sango-vocabulary
收藏Hugging Face2026-04-09 更新2026-04-10 收录
下载链接:
https://huggingface.co/datasets/MEYNG/sango-vocabulary
下载链接
链接失效反馈官方服务:
资源简介:
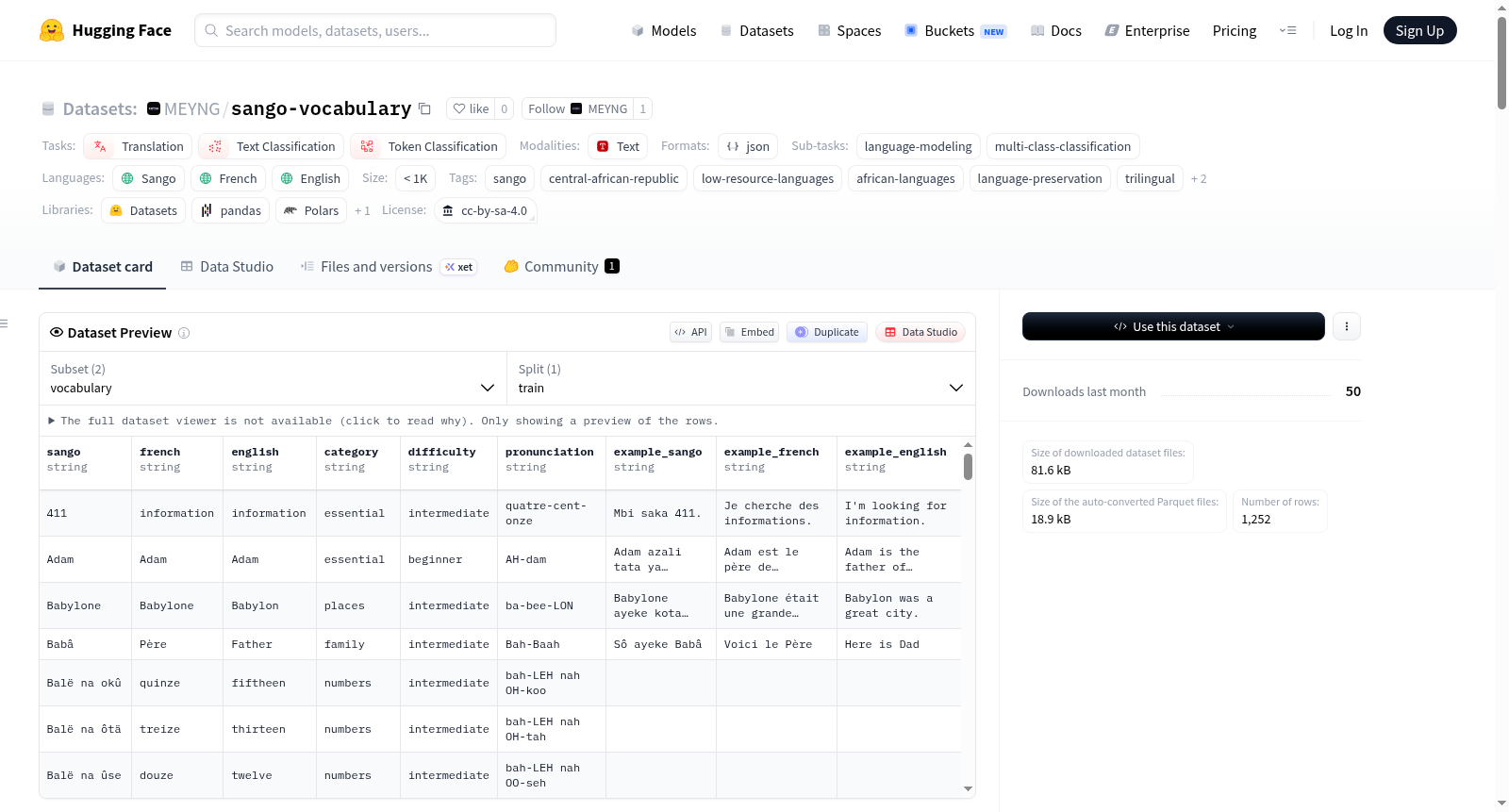
Sango词汇数据集是首个结构化的数字词汇数据集,专注于中非共和国的官方和最广泛使用的语言——Sango语(ISO 639-1: `sg`, ISO 639-3: `sag`)。Sango语是一种拥有超过500万使用者的克里奥尔语,但在NLP研究和数字资源中代表性严重不足。该数据集提供了三语(Sango-法语-英语)词汇条目,包含发音指南和语义分类,以及从语法和词典参考资料中提取的Sango-法语翻译对。数据集包含431个三语词汇条目和360个Sango-法语翻译对,适用于机器翻译、语言建模、跨语言迁移、语言文档和教育技术等任务。词汇条目涵盖25个语义类别,并按学习难度分为初级、中级和高级。数据集创建过程中,词汇条目由熟悉Sango语的语言学家和母语者进行结构化和分类,发音指南使用为学习者设计的英语近似音标系统。数据集已知的局限性包括规模较小、翻译对质量不一、例句覆盖不足、方言覆盖有限以及发音指南的适用性。建议将其作为种子数据集,结合SangoAI API使用,并在微调前对翻译对进行质量过滤。
The Sango Lexical Dataset is the first structured digital lexical dataset focused on Sango, the official and most widely spoken language of the Central African Republic (ISO 639-1: `sg`, ISO 639-3: `sag`). Sango is a creole language with over 5 million speakers, yet it is severely underrepresented in NLP research and digital resources. This dataset provides trilingual (Sango-French-English) lexical entries, including pronunciation guides and semantic categories, as well as Sango-French translation pairs extracted from grammatical and lexicographical reference materials. The dataset contains 431 trilingual lexical entries and 360 Sango-French translation pairs, and is applicable to tasks such as machine translation, language modeling, cross-lingual transfer, language documentation, and educational technology. The lexical entries cover 25 semantic categories and are divided into beginner, intermediate, and advanced levels based on learning difficulty. During the dataset creation process, lexical entries were structured and categorized by linguists familiar with Sango and native speakers, and the pronunciation guides use an English approximate phonetic transcription system designed for language learners. The known limitations of the dataset include its small scale, inconsistent quality of translation pairs, insufficient coverage of example sentences, limited dialect coverage, and the applicability of the pronunciation guides. It is recommended to use it as a seed dataset in conjunction with the SangoAI API, and perform quality filtering on translation pairs before fine-tuning.
创建时间:
2026-04-02
原始信息汇总
Sango Vocabulary Dataset 数据集概述
数据集基本信息
- 数据集名称:Sango Vocabulary Dataset
- 发布者/作者:MEYNG
- 发布日期/年份:2026
- 许可证:Creative Commons Attribution-ShareAlike 4.0 International License (CC-BY-SA-4.0)
- 数据集规模:小规模 (n<1K)
- 语言:桑戈语 (sg/sag)、法语 (fr/fra)、英语 (en/eng)
- 任务类别:翻译、文本分类、词元分类、语言建模
- 标签:sango, central-african-republic, low-resource-languages, african-languages, language-preservation, trilingual, vocabulary, dictionary
数据集描述
这是首个为桑戈语(中非共和国国语及使用最广泛的语言)构建的结构化数字词汇数据集。桑戈语是一种克里奥尔语,拥有超过500万使用者,但在NLP研究和数字资源中代表性严重不足。该数据集提供三语(桑戈语-法语-英语)词汇条目(含发音指南和语义分类)以及从语法和词典参考资料中提取的桑戈语-法语翻译对。
数据集结构
数据集包含两个配置:
-
词汇 (
vocabulary.jsonl)- 包含431个三语词汇条目。
- 每个条目包含以下字段:
sango:桑戈语单词或短语french:法语翻译english:英语翻译category:语义/语法类别difficulty:学习难度等级pronunciation:语音发音指南example_sango:桑戈语例句example_french:法语例句example_english:英语例句
- 例句字段 (
example_sango,example_french,example_english) 覆盖率低于1%。
-
训练对 (
training_pairs.jsonl)- 包含360个从语法和词典参考资料中提取的桑戈语-法语翻译对。
- 每个条目包含以下字段:
source_lang:源语言代码 (sg或fr)target_lang:目标语言代码 (sg或fr)source:源文本target:目标文本
类别分布
词汇涵盖25个语义类别,主要类别包括:
- nature (30), professions (30), clothing (25), commerce (25), education (25), health (25), home (25), adjectives (20), numbers (20), technology (20), transport (20), verbs (18), animals (15), emotions (15), greetings (15), body (10), colors (10), essential (10), actions (10), food (12), family (12), places (12), time (10), weather (10), questions (7)。
难度分布
- Beginner (初级): 210 (48.7%)
- Intermediate (中级): 200 (46.4%)
- Advanced (高级): 21 (4.9%)
支持的任务
- 机器翻译(桑戈语-法语、桑戈语-英语)
- 语言建模(针对桑戈语的预训练或微调)
- 跨语言迁移(利用法语/英语表征进行桑戈语NLP)
- 语言记录(桑戈语词汇和使用模式的数字保存)
- 教育技术(构建桑戈语学习应用)
数据来源与创建
- 词汇条目:由MEYNG从桑戈语学习资源(包括japprendslesango.com)和经过验证的桑戈语词汇参考资料中整理。
- 训练对:从一本全面的桑戈语语法和词典参考著作中提取。
- 验证:根据已知的桑戈语语言学来源对条目进行了审查。
- 标注过程:词汇条目由熟悉桑戈语的母语者和语言学家进行结构化和分类。发音指南使用为学习者设计的英语近似音标系统。
使用注意事项与已知限制
- 数据集规模小:包含431个词汇条目和360个翻译对,按现代NLP标准属于小数据集。最适合作为种子数据集、评估集或用于少样本学习场景。
- 训练对质量:翻译对中包含一些来自源材料的碎片化文本。对于需要干净平行数据的任务,建议进行过滤。
- 例句覆盖不足:仅1个词汇条目包含例句。
- 方言覆盖:桑戈语存在地区变体。本数据集主要代表班吉(首都)使用的标准化桑戈语。
- 发音指南:语音指南使用英语音标来近似桑戈语发音,旨在服务学习者,而非用于音系学研究。
使用建议
- 作为种子数据集用于引导桑戈语NLP系统。
- 可与SangoAI API(在
https://sangoai.sbs提供643+单词)结合以获得更大的词汇量。 - 在微调前对
training_pairs.jsonl应用质量过滤。 - 考虑在下游任务中使用数据增强技术。
引用信息
如果使用本数据集,请引用: bibtex @dataset{meyng_sango_vocabulary_2026, title={Sango Vocabulary Dataset: A Trilingual Lexical Resource for an Underrepresented African Language}, author={MEYNG}, year={2026}, url={https://huggingface.co/datasets/meyng/sango-vocabulary}, license={CC-BY-SA-4.0}, language={sg, fr, en} }
致谢与联系
- 项目:本数据集由 MEYNG 作为 SangoAI 项目的一部分创建,该项目是一个致力于桑戈语保存和数字化的AI驱动语言平台。
- 联系方式:
- 组织:MEYNG
- 网站:https://meyng.com
- 平台:https://sangoai.sbs
- 邮箱:contact@meyng.com
- GitHub:https://github.com/meyng-hub/sangoai
搜集汇总
数据集介绍
构建方式
在语言资源稀缺的背景下,Sango词汇数据集的构建体现了对中非共和国官方语言桑戈语的系统性数字化保存。该数据集的核心词汇条目来源于权威的桑戈语学习资源,如japprendslesango.com,并经由熟悉桑戈语的语言学家与母语者进行结构化整理与语义分类。同时,训练对数据从一部详尽的桑戈语语法与词典参考著作中提取,形成了桑戈语与法语之间的平行翻译语料。整个构建过程注重来源的可靠性与标注的准确性,旨在为低资源语言研究提供一个高质量的基准资源。
特点
作为首个结构化的桑戈语数字词汇数据集,其显著特点在于提供了完整的三语(桑戈语-法语-英语)对照条目,并辅以发音指南与语义分类。数据集涵盖431个词汇条目,分布于25个语义类别,并标注了初级、中级、高级三种学习难度等级,为语言教育与技术应用提供了细致维度。此外,数据集包含360个桑戈语-法语翻译对,尽管部分条目存在文本碎片化现象,但仍为机器翻译等任务提供了宝贵的平行语料。这些特征共同构成了一个面向语言保存、研究与教育的多功能资源。
使用方法
该数据集主要服务于自然语言处理与语言技术领域。研究者可将其用于桑戈语的机器翻译模型训练、语言模型预训练或微调,以及跨语言迁移学习实验。鉴于其规模,数据集更适合作为种子数据集、评估集或用于少样本学习场景。在使用训练对数据时,建议根据下游任务需求进行质量过滤以获得更干净的平行句对。同时,数据集可与SangoAI项目提供的扩展词汇资源结合使用,并鼓励采用数据增强技术以提升下游任务性能。
背景与挑战
背景概述
在计算语言学和低资源语言技术领域,对非洲语言的数字化保存与自然语言处理研究长期面临资源匮乏的困境。Sango Vocabulary Dataset 由 MEYNG 机构于 2026 年创建,旨在为中非共和国的官方语言——桑戈语(Sango)提供首个结构化的多语种词汇数据集。该数据集聚焦于解决桑戈语在机器翻译、语言建模及跨语言迁移任务中数据稀缺的核心问题,通过整合桑戈语、法语和英语的三语对照词条,为语言技术研究提供了珍贵的种子资源,对推动非洲低资源语言的数字复兴与学术探索具有开创性意义。
当前挑战
该数据集致力于应对桑戈语机器翻译与语言建模的领域挑战,其核心在于克服低资源语言中平行语料稀缺、语言表征学习困难以及跨语言迁移效率低下等问题。在构建过程中,研究者面临多重实际障碍:数据集规模仅包含 431 个词汇条目和 360 个翻译对,难以满足现代自然语言处理模型的数据需求;从语法书籍中提取的翻译对存在文本碎片化现象,需经过滤才能用于模型训练;此外,桑戈语的地域变体覆盖有限,语音标注采用英语近似的音标系统,这些因素均对数据的代表性与准确性构成制约。
常用场景
经典使用场景
在低资源语言的自然语言处理领域,Sango Vocabulary Dataset为桑戈语这一中非共和国官方语言提供了首个结构化的数字词汇资源。该数据集最经典的使用场景在于机器翻译任务,特别是桑戈语与法语、英语之间的双向翻译。研究者可利用其431条三语词汇条目和360条翻译对,构建基础的翻译模型,或作为评估基准来测试跨语言迁移学习的效果。数据集涵盖问候、自然、职业等25个语义类别,为模型提供了丰富的语境信息,有助于在资源匮乏条件下提升翻译的准确性和鲁棒性。
衍生相关工作
围绕该数据集,已衍生出若干旨在扩展桑戈语数字生态的经典工作。例如,SangoAI项目以此数据集为种子,进一步开发了包含更多词汇的API,共同构成了更全面的桑戈语处理平台。在研究方法上,它激励了针对低资源非洲语言的少样本翻译模型构建、基于跨语言词嵌入的知识迁移,以及利用有限监督数据进行语言模型微调等方向的技术探索。这些工作不仅深化了对克里奥尔语计算处理的理解,也为其他面临类似资源困境的语言社群提供了可复用的技术框架和资源建设范式。
数据集最近研究
最新研究方向
在低资源语言处理领域,桑戈语作为中非共和国的国家语言,长期面临数字资源匮乏的困境。该数据集的出现为桑戈语的自然语言处理研究提供了首个结构化词汇资源,推动了跨语言迁移学习的前沿探索。研究者正利用其三语对齐特性,探索通过法语和英语的丰富表示来增强桑戈语的语言模型性能,特别是在机器翻译和文本分类任务中。这一工作与全球语言多样性保护的热点议题紧密相连,为非洲低资源语言的数字化保存提供了技术范式,对促进语言公平和文化遗产传承具有深远意义。
以上内容由遇见数据集搜集并总结生成


