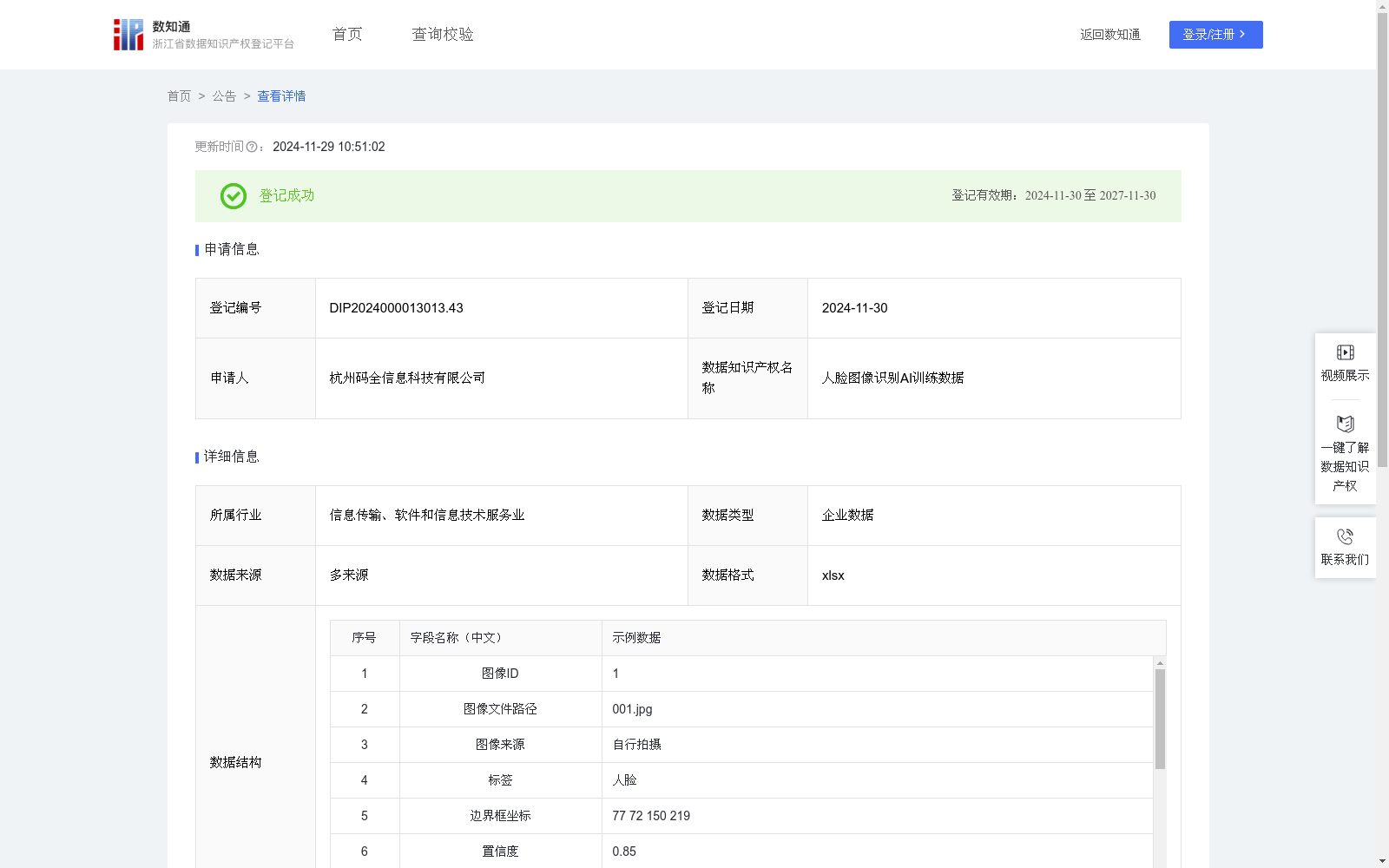
人脸图像识别AI训练数据
收藏浙江省数据知识产权登记平台2024-11-29 更新2024-11-30 收录
下载链接:
https://www.zjip.org.cn/home/announce/trends/91212
下载链接
链接失效反馈官方服务:
资源简介:
人脸图像识别AI训练数据主要应用于提升AI模型在实际场景中对人脸的识别能力和识别准确度。通过这些数据的训练,AI模型可以更准确地识别不同个体的面部特征,从而胜任在身份验证、安全监控、社交媒体分析等领域的应用。此外,超参数的应用进一步提升了模型的泛化能力和鲁棒性,使得AI模型在处理不同光照、角度和表情条件下的人脸图像时,具有更好的泛化能力和适应性。步骤1,原始图像数据来源于公开图像数据库、自行拍摄或其他算法生成。在此步骤中,记录每张图像的图像ID和图像文件路径。
步骤2,根据自身项目需求和模型要求,将人脸图像数据分类成数据集类型,分为训练集和测试集。对训练集图像进行标注,包括标签和边界框坐标。
步骤3,选择适合人脸图像识别的YOLO预训练模型,并初始化模型参数。设置合理的超参数,如学习率、批量大小等,以优化模型的训练过程。记录所使用的模型名称和这些超参数。
步骤4,使用PyTorch深度学习框架加载和初始化模型。将准备好的数据集输入到模型中进行训练。在训练过程中,模型会不断调整权重,以最小化预测框与真实框之间的差值。记录训练的训练时长和训练周期(迭代次数)。训练过程中,模型的置信度将逐渐提升。
步骤5,在训练完成后,使用测试集对模型进行评估。计算模型在不同场景下的精度、召回率、F1分数、以及实时性能评估等性能指标,确保模型的准确性和鲁棒性。
步骤6,将最终训练、测试后得到的模型应用到具体的项目中。在实际应用中,评估模型的实时性能,包括检测的准确性和处理速度,确保满足项目需求。记录模型在实际应用中的实时性能评估。
The AI training data for facial image recognition is primarily used to enhance the facial recognition capability and accuracy of AI models in real-world scenarios. Trained with this data, AI models can more accurately recognize facial features of different individuals, enabling them to be applied in scenarios such as identity verification, security monitoring, and social media analysis. Furthermore, the application of hyperparameters further improves the generalization ability and robustness of the model, enabling the AI model to achieve better generalization and adaptability when processing facial images under varying lighting, angles, and expressions.
Step 1: The original image data is sourced from public image databases, self-shot photography, or generated by other algorithms. During this step, the image ID and file path of each image are recorded.
Step 2: Classify the facial image data into dataset types, namely training set and test set, based on project requirements and model specifications. Annotate the images in the training set, including labels and bounding box coordinates.
Step 3: Select a pre-trained YOLO model suitable for facial image recognition and initialize its model parameters. Set appropriate hyperparameters such as learning rate, batch size, etc., to optimize the model training process. Record the name of the used model and these hyperparameters.
Step 4: Load and initialize the model using the PyTorch deep learning framework. Input the prepared dataset into the model for training. During the training process, the model will continuously adjust weights to minimize the difference between predicted bounding boxes and ground-truth bounding boxes. Record the training duration and training epochs (number of iterations). The model's confidence score will gradually improve throughout the training process.
Step 5: After the training is completed, evaluate the model using the test set. Calculate performance metrics such as precision, recall, F1-score, and real-time performance evaluation under different scenarios to ensure the model's accuracy and robustness.
Step 6: Apply the final model obtained after training and testing to specific projects. In practical applications, evaluate the model's real-time performance, including detection accuracy and processing speed, to ensure it meets project requirements. Record the real-time performance evaluation of the model in practical applications.
提供机构:
杭州码全信息科技有限公司
创建时间:
2024-11-11
搜集汇总
数据集介绍
特点
该数据集包含4760条人脸图像数据,主要用于提升AI模型在人脸识别任务中的准确性和泛化能力,适用于身份验证、安全监控等场景。数据格式为xlsx,包含图像ID、文件路径、标签、边界框坐标等字段,并记录了训练过程中的超参数和性能指标。
以上内容由遇见数据集搜集并总结生成


