析工作。研究人员可基于此开展古兰经注释比较、圣训文献分析等经典研究,探索伊斯兰学术传统的演变脉络。
衍生相关工作
该数据集已催生多项重要研究成果,包括基于注意力机制的阿拉伯古籍OCR系统、伊斯兰法律文本的知识抽取框架等。在跨宗教研究领域,学者利用其与基督教、犹太教典籍进行对比分析,探索亚伯拉罕宗教传统的文本互文性,推动了数字神学这一新兴学科的发展。
数据集最近研究
最新研究方向
在伊斯兰文献数字化领域,Prophet's Mosque Library数据集的最新研究聚焦于多模态文本分析与跨语言知识迁移。随着中东地区数字人文研究的兴起,该数据集作为全球规模最大的阿拉伯语伊斯兰文献资源之一,正被用于探索基于Transformer架构的古兰经注释自动生成、宗教文本语义相似度计算等前沿课题。研究者通过结合OCR优化技术与低资源语言处理方案,显著提升了阿拉伯语古籍的数字化准确率,这一进展直接推动了伊斯兰文化遗产的智能化保护进程。
以上内容由遇见数据集搜集并总结生成


