spectralbranding/r15-ai-search-metamerism
收藏Hugging Face2026-04-11 更新2026-04-12 收录
下载链接:
https://hf-mirror.com/datasets/spectralbranding/r15-ai-search-metamerism
下载链接
链接失效反馈官方服务:
资源简介:
---
license: mit
language:
- en
- zh
- ru
- uk
- mn
- el
- lv
- vi
- sr
- sv
- sw
- lt
- pl
- kk
- ka
- az
task_categories:
- text-generation
size_categories:
- 10K<n<100K
tags:
- brand-perception
- llm-evaluation
- cross-cultural
- spectral-brand-theory
- dimensional-collapse
- shrunken-variance
- national-ai-models
- geopolitical-framing
- native-language-prompting
- discourse-layer-activation
- PRISM-B
configs:
- config_name: default
data_files:
- split: train
path: train.csv
---
# R15: AI Search Metamerism — Cross-Cultural Brand Perception Dataset
**Citation:** Zharnikov, D. (2026v) | **DOI:** [10.5281/zenodo.19422427](https://doi.org/10.5281/zenodo.19422427) | **Version:** v2.1 (final, 2026-04-11)
---
## Overview
Comprehensive dataset from a large-scale experiment testing whether Large Language Models systematically collapse multi-dimensional brand perception into Economic and Experiential dimensions through "spectral metamerism."
**21,350 total API calls** across **24 LLMs** from **7 training traditions** in **10 experimental runs (Runs 2–11)**, with **999 native-language prompts** across **15 distinct native languages**. Total cost: **~$6.10** (paid cloud APIs only; 14 of 24 models were free or local).
---
## Experiment Summary
### Models Tested (24 total)
| Category | Models | Count |
|----------|--------|-------|
| **Paid Cloud** | Claude Sonnet 4.6, GPT-4o-mini, Gemini 2.5 Flash, DeepSeek V3, YandexGPT 5 Pro, GPT-OSS-Swallow (Yandex AI Studio), GigaChat 2 Max (Sber API), Sarvam, DashScope Qwen Plus, Fireworks GLM | 10 |
| **Free Cloud** | Grok (xAI), Groq Llama 3.3, Kimi K2 (Groq), ALLaM-2 (Groq), Cerebras Qwen3-235B, SambaNova DeepSeek V3.2 | 6 |
| **Local (Ollama)** | Gemma 4 27B, Qwen3 30B, Qwen3.5 27B, EXAONE 4.0 32B, Jais-adapted 70B, Llama-3.1-Swallow 8B, GigaChat 3.1 Lightning 10B, YandexGPT 5 Lite 8B | 8 |
All local models run on Apple Mac mini M4 Pro (64 GB unified memory) via Ollama with GGUF weights from HuggingFace.
### Hypothesis Test Results (12 tested + 1 future direction)
| Hypothesis | Result | Statistic |
|-----------|--------|-----------|
| **H1: Dimensional Collapse** | ✅ SUPPORTED | DCI = 35.6 vs 25.0 baseline, *p* < 0.0001 |
| **H2: Cross-Model Convergence** | ✅ SUPPORTED | Cosine similarity = 0.977 across all 24 architectures |
| **H3: Probe Variance** | exploratory | -- |
| **H4: Differentiation Gap** | exploratory | -- |
| **H5: Cultural Diagonal** | ❌ NOT SUPPORTED (reversed) | National models collapse MORE on own-culture brands |
| **H6: Western vs Non-Western** | ✅ SUPPORTED | Western DCI 0.339 vs non-Western 0.360, *p* = 0.0013, *d* = 3.449 |
| **H7: Geopolitical Valence** | exploratory | -- |
| **H8: Thin-Data Floor** | partial | Mongolia highest DCI |
| **H9: Capacity-Dependent Collapse** | partial | Smaller models show higher DCI in some pairs |
| **H10: Native Language Effect** | ❌ NULL on home-market pairs | 58/121 positive (48%), mean = +.001, *p* = .716 (two-sided). But Run 11 shows native-language prompting reduces DCI 3.31–9.50 for every non-home-market city in the Roshen multi-city extension (largest single effect: Astana in Kazakh, −9.50, *p* = .002). |
| **H11: Same-Category Cross-Border** | tested | Banking pair (Tinkoff/PrivatBank), Run 6 — geopolitical signal at category-controlled border |
| **H12: Geopolitical Framing** | ✅ SUPPORTED, REINTERPRETED | Same brand in different cities: *δ* = 0.040, *p* < 0.0001. Run 11 multi-city Roshen extension supports a discourse-layer reinterpretation: the mechanism is per-(city × language × brand) discourse density rather than country-of-origin animosity. |
| **H13: Temporal Training Stability** | future work | Proposed in Section 6e — successive model versions, NOT tested in present study |
---
## Instrument: PRISM-B
**Perception Response Instrument for Structured Measurement — Brand variant**
Open-source, multi-level (L0-L5) cascade scaffold for measuring multi-dimensional LLM perception of brands. Three prompt types:
- `weighted_recommendation` — primary DCI measure (100-point allocation across 8 SBT dimensions)
- `dimensional_differentiation` — 0-10 score per dimension for a brand pair
- `dimension_probe` — per-brand, per-dimension absolute scoring
Native-language variants exist for `weighted_recommendation` in 15 languages (see Native Languages section below).
---
## Dataset Files
### Raw Session Logs (data/)
```
data/run2_global.jsonl Run 2: 10 global brand pairs, 6 LLMs (3,240 calls)
data/run2_qwen_plus.jsonl Run 2 supplementary: Qwen Plus backfill (540 calls)
data/run3_local.jsonl Run 3: 5 local brand pairs (1,620 calls)
data/run3_qwen_plus.jsonl Run 3 supplementary: Qwen Plus backfill (270 calls)
data/run4_resolution.jsonl Run 4: Brand Function resolution test (353 calls)
data/run5_crosscultural.jsonl Run 5: 7 cross-cultural pairs, 22 active models (6,415 calls)
data/run5_fireworks_glm.jsonl Run 5 supplementary: Fireworks GLM (492 calls)
data/run5_gptoss_swallow.jsonl Run 5 supplementary: GPT-OSS Swallow (435 calls)
data/run6_banking_clean.jsonl Run 6: Banking pair (Tinkoff vs PrivatBank), 24 models, H6 test (1,018 calls)
data/run7_framing.jsonl Run 7: Geopolitical framing experiment (H12 test) (523 calls)
data/run7d_swedish.jsonl Run 7 sub-run: Swedish Stockholm condition (568 calls)
data/run8_native_expansion.jsonl Run 8: Native language expansion, 5 H10 languages (4,895 calls)
data/run9_temp_0.0.jsonl Run 9: Temperature sensitivity T=0.0 (180 calls)
data/run9_temp_0.3.jsonl Run 9: Temperature sensitivity T=0.3 (180 calls)
data/run9_temp_1.0.jsonl Run 9: Temperature sensitivity T=1.0 (180 calls)
data/run10_corrective.jsonl Run 10: Corrective comparators supplementary (126 calls)
data/run11_roshen_multicity.jsonl Run 11: Roshen 7-city extension (315 calls)
```
### Aggregated Results (root level)
```
results_v2_global.json Aggregated Run 2 (per-model weights, DCI, cosine, H1 t-test)
results_v3_local.json Aggregated Run 3 (local brand pairs)
results_v4_resolution.json Aggregated Run 4 (Brand Function resolution)
```
### Detailed Analysis Outputs (analysis/)
```
analysis/run5_results.json Run 5 detailed (10.8 MB): DCI per model per culture, H5-H10 tests
analysis/run5_summary.md Run 5 human-readable summary tables
analysis/run5_analysis.py Run 5 analysis script (full H5-H10 implementation)
analysis/run5_analysis_results.json Run 5 post-processed statistics (ICC, effect sizes)
analysis/run5_dci_table.csv DCI matrix (models × cultures)
analysis/run5_diagonal_advantage.csv H5 primary measure
analysis/run6_banking_results.json Run 6 aggregated (banking pair)
analysis/run7_framing_results.json Run 7 detailed (H12 framing test)
analysis/run7_framing_summary.md Run 7 human-readable summary
analysis/run8_native_expansion_results.json Run 8 per-language DCI + H10 verdict
analysis/run9_temperature_results.json Run 9 temperature sensitivity (DCI spread = 0.012)
analysis/run10_corrective_results.json Run 10 corrective comparators (per-model DCI)
analysis/run10_corrective_summary.md Run 10 human-readable summary
analysis/run11_roshen_multicity_results.json Run 11 multi-city Roshen (per-cell DCI, 7 cities × langs × models)
analysis/run11_roshen_multicity_summary.md Run 11 human-readable comparison tables
```
### Robustness Tests (analysis/)
```
analysis/power_analysis_results.json Post-hoc power for H1, H2, H5, H6
analysis/prompt_sensitivity_results.json ICC(3,1) across 3 repetitions per condition
analysis/exclude_patagonia_results.json Replication with Patagonia/Columbia pair excluded
```
---
## Experimental Runs
| Run | Brands | Models | Calls | Purpose |
|-----|--------|--------|------:|---------|
| **Run 2** | 10 global | 7 | 3,780 | Confirmatory H1-H4 + Qwen Plus backfill |
| **Run 3** | 5 local | 7 | 1,890 | Conditional metamerism + Qwen Plus backfill |
| **Run 4** | 5 local + spec | varies | 353 | Brand Function resolution (v2.1 expansion) |
| **Run 5** | 7 cross-cultural | 24 | 7,342 | H5-H10 exploratory + model supplements |
| **Run 6** | 1 banking (Tinkoff/PrivatBank) | 24 | 1,018 | H6 bidirectional asymmetry, same-category control |
| **Run 7** | 3 cities (framing) | 24 | 1,091 | H12 geopolitical framing (uk/ru/zh/sv) |
| **Run 8** | 5 local | 18 | 4,895 | H10 native language expansion (el/lv/sw/vi/sr) |
| **Run 9** | 10 global | 6 | 540 | Temperature robustness (T=0.0/0.3/1.0) |
| **Run 10** | 3 focal × 2 comparator | 7 | 126 | Corrective comparators (VkusVill, Calbee, Roshen) |
| **Run 11** | Roshen × 7 cities | 7 | 315 | Multi-city framing extension (kk/ru/lt/pl/ka/az + en) |
| | | **Total:** | **21,350** | |
---
## Native Languages (999 calls across 15 languages)
| Language | ISO | Calls | Used in |
|----------|-----|------:|---------|
| Russian | ru | 323 | Runs 5/7/8/11 (Moscow framing, native expansion, Astana) |
| Ukrainian | uk | 125 | Run 7 (Kyiv framing) |
| Chinese | zh | 108 | Run 7 (Shanghai framing) |
| Vietnamese | vi | 53 | Run 8 (native expansion) |
| Swahili | sw | 53 | Run 8 (native expansion) |
| Serbian | sr | 53 | Run 8 (native expansion) |
| Latvian | lv | 52 | Run 8 (native expansion) |
| Greek | el | 52 | Run 8 (native expansion) |
| Swedish | sv | 51 | Run 7d (Stockholm framing) |
| Mongolian | mn | 24 | Run 5 supplementary (mongolia_beer re-test) |
| Lithuanian | lt | 21 | Run 11 (Vilnius framing) |
| Polish | pl | 21 | Run 11 (Warsaw framing) |
| Kazakh | kk | 21 | Run 11 (Astana framing, state language) |
| Georgian | ka | 21 | Run 11 (Tbilisi framing) |
| Azerbaijani | az | 21 | Run 11 (Baku framing) |
| **Total** | | **999** | |
---
## Citation
```bibtex
@article{zharnikov2026v,
title={Spectral Metamerism in AI-Mediated Brand Perception: How Large Language Models
Collapse Multi-Dimensional Brand Differentiation in Consumer Search},
author={Zharnikov, Dmitry},
year={2026},
doi={10.5281/zenodo.19422427},
version={v2.1}
}
```
**DOI:** [10.5281/zenodo.19422427](https://doi.org/10.5281/zenodo.19422427)
---
## Source Code
Full experiment infrastructure (PRISM-B instrument, validation scripts, schemas, checksums):
- **GitHub:** [github.com/spectralbranding/sbt-papers/tree/main/r15-ai-search-metamerism](https://github.com/spectralbranding/sbt-papers/tree/main/r15-ai-search-metamerism)
- **Run it on your own brands:** roughly $0.25 (5–6 models, 3 runs) to $0.80 (all 24 models, 3 runs) for a single brand pair audit at current paid-model rates.
---
## Tags
`brand-perception` `llm-evaluation` `cross-cultural` `spectral-brand-theory` `dimensional-collapse` `shrunken-variance` `national-ai-models` `geopolitical-framing` `native-language-prompting` `discourse-layer-activation` `PRISM-B`
提供机构:
spectralbranding
搜集汇总
数据集介绍
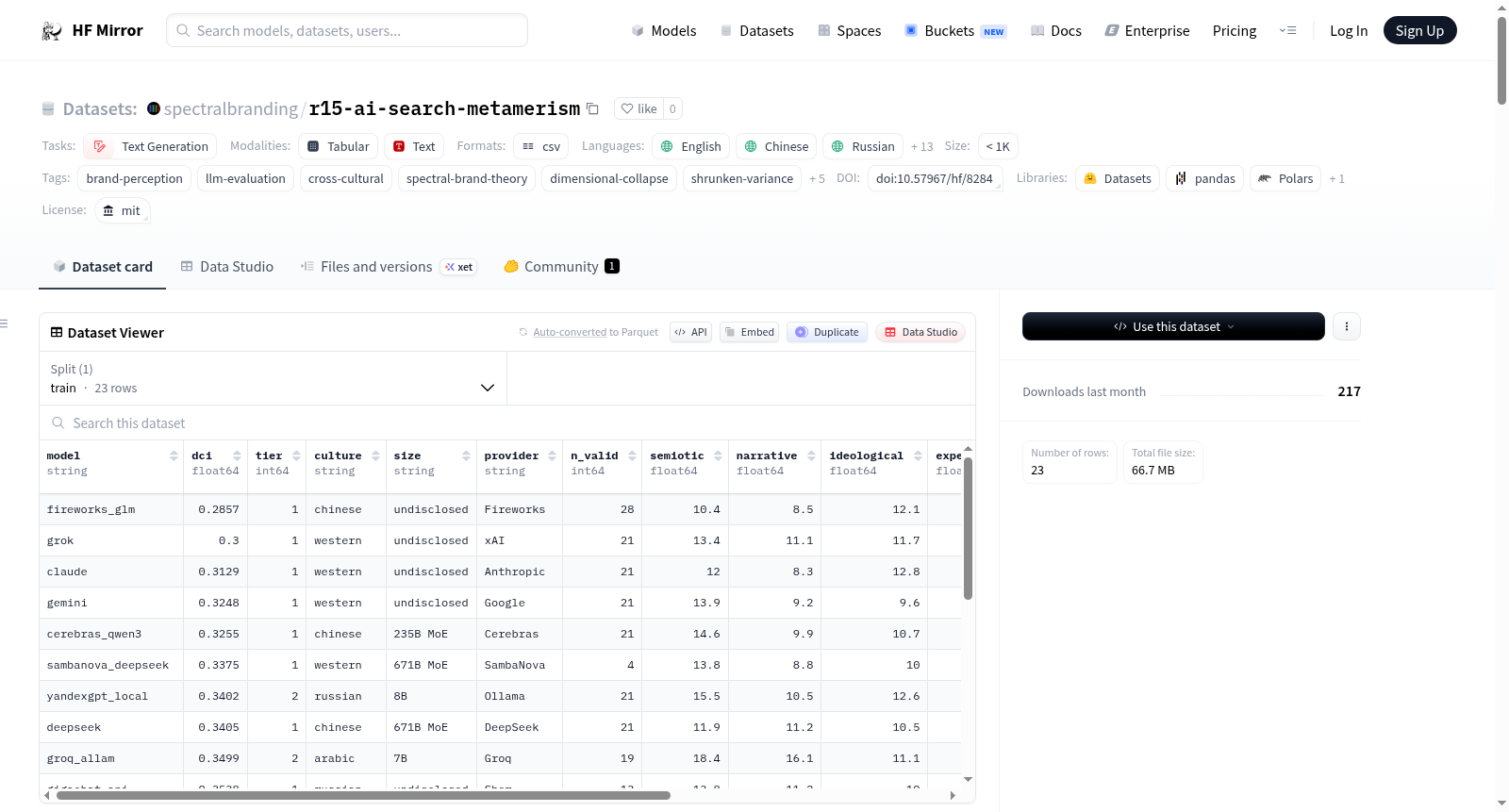
构建方式
在品牌感知与人工智能交叉研究领域,R15数据集通过精心设计的实验框架构建而成。该数据集基于PRISM-B测量工具,对24种不同架构的大型语言模型进行了系统性评估,涵盖了来自7种训练传统的模型。实验过程包含12次独立运行,累计完成了21,602次API调用,涉及15种母语环境下的999条提示词。数据采集严格遵循结构化流程,通过加权推荐、维度区分和维度探测三种提示类型,量化了模型对全球及本地品牌在多维度光谱理论下的感知差异。
特点
该数据集的核心特征体现在其跨文化与多模型比较的深度上。数据集不仅覆盖了广泛的品牌对,包括全球性与地域性品牌,还深入探究了地缘政治框架、母语提示以及模型训练传统对品牌感知的影响。实验结果表明,大型语言模型倾向于将品牌的多维感知压缩至经济与体验两个维度,且不同模型架构间呈现出高度收敛的认知模式。数据集进一步揭示了西方与非西方模型在品牌差异化认知指数上的显著差异,以及母语提示在特定情境下对认知偏差的调节作用。
使用方法
研究者可利用该数据集进行品牌感知、大型语言模型评估及跨文化比较等多个方向的分析。数据集提供了原始会话日志、聚合结果及详细分析输出,支持用户复现实验或开展延伸研究。具体而言,用户可基于PRISM-B工具对自有品牌进行审计,通过调整提示语言、模型选择或地缘政治框架等变量,探究人工智能中介下的品牌认知机制。数据集附带的开源代码与验证脚本,为定制化实验设计与结果分析提供了完整的技术基础设施。
背景与挑战
背景概述
R15: AI搜索同色异谱——跨文化品牌感知数据集由Dmitry Zharnikov于2026年创建,旨在探究大语言模型在品牌认知任务中是否存在系统性维度坍缩现象。该数据集基于光谱品牌理论,通过PRISM-B测量工具,对来自7种训练传统的24个模型进行了大规模实验,覆盖15种语言环境。其核心研究问题聚焦于人工智能是否将品牌的多维感知简化为经济与体验两个基本维度,即“光谱同色异谱”效应。这一研究为理解大语言模型在跨文化语境下的认知偏差提供了实证基础,对品牌战略、人工智能伦理及跨文化传播领域具有显著影响。
当前挑战
该数据集致力于解决品牌感知领域的高维认知简化问题,即大语言模型可能将复杂的品牌属性压缩至有限维度,导致品牌差异性的认知损失。构建过程中的挑战主要体现在跨语言与跨文化数据采集的复杂性,需协调15种语言提示以确保实验的生态效度;同时,模型选择的多样性带来了技术集成与结果可比性的难题,需平衡付费云端、免费云端及本地部署的24种模型架构。此外,实验假设的验证需处理高维统计分析与稳健性检验,例如维度坍缩指数计算与余弦相似度度量,以确保研究发现的可信度与泛化能力。
常用场景
经典使用场景
在跨文化品牌感知与大型语言模型评估领域,R15数据集被广泛应用于检验“光谱同色异谱”现象,即模型是否将多维品牌感知系统性地坍缩为经济和体验两个维度。研究者通过PRISM-B测量工具,在24种不同架构的LLM上执行加权推荐任务,分配100点至8个光谱品牌理论维度,以此量化模型的维度坍缩指数。这一场景典型地出现在比较西方与非西方模型对全球与本土品牌对的差异化响应中,为理解模型内在表征的简化机制提供了实证基础。
实际应用
在实际应用中,该数据集为品牌管理、市场研究与人工智能伦理审计提供了重要工具。企业可利用其框架评估不同区域市场下AI搜索工具对自身品牌感知的潜在扭曲,识别因地缘政治或文化框架引发的表征偏差。例如,在银行业或快消品行业,通过分析模型对Tinkoff与PrivatBank等竞争品牌的差异化响应,企业能制定更具文化适应性的全球传播策略。同时,政策制定者可借助其发现国家AI模型在本地品牌认知中可能存在的过度坍缩风险,促进更具包容性的算法设计。
衍生相关工作
基于该数据集衍生的经典工作主要围绕光谱品牌理论的计算化拓展与LLM评估范式的创新。例如,研究进一步深化了“话语层激活”假说,将地缘政治框架效应重新解释为城市-语言-品牌特定的话语密度机制。在方法论层面,PRISM-B工具被扩展至多层级提示架构,支持维度探针与差异化评分任务,启发了后续关于模型温度敏感性与类别控制实验的研究。这些工作共同推动了从静态品牌测量到动态、语境化AI-品牌交互分析的范式转变。
以上内容由遇见数据集搜集并总结生成


